 忧郁的大能猫
忧郁的大能猫
好奇的探索者,理性的思考者,踏实的行动者。
blog/A-IT/00-CS基础/30-编译原理/llvm
Table of Contents:
介绍
llvm是low level virtual machine的简称,其实是一个编译器框架。llvm随着这个项目的不断的发展,已经无法完全的代表这个项目了
LLVM是当今最流行的开源编译器框架项目,你可以使用它编写自己的编译器。
llvm的主要作用是它可以作为多种语言的后端,它可以提供可编程语言无关的优化和针对很多种CPU的代码生成功能。
此外llvm目前已经不仅仅是个编程框架,它目前还包含了很多的子项目,比如最具盛名的clang.
LLVM的命名最早源自于底层虚拟机(Low Level Virtual Machine)的首字母缩写,由于这个项目的范围并不局限于创建一个虚拟机,这个缩写导致了广泛的疑惑。LLVM开始成长之后,成为众多编译工具及低端工具技术的统称,使得这个名字变得更不贴切,开发者因而决定放弃这个缩写的意涵,现今LLVM已单纯成为一个品牌,适用于LLVM下的所有项目
LLVM的含义
在不同的语义环境下,LLVM具有以下几种不同的含义:
* LLVM基础架构:即一个完整编译器项目的集合,包括但不限于前端、后端、优化器、汇编器、链接器、libc++标准库、Compiler-RT和JIT引擎
* 基于LLVM构建的编译器:部分或完全使用LLVM构建的编译器
* LLVM库:LLVM基础架构可重用代码部分
* LLVM核心:在LLVM IR上进行的优化和后端算法
* LLVM IR:LLVM中间表示
llvm相关工具
- llvm-as 将人类可读的 .ll 文件汇编成字节代码
- llvm-dis 将字节代码文件反编成人类可读的 .ll 文件
- opt 在一个字节代码文件上运行一系列的 LLVM 到 LLVM 的优化
- llc 为一个字节代码文件生成本机器代码
- lli 直接运行使用 JIT 编译器或者解释器编译成字节代码的程序
- llvm-link 将几个字节代码文件连接成一个
- llvm-ar 打包字节代码文件
- llvm-ranlib 为 llvm-ar 打包的文件创建索引
- llvm-nm 在 打印出LLVM中间格式或者object文件的符号表(2014年5月14日更新)
- llvm-prof 将 'llvmprof.out' raw 数据格式化成人类可读的报告
- llvm-ld 带有可装载的运行时优化支持的通用目标连接器
- llvm-config 打印出配置时 LLVM 编译选项、库、等等
- llvmc 一个通用的可定制的编译器驱动
- llvm-diff 比较两个模块的结构
- bugpoint 自动案例测试减速器
- llvm-extract 从 LLVM 字节代码文件中解压出一个函数
- llvm-bcanalyzer 字节代码分析器 (分析二进制编码本身,而不是它代表的程序)
- FileCheck 灵活的文件验证器,广泛的被测试工具利用
- tblgen 目标描述阅读器和生成器
- lit LLVM 集成测试器,用于运行测试
- AddressSanitizer 一个快速内存错误探测器
Clang和LLVM关系
Clang是一个C++编写、基于LLVM、发布于LLVM BSD许可证下的C/C++/Objective-C/Objective-C++编译器。
那么为什么已经有了GCC还要开发Clang呢?Clang相比于GCC有什么优势呢?其实,这也是Clang当初在设计开发的时候所主要考虑的原因。Clang是一个高度模块化开发的轻量级编译器,它的编译速度快、占用内存小、非常方便进行二次开发。
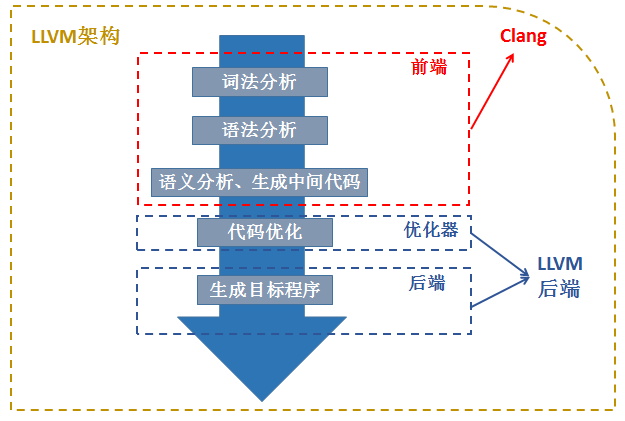
对应到这个图中,我们就可以非常明确的找出它们的对应关系。LLVM与Clang是C/C++编译器套件。对于整个LLVM的框架来说,包含了Clang,因为Clang是LLVM的框架的一部分,是它的一个C/C++的前端。从源代码角度来讲,clang是基于LLVM的一个工具。而功能的角度来说,LLVM可以认为是一个编译器的后端,而clang是一个编译器的前端,他们的关系更加的明了,一个编译器前端想要程序最终变成可执行文件,是缺少不了对编译器后端的介绍的。
LLVM IR
传统的静态编译器分为三个阶段:前端(Frontend)-- 优化器(Optimizer)-- 后端(Backend)
而大名鼎鼎的GCC编译器在设计的时候没有做好层次划分,导致很多数据在前端和后端耦合在了一起,所以GCC支持一种新的编程语言或新的目标架构特别困难。
有了GCC的前车之鉴,LLVM进行了如下图所示的三阶段设计
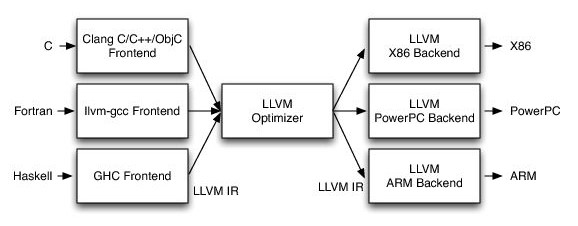
* 前端可以使用不同的编译工具对代码文件做词法分析以形成抽象语法树AST,然后将分析好的代码转换成LLVM的中间表示IR(intermediate representation);
* 中间部分的优化器只对中间表示IR操作,通过一系列的pass对IR做优化;
* 后端负责将优化好的IR解释成对应平台的机器码。
LLVM的优点在于,中间表示IR代码编写良好,而且不同的前端语言最终都转换成同一种的IR。
这样支持一种新的编程语言只需重新实现一个前端
支持一种新的目标架构只需重新实现一个后端
前端和后端连接枢纽就是LLVM IR
为什么使用三段式设计?优势在哪里?首先解决一个很大的问题:假如有N种语言(C、OC、C++、Swift...)的前端,同时也有M个架构(模拟器、arm64、x86...)的target,是否就需要N*M个编译器?三段式架构的价值就提现出来了,通过共享优化器的中转,很好的解决了这个问题。
LLVM IR本质上一种与源编程语言和目标机器架构无关的通用中间表示,是LLVM项目的核心设计和最大的优势。
LLVM IR是一种类似于RISC的低级虚拟指令集
LLVM IR编程基本流程
1.创建一个Module
2.在Module中添加Function
3.在Function中添加BasicBlock
4.在BasicBlock中添加指令
5.创建一个 ExecutionEngine
6.使用 ExecutionEngine 来运行IR
JIT
JIT可以分为两个阶段:1.在运行时生成机器码 2.在运行时执行机器码。
其中,第一个阶段的生成机器码方式与静态编译并无本质不同,只不过生成的机器码被保存在内存中,而静态编译是在程序运行前将整个程序完全编译为机器码保存在二进制文件中。
运行时JIT缓存编译后的机器码,当再次遇到该函数时,则直接从缓存中执行已编译好的机器。
因此,从理论上来说,JIT编译技术的性能会越来越接近静态编译技术。
JIT运行的简单原理
为了模拟JIT的运行原理,如下代码演示了如何在内存中动态生成add函数并执行,该函数的C语言原型如下:
long add4(long num) {
return num + 4;
}进行编译,然后看下反汇编代码
g++ f.cpp
objdump -S a.out
00000000004005b0 <_Z4add4l>:
4005b0: 55 push %rbp
4005b1: 48 89 e5 mov %rsp,%rbp
4005b4: 48 89 7d f8 mov %rdi,-0x8(%rbp)
4005b8: 48 8b 45 f8 mov -0x8(%rbp),%rax
4005bc: 48 83 c0 04 add $0x4,%rax
4005c0: 5d pop %rbp
4005c1: c3 retq然后在内存中动态地执行它:
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <sys/mman.h>
// Allocates RWX memory of given size and returns a pointer to it. On failure,
// prints out the error and returns NULL.
void* alloc_executable_memory(size_t size) {
void* ptr = mmap(0, size,
PROT_READ | PROT_WRITE | PROT_EXEC,
MAP_PRIVATE | MAP_ANONYMOUS, -1, 0);
if (ptr == (void*)-1) {
perror("mmap");
return NULL;
}
return ptr;
}
void emit_code_into_memory(unsigned char* m) {
unsigned char code[] = {
0x55, // push %rbp
0x48, 0x89, 0xe5, // mov %rsp,%rbp
0x48, 0x89, 0x7d, 0xf8, // mov %rdi,-0x8(%rbp)
0x48, 0x8b, 0x45, 0xf8, // mov -0x8(%rbp),%rax
0x48, 0x83, 0xc0, 0x04, // add $0x4,%rax
0x5d, // pop %rbp
0xc3 // retq
};
memcpy(m, code, sizeof(code));
}
const size_t SIZE = 1024;
typedef long (*JittedFunc)(long);
// Allocates RWX memory directly.
void run_from_rwx() {
void* m = alloc_executable_memory(SIZE);
emit_code_into_memory(reinterpret_cast<unsigned char*>(m));
JittedFunc func = reinterpret_cast<JittedFunc>(m); // function: 4+m
int result = func(3);
printf("result = %d\n", result);
}
int main() {
run_from_rwx();
return 0;
}此代码执行的主要3个步骤是:
1. 使用mmap在堆上分配可读,可写和可执行的内存块。
2. 将实现add4函数的汇编/机器代码复制到此内存块中。
3. 将该内存块首地址转换为函数指针,并通过调用这一函数指针来执行此内存块中的代码。
请注意,步骤3能发生是因为包含机器代码的内存块是可执行的,如果没有设置正确的权限,该调用将导致OS的运行时错误(很可能是segmentation fault)。如果我们通过对malloc的常规调用来分配内存块,则会发生这种情况,malloc分配可读写但不可执行的内存。而通过mmap来分配内存块,则可以自行设置该内存块的属性。
上面示例的代码有一个问题,它有安全漏洞。原因是RWX(可读可写可执行)的内存块,是易受攻击和利用的天堂。
可以分配的时候赋予RW权限,将机器码写入内存,执行之前使用mprotect将内存块的权限从RW修改RX,可执行但不能写入。
代码如下:
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <sys/mman.h>
const size_t SIZE = 1024;
typedef long (*JittedFunc)(long);
// Allocates RW memory of given size and returns a pointer to it. On failure,
// prints out the error and returns NULL. Unlike malloc, the memory is allocated
// on a page boundary so it's suitable for calling mprotect.
void* alloc_writable_memory(size_t size) {
void* ptr = mmap(0, size,
PROT_READ | PROT_WRITE,
MAP_PRIVATE | MAP_ANONYMOUS, -1, 0);
if (ptr == (void*)-1) {
perror("mmap");
return NULL;
}
return ptr;
}
// Allocates RWX memory of given size and returns a pointer to it. On failure,
// prints out the error and returns NULL.
void* alloc_executable_memory(size_t size) {
void* ptr = mmap(0, size,
PROT_READ | PROT_WRITE | PROT_EXEC,
MAP_PRIVATE | MAP_ANONYMOUS, -1, 0);
if (ptr == (void*)-1) {
perror("mmap");
return NULL;
}
return ptr;
}
void emit_code_into_memory(unsigned char* m) {
unsigned char code[] = {
0x55, // push %rbp
0x48, 0x89, 0xe5, // mov %rsp,%rbp
0x48, 0x89, 0x7d, 0xf8, // mov %rdi,-0x8(%rbp)
0x48, 0x8b, 0x45, 0xf8, // mov -0x8(%rbp),%rax
0x48, 0x83, 0xc0, 0x04, // add $0x4,%rax
0x5d, // pop %rbp
0xc3 // retq
};
memcpy(m, code, sizeof(code));
}
// Sets a RX permission on the given memory, which must be page-aligned. Returns
// 0 on success. On failure, prints out the error and returns -1.
int make_memory_executable(void* m, size_t size) {
if (mprotect(m, size, PROT_READ | PROT_EXEC) == -1) {
perror("mprotect");
return -1;
}
return 0;
}
// Allocates RW memory, emits the code into it and sets it to RX before
// executing.
void emit_to_rw_run_from_rx() {
void* m = alloc_writable_memory(SIZE);
emit_code_into_memory(reinterpret_cast<unsigned char*>(m));
make_memory_executable(m, SIZE);
JittedFunc func = reinterpret_cast<JittedFunc>(m); // function : 4+m
int result = func(2);
printf("result = %d\n", result);
}
int main() {
emit_to_rw_run_from_rx();
return 0;
}LLVM执行引擎(LLVM Execution Engine)
LLVM JIT使用执行引擎(execution engine)来支持LLVM模块的执行。ExecutionEngine类的申明在
执行引擎负责管理整个客体(guest)程序的执行,分析需要执行的下一个程序片段。客体程序是指不能被硬件平台原生支持的代码,比如,对于x86平台来说,LLVM IR模块就是客体程序,因为x86平台不能直接执行LLVM IR代码。
在LLVM中有三个持续演进的JIT执行引擎实现:llvm::JIT类、llvm::MCJIT类和llvm::ORCJIT类,
llvm::JIT类在新的LLVM已经不再支持。JIT客户端会首先产生一个ExecutionEngine对象。
ExecutionEngine对象以IR模块为输入,通过调用ExecutionEngine::EngineBuilder()初始化。
接下来,ExecutionEngine::create()方法生成一个JIT或MCJIT引擎实例。
MCJIT是ExecutionEngine的子类
内存管理
JIT引擎的ExecutionManager类调用LLVM代码生成器,产生目标平台机器指令的二进制代码保存在内存中,并返回指向编译后函数的指针。然后通过函数指针指向指令所在内存区域即可执行该函数。在此过程中,内存管理负责执行内存分配、释放、权限处理、库加载空间分配等操作。
JIT和MCJIT各自实现派生自RTDyldMemoryManager基类的定制内存管理类。执行引擎客户端也可以定制RTDyldMemoryManager子类,由该子类指定JIT部件在内存中的存放位置。RTDyldMemoryManager定义在
JIT和MCJIT的缺省内存管理子类分别是JITMemoryManager和SectionMemoryManager。