 忧郁的大能猫
忧郁的大能猫
好奇的探索者,理性的思考者,踏实的行动者。
blog/A-IT/00-CS基础/70-network/协议/tcp
Table of Contents:
原理图
TCP三次握手、四次挥手时序图
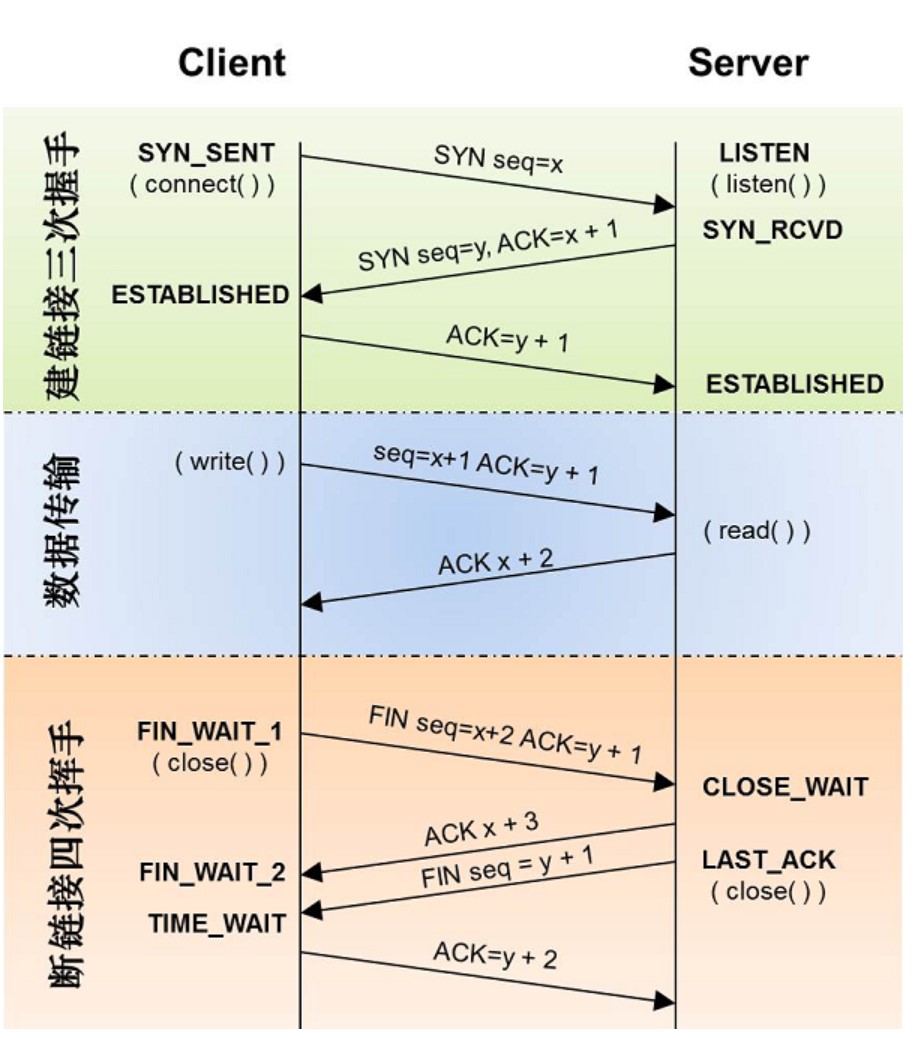
TCP协议状态机
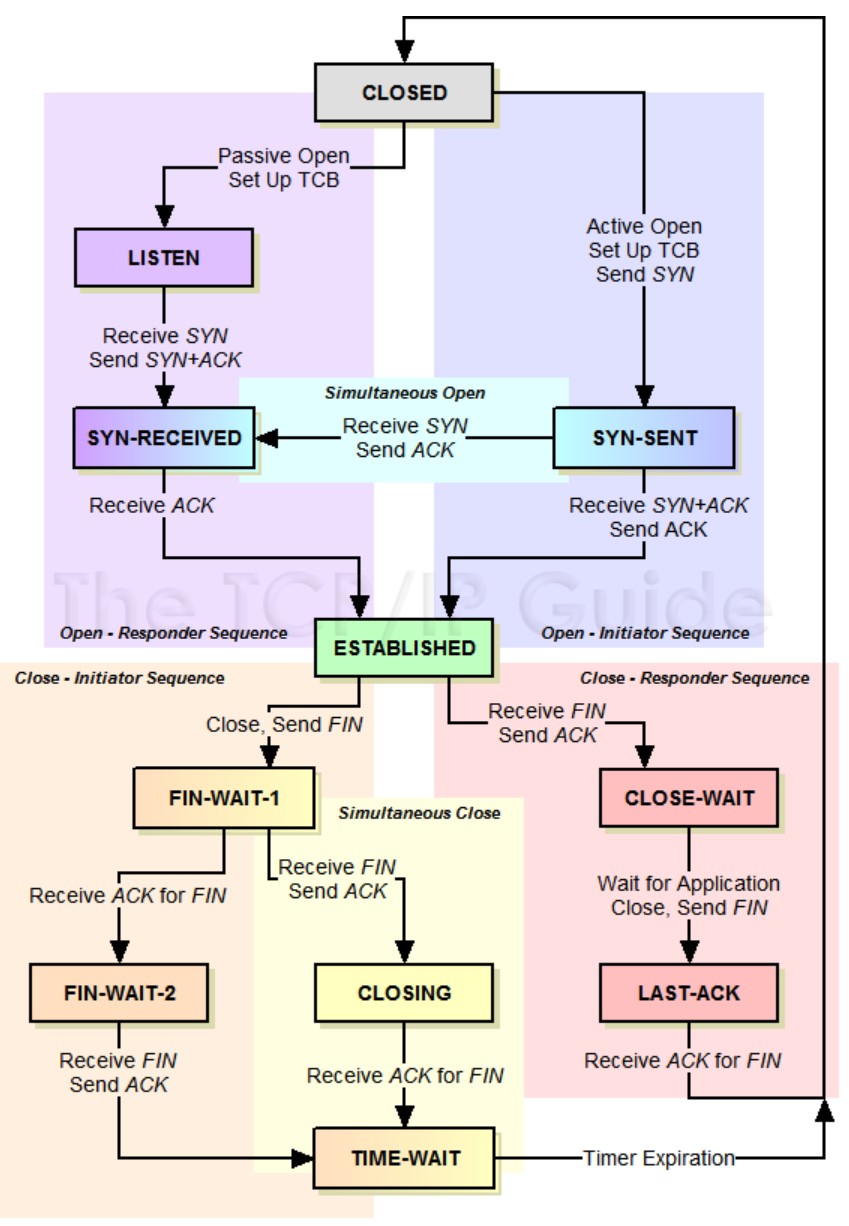
建立连接
三次握手
欲弄清TCP建立连接过程,须知道建立连接的目标是什么
* 分配资源
* 初始化序列号(通知Peer对端我的初始序列号是多少)
要达成这个目标需要进行以下的交互
1. Client端首先发送一个SYN包告诉Server端我的初始序列号是X;
2. Server端收到SYN包后回复给Client一个ACK确认包,告诉Client说我收到了;同时接着Server端也需要告诉Client端自己的初始序列号,于是Server也发送一个SYN包告诉Client我的初始序列号是Y;
3. Client收到后,回复Server一个ACK确认包说我知道了。
TCP连接的初始化序列号能否固定
不能,为了防止不同的连接相互干扰。
如果初始化序列号(缩写为ISN:Inital Sequence Number)可以固定,我们来看看会出现什么问题。假设ISN固定是1,Client和Server建立好一条TCP连接后,Client连续给Server发了10个包,这10个包不知怎么被链路上的路由器缓存了(路由器会毫无先兆地缓存或者丢弃任何的数据包),这个时候碰巧Client挂掉了,然后Client用同样的端口号重新连上Server,Client又连续给Server发了几个包,假设这个时候Client的序列号变成了5。接着,之前被路由器缓存的10个数据包全部被路由到Server端了,Server给Client回复确认号10,这个时候,Client整个都不好了,这是什么情况?我的序列号才到5,你怎么给我的确认号是10了,整个都乱了。
RFC793中,建议ISN和一个假的时钟绑在一起,这个时钟会在每4微秒对ISN做加一操作,直到超过2^32,又从0开始,这需要4小时才会产生ISN的回绕问题,这几乎可以保证每个新连接的ISN不会和旧连接的ISN产生冲突。这种递增方式的ISN,很容易让攻击者猜测到TCP连接的ISN,现在的实现大多是在一个基准值的基础上随机进行的。
初始化连接的SYN超时问题
Client发送SYN包给Server后挂了,Server回给Client的SYN-ACK一直没收到Client的ACK确认,此时这个连接既没建立起来,也不能算失败。这就需要一个超时时间让Server将这个连接断开,否则这个连接就会一直占用Server的SYN连接队列中的一个位置,大量这样的连接就会将Server的SYN连接队列耗尽,让正常的连接无法得到处理。目前,Linux下默认会进行5次重发SYN-ACK包,重试的间隔时间从1s开始,下次的重试间隔时间是前一次的双倍,5次的重试时间间隔为1s,2s,4s,8s,16s,总共31s,第5次发出后还要等32s都知道第5次也超时了,所以,总共需要 1s + 2s + 4s+ 8s+ 16s + 32s = 63s,TCP才会断开这个连接。由于,SYN超时需要63秒,那么就给攻击者一个攻击服务器的机会,攻击者在短时间内发送大量的SYN包给Server(俗称SYN flood攻击),用于耗尽Server的SYN队列。对于应对SYN过多的问题,Linux提供了几个TCP参数:tcp_syncookies、tcp_synack_retries、tcp_max_syn_backlog、tcp_abort_on_overflow来调整应对。
断开连接
四次挥手
断开连接的目的:
* 回收资源
* 终止数据传输
由于TCP是全双工的,需要Peer两端分别各自拆除自己通向Peer对端方向的通信信道,于是四次挥手的过程如下:
1. Client发送一个FIN包来告诉Server我已经没数据需要发给Server了;
2. Server收到后回复一个ACK确认包说我知道了;
3. 然后Server在自己也没数据发送给Client后,Server也发送一个FIN包给Client告诉Client我也已经没数据发给Client了;
4. Client收到后,就会回复一个ACK确认包说我知道了。
TCP的Peer两端同时断开连接
由上面的”TCP协议状态机 “图可以看出,TCP的Peer端在收到对端的FIN包前发出了FIN包,那么该Peer的状态就变成了FIN_WAIT1,Peer在FIN_WAIT1状态下收到对端Peer对自己FIN包的ACK包的话,那么Peer状态就变成FIN_WAIT2,Peer在FIN_WAIT2下收到对端Peer的FIN包,在确认已经收到了对端Peer全部的Data数据包后,就响应一个ACK给对端Peer,然后自己进入TIME_WAIT状态;但是如果Peer在FIN_WAIT1状态下首先收到对端Peer的FIN包的话,那么该Peer在确认已经收到了对端Peer全部的Data数据包后,就响应一个ACK给对端Peer,然后自己进入CLOSEING状态,Peer在CLOSEING状态下收到自己FIN包的ACK包的话,那么就进入TIME WAIT状态。于是,TCP的Peer两端同时发起FIN包进行断开连接,那么两端Peer可能出现完全一样的状态转移FIN_WAIT1---->CLOSEING----->TIME_WAIT,Client和Server也就会最后同时进入TIME_WAIT状态。同时关闭连接的状态转移如下图所示:
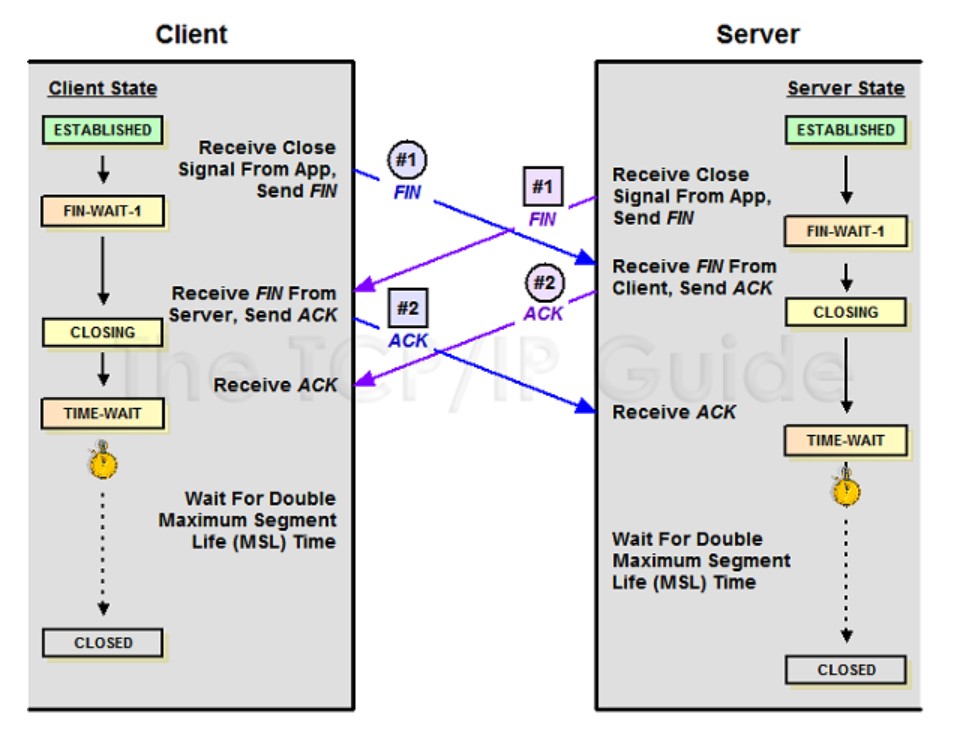
四次挥手能否变成三次挥手?
答案是可能的。TCP是全双工通信,Cliet在自己已经不会再有新的数据要发送给Server后,可以发送FIN信号告知Server,这边已经终止Client到对端Server的数据传输。但是,这个时候对端Server可以继续往Client这边发送数据包。于是,两端数据传输的终止在时序上独立并且可能会相隔比较长的时间,这个时候就必须最少需要2+2=4次挥手来完全终止这个连接。但是,如果Server在收到Client的FIN包后,再也没数据需要发送给Client了,那么对Client的ACK包和Server自己的FIN包就可以合并成一个包发送过去,这样四次挥手就可以变成三次了(似乎Linux协议栈就是这样实现的)。
TCP的头号疼症TIME_WAIT状态
怎么进入TIME_WAIT状态?
主动关闭连接的一方在收到对端的FIN包后后进入
TIME_WAIT状态是用来解决或避免什么问题呢?
1. 主动关闭方需要进入TIME_WAIT以便能够重发丢掉的被动关闭方FIN包的ACK。如果主动关闭方不进入TIME_WAIT,那么在主动关闭方对被动关闭方FIN包的ACK丢失了的时候,被动关闭方由于没收到自己FIN的ACK,会进行重传FIN包,这个FIN包到主动关闭方后,由于这个连接已经不存在于主动关闭方了,这个时候主动关闭方无法识别这个FIN包,协议栈会认为对方疯了,都还没建立连接你给我来个FIN包?于是回复一个RST包给被动关闭方,被动关闭方就会收到一个错误(我们见的比较多的:connect reset by peer。这里顺便说下Broken pipe,在收到RST包的时候,还往这个连接写数据,就会收到Broken pipe错误了),原本应该正常关闭的连接,给我来个错误,很难让人接受。
2. 防止已经断开的连接1中在链路中残留的FIN包终止掉新的连接2[重用了连接1的所有5元素(源IP,目的IP,TCP,源端口,目的端口)],这个概率比较低,因为涉及到一个匹配问题,迟到的FIN分段的序列号必须落在连接2一方的期望序列号范围之内,虽然概率低,但是确实可能发生,因为初始序列号都是随机产生的,并且这个序列号是32位的,会回绕。
3. 防止链路上已经关闭的连接的残余数据包(a lost duplicate packet or a wandering duplicate packet)干扰正常的数据包,造成数据流不正常。这个问题和(2)类似。
TIME_WAIT会带来哪些问题?
一个连接进入TIME_WAIT状态后需要等待2*MSL(一般是1到4分钟)那么长的时间才能断开连接释放连接占用的资源,会造成以下问题:
1. 作为服务器,短时间内关闭了大量的Client连接,就会造成服务器上出现大量的TIME_WAIT连接,占据大量的tuple,严重消耗着服务器的资源;
2. 作为客户端,短时间内大量的短连接,会大量消耗Client机器的端口,毕竟端口只有65535个,端口被耗尽了,后续就无法再发起新的连接了。
MSL(Maximum Segment Lifetime,报文最大生存时间)
TIME_WAIT的快速回收和重用
(1) TIME_WAIT快速回收
Linux下开启TIME_WAIT快速回收需要同时打开tcp_tw_recycle和tcp_timestamps(默认打开)两选项。Linux下快速回收的时间为3.5*RTO(Retransmission Timeout),而一个RTO时间为200ms至120s。开启快速回收TIME_WAIT,可能会带来问题一中说的三点危险,为了避免这些危险,要求同时满足以下三种情况的新连接被拒绝掉。
(2) TIME_WAIT重用
要同时开启tcp_tw_reuse选项和tcp_timestamps选项才可以开启TIME_WAIT重用,还有一个条件是:重用TIME_WAIT的条件是收到最后一个包后超过1s。