 忧郁的大能猫
忧郁的大能猫
好奇的探索者,理性的思考者,踏实的行动者。
blog/A-IT/00-CS基础/10-组成原理&体系结构/深入浅出计算机组成原理-5应用篇
Table of Contents:
52 | 设计大型DMP系统(上):MongoDB并不是什么灵丹妙药
DMP:数据管理平台
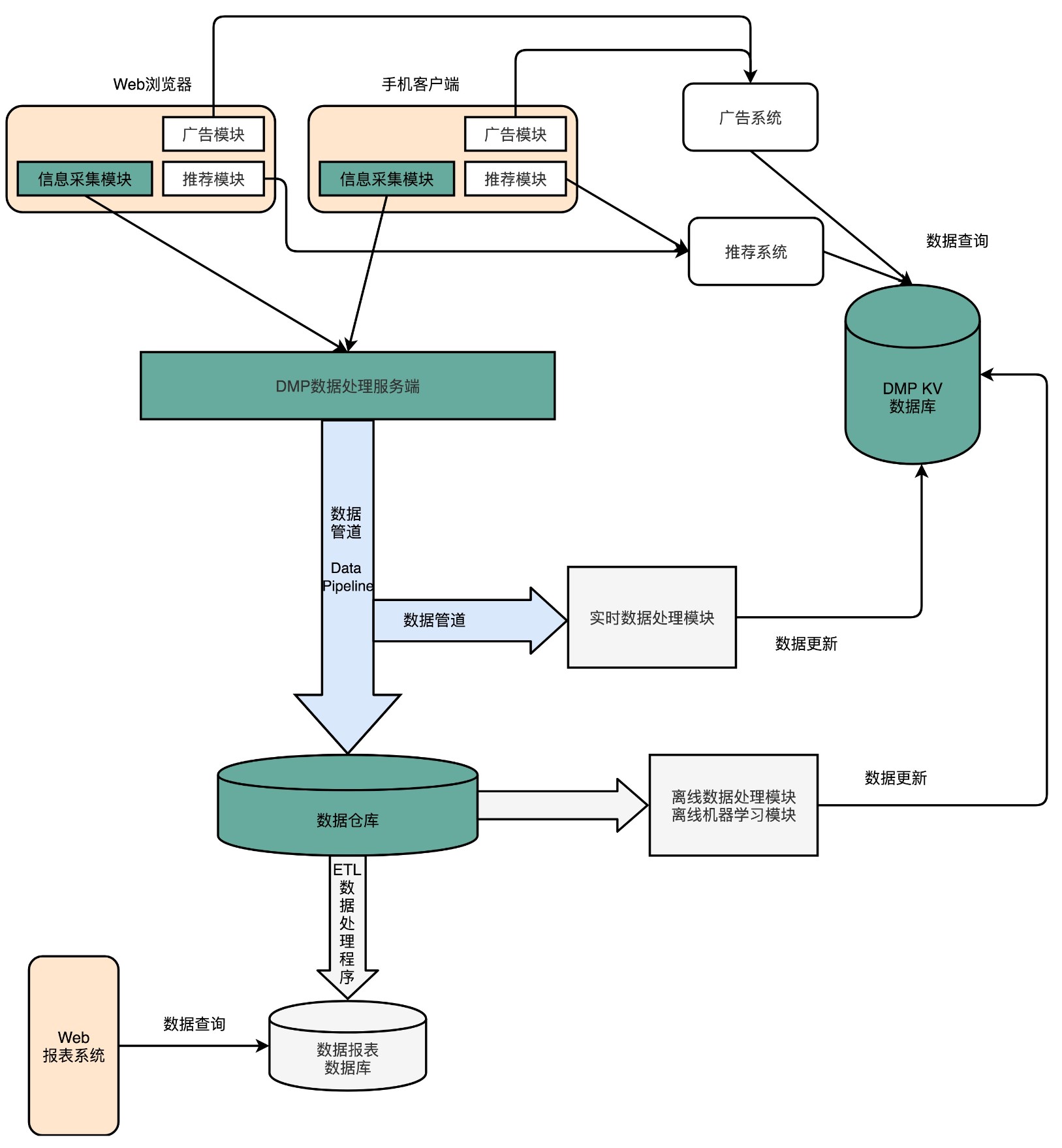
DMP 系统的全称叫作数据管理平台(Data Management Platform),目前广泛应用在互联网的广告定向(Ad Targeting)、个性化推荐(Recommendation)这些领域。
通常来说,DMP 系统会通过处理海量的互联网访问数据以及机器学习算法,给一个用户标注上各种各样的标签。然后,在我们做个性化推荐和广告投放的时候,再利用这些这些标签,去做实际的广告排序、推荐等工作。无论是 Google 的搜索广告、淘宝里千人千面的商品信息,还是抖音里面的信息流推荐,背后都会有一个 DMP 系统。

那么,一个 DMP 系统应该怎么搭建呢?对于外部使用 DMP 的系统或者用户来说,可以简单地把 DMP 看成是一个键 - 值对(Key-Value)数据库。我们的广告系统或者推荐系统,可以通过一个客户端输入用户的唯一标识(ID),然后拿到这个用户的各种信息。
MongoDB 真的万能吗?
总结延伸
好了,相信到这里,你应该对怎么从最基本的原理出发,来选择技术栈有些感觉了。你应该更多地从底层的存储系统的特性和原理去考虑问题。一旦能够从这个角度去考虑问题,那么你对各类新的技术项目和产品的公关稿,自然会有一定的免疫力了,而不会轻易根据商业公司的宣传来做技术选型了。
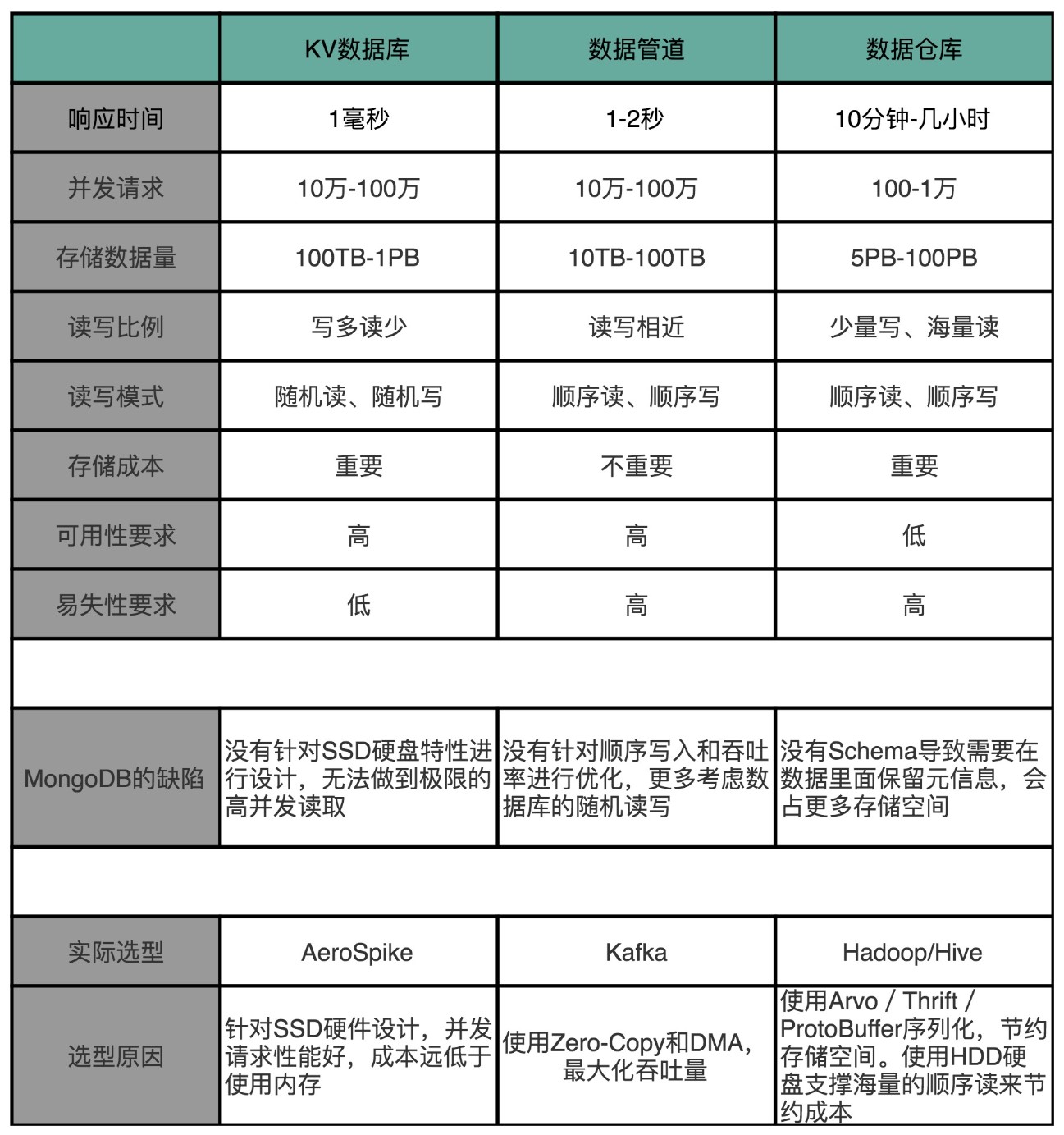
因为低延时、高并发、写少读多的 DMP 的 KV 数据库,最适合用 SSD 硬盘,并且采用专门的 KV 数据库是最合适的。我们可以选择之前文章里提过的 AeroSpike,也可以用开源的 Cassandra 来提供服务。
对于数据管道,因为主要是顺序读和顺序写,所以我们不一定要选用 SSD 硬盘,而可以用 HDD 硬盘。不过,对于最大化吞吐量的需求,使用 zero-copy 和 DMA 是必不可少的,所以现在的数据管道的标准解决方案就是 Kafka 了。
对于数据仓库,我们通常是一次写入、多次读取。并且,由于存储的数据量很大,我们还要考虑成本问题。于是,一方面,我们会用 HDD 硬盘而不是 SSD 硬盘;另一方面,我们往往会预先给数据规定好 Schema,使得单条数据的序列化,不需要像存 JSON 或者 MongoDB 的 BSON 那样,存储冗余的字段名称这样的元数据。所以,最常用的解决方案是,用 Hadoop 这样的集群,采用 Hive 这样的数据仓库系统,或者采用 Avro/Thrift/ProtoBuffer 这样的二进制序列化方案。
在大型的 DMP 系统设计当中,我们需要根据各个应用场景面临的实际情况,选择不同的硬件和软件的组合,来作为整个系统中的不同组件。
53 | 设计大型DMP系统(下):SSD拯救了所有的DBA
关系型数据库:不得不做的随机读写
在这样一个数据模型下,查询操作很灵活。无论是根据哪个字段查询,只要有索引,我们就可以通过一次随机读,很快地读到对应的数据。但是,这个灵活性也带来了一个很大的问题,那就是无论干点什么,都有大量的随机读写请求。而随机读写请求,如果请求最终是要落到硬盘上,特别是 HDD 硬盘的话,我们就很难做到高并发了。毕竟 HDD 硬盘只有 100 左右的 QPS。
传统的关系型数据库,我们把一条条数据存放在一个地方,同时再把索引存放在另外一个地方。这样的存储方式,其实很方便我们进行单次的随机读和随机写,数据的存储也可以很紧凑。但是问题也在于此,大部分的 SQL 请求,都会带来大量的随机读写的请求。这使得传统的关系型数据库,其实并不适合用在真的高并发的场景下。
Cassandra:顺序写和随机读
1.Cassandra 的写操作
Cassandra 只有顺序写入,没有随机写入

Cassandra 解决随机写入数据的解决方案,简单来说,就叫作“不随机写,只顺序写”。对于 Cassandra 数据库的写操作,通常包含两个动作。第一个是往磁盘上写入一条提交日志(Commit Log)。另一个操作,则是直接在内存的数据结构上去更新数据。后面这个往内存的数据结构里面的数据更新,只有在提交日志写成功之后才会进行。每台机器上,都有一个可靠的硬盘可以让我们去写入提交日志。写入提交日志都是顺序写(Sequential Write),而不是随机写(Random Write),这使得我们最大化了写入的吞吐量。
内存的空间比较有限,一旦内存里面的数据量或者条目超过一定的限额,Cassandra 就会把内存里面的数据结构 dump 到硬盘上。这个 Dump 的操作,也是顺序写而不是随机写,所以性能也不会是一个问题。除了 Dump 的数据结构文件,Cassandra 还会根据 row key 来生成一个索引文件,方便后续基于索引来进行快速查询。
随着硬盘上的 Dump 出来的文件越来越多,Cassandra 会在后台进行文件的对比合并。在很多别的 KV 数据库系统里面,也有类似这种的合并动作,比如 AeroSpike 或者 Google 的 BigTable。这些操作我们一般称之为 Compaction。合并动作同样是顺序读取多个文件,在内存里面合并完成,再 Dump 出来一个新的文件。整个操作过程中,在硬盘层面仍然是顺序读写。
2.Cassandra 的读操作
Cassandra 的读请求,会通过缓存、BloomFilter 进行两道过滤,尽可能避免数据请求命中硬盘
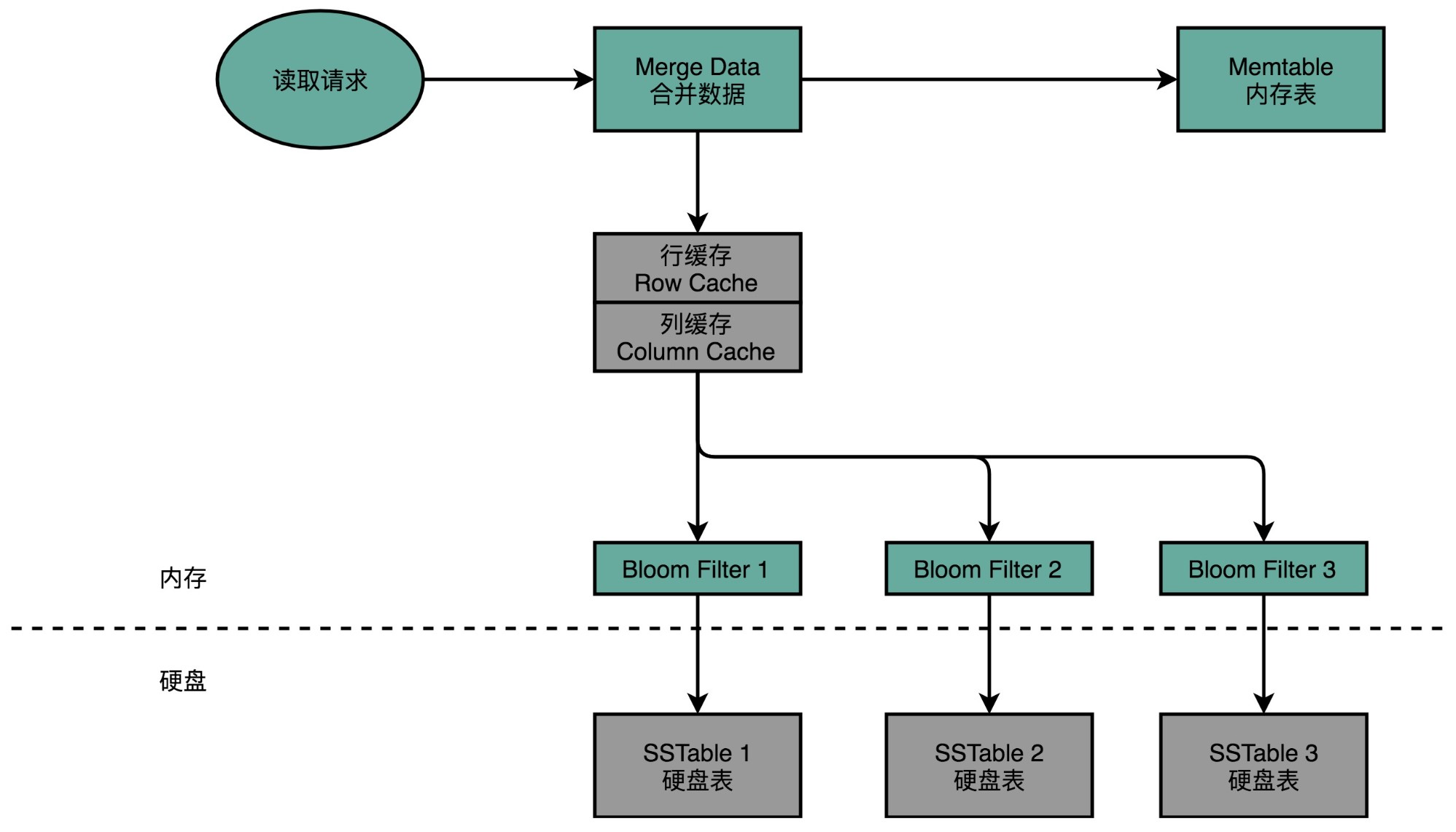
当我们要从 Cassandra 读数据的时候,会从内存里面找数据,再从硬盘读数据,然后把两部分的数据合并成最终结果。这些硬盘上的文件,在内存里面会有对应的 Cache,只有在 Cache 里面找不到,我们才会去请求硬盘里面的数据。
如果不得不访问硬盘,因为硬盘里面可能 Dump 了很多个不同时间点的内存数据的快照。所以,找数据的时候,我们也是按照时间从新的往旧的里面找。
这也就带来另外一个问题,我们可能要查询很多个 Dump 文件,才能找到我们想要的数据。所以,Cassandra 在这一点上又做了一个优化。那就是,它会为每一个 Dump 的文件里面所有 Row Key 生成一个 BloomFilter,然后把这个 BloomFilter 放在内存里面。这样,如果想要查询的 Row Key 在数据文件里面不存在,那么 99% 以上的情况下,它会被 BloomFilter 过滤掉,而不需要访问硬盘。
这样,只有当数据在内存里面没有,并且在硬盘的某个特定文件上的时候,才会触发一次对于硬盘的读请求。
SSD:DBA 们的大救星
回到我们看到的 Cassandra 的读写设计,你会发现,Cassandra 的写入机制完美匹配了我们在第 46 和 47 讲所说的 SSD 硬盘的优缺点。
在数据写入层面,Cassandra 的数据写入都是 Commit Log 的顺序写入,也就是不断地在硬盘上往后追加内容,而不是去修改现有的文件内容。一旦内存里面的数据超过一定的阈值,Cassandra 又会完整地 Dump 一个新文件到文件系统上。这同样是一个追加写入。
数据的对比和紧凑化(Compaction),同样是读取现有的多个文件,然后写一个新的文件出来。写入操作只追加不修改的特性,正好天然地符合 SSD 硬盘只能按块进行擦除写入的操作。在这样的写入模式下,Cassandra 用到的 SSD 硬盘,不需要频繁地进行后台的 Compaction,能够最大化 SSD 硬盘的使用寿命。这也是为什么,Cassandra 在 SSD 硬盘普及之后,能够获得进一步快速发展。
54 | 理解Disruptor(上):带你体会CPU高速缓存的风驰电掣
Disruptor是英国外汇交易公司LMAX开发的一个高性能队列,研发的初衷是解决内存队列的延迟问题。与Kafka、RabbitMQ用于服务间的消息队列不同,disruptor一般用于线程间消息的传递。基于Disruptor开发的系统单线程能支撑每秒600万订单。
总结延伸
CPU 从内存加载数据到 CPU Cache 里面的时候,不是一个变量一个变量加载的,而是加载固定长度的 Cache Line。如果是加载数组里面的数据,那么 CPU 就会加载到数组里面连续的多个数据。所以,数组的遍历很容易享受到 CPU Cache 那风驰电掣的速度带来的红利。
对于类里面定义的单独的变量,就不容易享受到 CPU Cache 红利了。因为这些字段虽然在内存层面会分配到一起,但是实际应用的时候往往没有什么关联。于是,就会出现多个 CPU Core 访问的情况下,数据频繁在 CPU Cache 和内存里面来来回回的情况。而 Disruptor 很取巧地在需要频繁高速访问的常量 INITIAL_CURSOR_VALUE 前后,各定义了 7 个没有任何作用和读写请求的 long 类型的变量。
这样,无论在内存的什么位置上,这个 INITIAL_CURSOR_VALUE 所在的 Cache Line 都不会有任何写更新的请求。我们就可以始终在 Cache Line 里面读到它的值,而不需要从内存里面去读取数据,也就大大加速了 Disruptor 的性能。
这样的思路,其实渗透在 Disruptor 这个开源框架的方方面面。作为一个生产者 - 消费者模型,Disruptor 并没有选择使用链表来实现一个队列,而是使用了 RingBuffer。RingBuffer 底层的数据结构则是一个固定长度的数组。这个数组不仅让我们更容易用好 CPU Cache,对 CPU 执行过程中的分支预测也非常有利。更准确的分支预测,可以使得我们更好地利用好 CPU 的流水线,让代码跑得更快。
55 | 理解Disruptor(下):不需要换挡和踩刹车的CPU,有多快?
利用 CPU 高速缓存,只是 Disruptor“快”的一个因素,那今天我们就来看一看 Disruptor 快的另一个因素,也就是“无锁”,而尽可能发挥 CPU 本身的高速处理性能。
缓慢的锁
Disruptor 作为一个高性能的生产者 - 消费者队列系统,一个核心的设计就是通过 RingBuffer 实现一个无锁队列。
Java 基础库里面的 BlockingQueue,都需要通过显示地加锁来保障生产者之间、消费者之间,乃至生产者和消费者之间,不会发生锁冲突的问题。
但是,加锁会大大拖慢我们的性能。在获取锁过程中,CPU 没有去执行计算的相关指令,而要等待操作系统进行锁竞争的裁决。而那些没有拿到锁而被挂起等待的线程,则需要进行上下文切换。这个上下文切换,会把挂起线程的寄存器里的数据放到线程的程序栈里面去。这也意味着,加载到高速缓存里面的数据也失效了,程序就变得更慢了。
无锁的 RingBuffer
Disruptor 里的 RingBuffer 采用了一个无锁的解决方案,通过 CAS 这样的操作,去进行序号的自增和对比,使得 CPU 不需要获取操作系统的锁。而是能够继续顺序地执行 CPU 指令。没有上下文切换、没有操作系统锁,自然程序就跑得快了。不过因为采用了 CAS 这样的忙等待(Busy-Wait)的方式,会使得我们的 CPU 始终满负荷运转,消耗更多的电,算是一个小小的缺点。
程序里面的 CAS 调用,映射到我们的 CPU 硬件层面,就是一个机器指令,这个指令就是 cmpxchg。可以看到,当想要追求最极致的性能的时候,我们会从应用层、贯穿到操作系统,乃至最后的 CPU 硬件,搞清楚从高级语言到系统调用,乃至最后的汇编指令,这整个过程是怎么执行代码的。而这个,也是学习组成原理这门专栏的意义所在。
FAQ
Q4:编程语言的自举是什么
编程语言是自举的,指的是说,我们能用自己写出来的程序编译自己。但是自举,并不要求这门语言的第一个编译器就是用自己写的。
比如,这里说到的 Go,先是有了 Go 语言,我们通过 C++ 写了编译器 A。然后呢,我们就可以用这个编译器 A,来编译 Go 语言的程序。接着,我们再用 Go 语言写一个编译器程序 B,然后用 A 去编译 B,就得到了 Go 语言写好的编译器的可执行文件了。
这个之后,我们就可以一直用 B 来编译未来的 Go 语言程序,这也就实现了所谓的自举了。所以,即使是自举,也通常是先有了别的语言写好的编译器,然后再用自己来写自己语言的编译器。
Q5:不同指令集中,汇编语言和机器码的关系怎么对应的?
“汇编语言”其实可以理解成“机器码”的一种别名或者书写方式,不同的指令集和体系结构的机器会有不同的“机器码”。
编译器如果支持编译成不同的体系结构的汇编 / 机器码,就要维护很多不同的对应关系表,但是这个表并不会太大。以最复杂的 Intel X86 的指令集为例,也只有 2000 条不同的指令而已。