 忧郁的大能猫
忧郁的大能猫
好奇的探索者,理性的思考者,踏实的行动者。
blog/A-IT/00-CS基础/30-编译原理/编译原理之美
Table of Contents:
- 开篇词 | 为什么你要学习编译原理?
- 01 | 理解代码:编译器的前端技术
- 02 | 正则文法和有限自动机:纯手工打造词法分析器
- 03 | 语法分析(一):纯手工打造公式计算器
- 04 | 语法分析(二):解决二元表达式中的难点
- 05 | 语法分析(三):实现一门简单的脚本语言
- 06 | 编译器前端工具(一):用Antlr生成词法、语法分析器
- 07 | 编译器前端工具(二):用Antlr重构脚本语言
- 08 | 作用域和生存期:实现块作用域和函数
- 09 | 面向对象:实现数据和方法的封装
- 10 | 闭包: 理解了原理,它就不反直觉了
- 11 | 语义分析(上):如何建立一个完善的类型系统?
- 12 | 语义分析(下):如何做上下文相关情况的处理?
- 13 | 继承和多态:面向对象运行期的动态特性
- 14 | 前端技术应用(一):如何透明地支持数据库分库分表?
- 15 | 前端技术应用(二):如何设计一个报表工具?
- 16 | NFA和DFA:如何自己实现一个正则表达式工具?
- 17 | First和Follow集合:用LL算法推演一个实例
- 18 | 移进和规约:用LR算法推演一个实例
- 19 | 案例总结与热点问题答疑:对于左递归的语法,为什么我的推导不是左递归的?
- 20 | 高效运行:编译器的后端技术
- 21 | 运行时机制:突破现象看本质,透过语法看运行时
- 22 | 生成汇编代码(一):汇编语言其实不难学
- 23 | 生成汇编代码(二):把脚本编译成可执行文件
- 24 | 中间代码:兼容不同的语言和硬件
- 25 | 后端技术的重用:LLVM不仅仅让你高效
- 26 | 生成IR:实现静态编译的语言
- 27 | 代码优化:为什么你的代码比他的更高效?
- 28 | 数据流分析:你写的程序,它更懂
- 29 | 目标代码的生成和优化(一):如何适应各种硬件架构?
- 30 | 目标代码的生成和优化(二):如何适应各种硬件架构?
- 加餐 | 汇编代码编程与栈帧管理
- 31 | 内存计算:对海量数据做计算,到底可以有多快?
- 32 | 字节码生成:为什么Spring技术很强大?
- 33 | 垃圾收集:能否不停下整个世界?
- 34 | 运行时优化:即时编译的原理和作用
- 35 | 案例总结与热点问题答疑:后端部分真的比前端部分难吗?
- 36 | 当前技术的发展趋势以及其对编译技术的影响
开篇词 | 为什么你要学习编译原理?
编译原理不是只能用于炫耀的屠龙技。 别的不说,作为程序员,在实际工作中你经常会碰到需要编译技术的场景。
- 处理形式语言的一般都能用到编译原理的技术。
- 文本分析场景,软件需要用户自定义功能的场景以及前端编程语言的翻译场景等
- 很多国外厂商的软件,普遍都具备二次编程能力,比如 Office、CAD、GIS、Mathematica 等等。德国 SAP 公司的企业应用软件也是用自己的业务级语言编写的。
课程的第一部分主要聚焦编译器前端技术,也就是通常说的词法分析、语法分析和语义分析。我会带你了解它们的原理,实现一门脚本语言。我也会教你用工具提升编译工作的效率,还会在几个应用场景中检验我们的学习成果。
第二部分主要聚焦编译器后端技术,也就是如何生成目标代码和对代码进行优化的过程。我会带你纯手工生成汇编代码,然后引入中间代码和后端工具 LLVM,最后生成可执行的文件能支持即时编译,并经过了多层优化。
第三部分是对编译技术发展趋势的一些分析。这些分析会帮助你更好地把握未来技术发展的脉搏。比如人工智能与编译技术结合是否会出现人工智能编程?云计算与编译技术结合是否会催生云编程的新模式?等等。
01 | 理解代码:编译器的前端技术
这里的“前端”指的是编译器对程序代码的分析和理解过程。
它通常只跟语言的语法有关,跟目标机器无关。而与之对应的“后端”则是生成目标代码的过程,跟目标机器有关。

词法分析
文章是由一个个的单词组成的。程序处理也一样,只不过这里不叫单词,而是叫做“词法记号”,英文叫 Token。词法分析是识别一个个的token,即分词程序。
分词是按照一定规则来写的。
这些规则可以通过手写程序来实现。事实上,很多编译器的词法分析器都是手写实现的,例如 GNU 的 C 语言编译器。
如果嫌手写麻烦,也可以偷点儿懒,用词法分析器的生成工具来生成,比如 Lex(或其 GNU 版本,Flex)。这些工具是按照正则表达式来分词的。生成工具可以读入正则表达式,生成一种叫“有限自动机”的算法,来完成具体的词法分析工作。
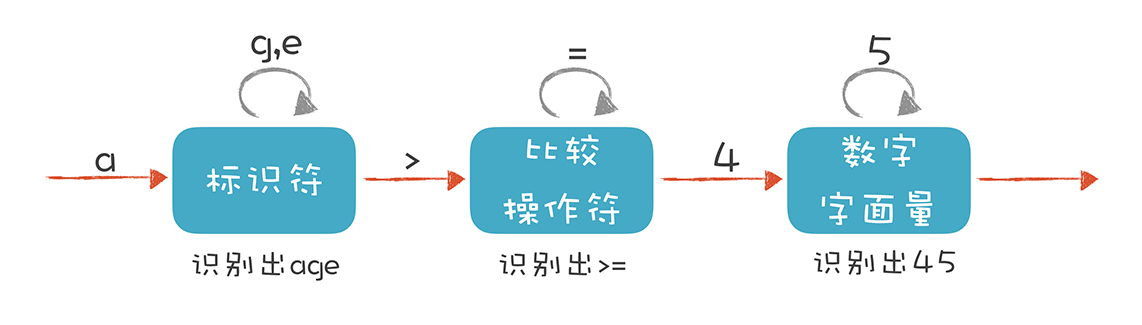
有限自动机是有限个状态的自动机器。我们可以拿抽水马桶举例,它分为两个状态:“注水”和“水满”。摁下冲马桶的按钮,它转到“注水”的状态,而浮球上升到一定高度,就会把注水阀门关闭,它转到“水满”状态。
词法分析器也是一样,它分析整个程序的字符串,当遇到不同的字符时,会驱使它迁移到不同的状态。例如,词法分析程序在扫描 age 的时候,处于“标识符”状态,等它遇到一个 > 符号,就切换到“比较操作符”的状态。词法分析过程,就是这样一个个状态迁移的过程。
语法分析
词法分析是识别一个个的单词,而语法分析就是在词法分析的基础上识别出程序的语法结构。这个结构是一个树状结构,是计算机容易理解和执行的。
程序有定义良好的语法结构,它的语法分析过程,就是构造这么一棵树。一个程序就是一棵树,这棵树叫做抽象语法树(Abstract Syntax Tree,AST)。树的每个节点(子树)是一个语法单元,这个单元的构成规则就叫“语法”。每个节点还可以有下级节点。
形成 AST 以后有什么好处呢?就是计算机很容易去处理。比如,针对表达式形成的这棵树,从根节点遍历整棵树就可以获得表达式的值。
如果再把循环语句、判断语句、赋值语句等节点加到 AST 上,并解释执行它,那么你实际上就实现了一个脚本语言。而执行脚本语言的过程,就是遍历 AST 的过程。
好了,你已经知道了 AST 的作用,那么怎样写程序构造它呢?
例如:int age = 45;
一种非常直观的构造思路是自上而下进行分析。首先构造根节点,代表整个程序,之后向下扫描 Token 串,构建它的子节点。当它看到一个 int 类型的 Token 时,知道这儿遇到了一个变量声明语句,于是建立一个“变量声明”节点;接着遇到 age,建立一个子节点,这是第一个变量;之后遇到 =,意味着这个变量有初始化值,那么建立一个初始化的子节点;最后,遇到“字面量”,其值是 45。
这样,一棵子树就扫描完毕了。程序退回到根节点,开始构建根节点的第二个子节点。这样递归地扫描,直到构建起一棵完整的树。
这个算法就是非常常用的递归下降算法。
递归下降算法是一种自顶向下的算法,与之对应的,还有自底向上的算法。这个算法会先将最下面的叶子节点识别出来,然后再组装上一级节点。有点儿像搭积木,我们总是先构造出小的单元,然后再组装成更大的单元。原理就是这么简单。
很多同学其实已经做过语法解析的工作,比如编写一个自定义公式的功能,对公式的解析就是语法分析过程。另一个例子是分析日志文件等文本文件,对每行日志的解析,本质上也是语法分析过程。解析用 XML、JSON 写的各种配置文件、模型定义文件的过程,其实本质也是语法分析过程,甚至还包含了语义分析工作。
现成的语法分析工具
语义分析
语义分析就是要让计算机理解我们的真实意图,把一些模棱两可的地方消除掉。
比如分析变量的类型、作用域、初值等。
语义分析工作的某些成果,会作为属性标注在抽象语法树上,比如在 age 这个标识符节点和 45 这个字面量节点上,都会标识它的数据类型是 int 型的。
在这个树上还可以标记很多属性,有些属性是在之前的两个阶段就被标注上了,比如所处的源代码行号,这一行的第几个字符。这样,在编译程序报错的时候,就可以比较清楚地了解出错的位置。
做了这些属性标注以后,编译器在后面就可以依据这些信息生成目标代码了,我们在编译技术的后端部分会去讲。
语法阶段是上下文无关的,语义阶段则专门处理上下文。
课程小结
- 词法分析是把程序分割成一个个 Token 的过程,可以通过构造有限自动机来实现。
- 语法分析是把程序的结构识别出来,并形成一棵便于由计算机处理的抽象语法树。可以用递归下降的算法来实现。
- 语义分析是消除语义模糊,生成一些属性信息,让计算机能够依据这些信息生成目标代码。
02 | 正则文法和有限自动机:纯手工打造词法分析器
词法分析的工作是一边读取一边识别字符串的,不是把字符串都读到内存再识别。你在听一位朋友讲话的时候,其实也是同样的过程,一边听,一边提取信息。
要实现一个词法分析器,首先需要写出每个词法的正则表达式,并画出有限自动机,之后,只要用代码表示这种状态迁移过程就可以了。
解析 age >= 45
上述解析式的状态机如下:
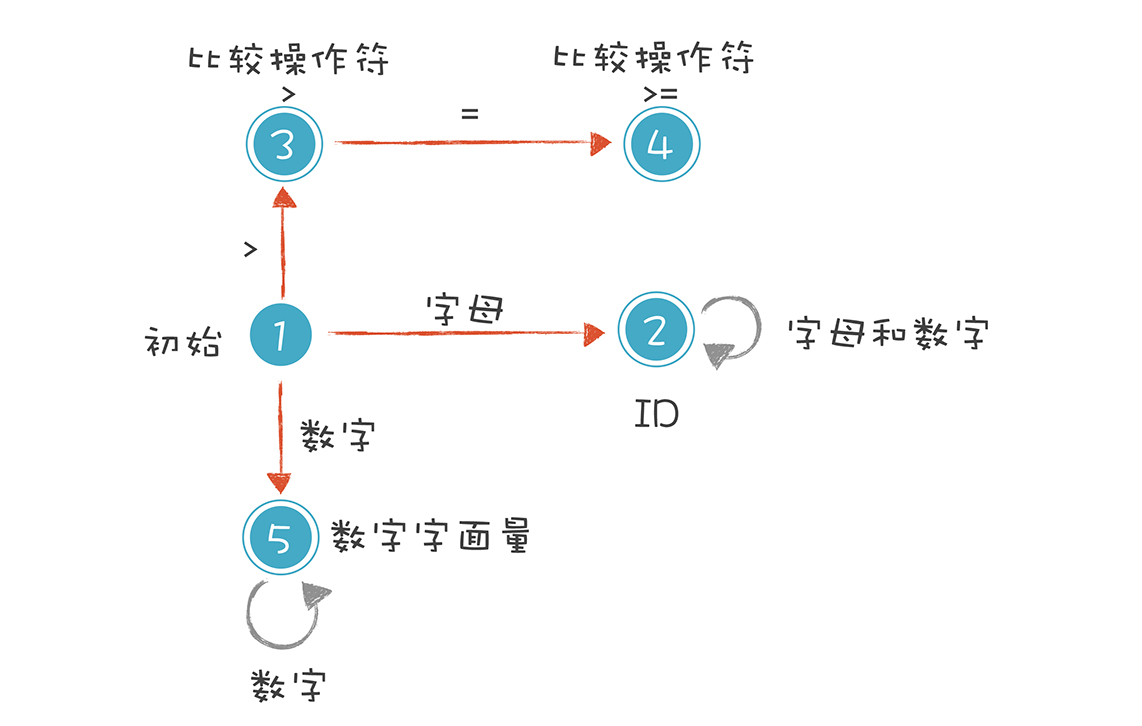
每种状态解析完都会再回到初始状态进行下一步工作。
上面的例子虽然简单,但其实已经讲清楚了词法原理,就是依据构造好的有限自动机,在不同的状态中迁移,从而解析出 Token 来。
初识正则表达式
但是,这里存在一个问题。我们在描述词法规则时用了自然语言。比如,在描述标识符的规则时,我们是这样表达的:
第一个字符必须是字母,后面的字符可以是字母或数字。
这样描述规则并不精确,我们需要换一种严谨的表达方式,这种方式就是正则表达式。
03 | 语法分析(一):纯手工打造公式计算器
本节课将继续“手工打造”之旅,让你纯手工实现一个公式计算器,借此掌握语法分析的原理和递归下降算法(Recursive Descent Parsing),并初步了解上下文无关文法(Context-free Grammar,CFG)。
重点:
- 初步了解上下文无关文法,知道它能表达主流的计算机语言,以及与正则文法的区别。
- 理解递归下降算法中的“下降”和“递归”两个特点。它跟文法规则基本上是同构的,通过文法一定能写出算法。
- 通过遍历 AST 对表达式求值,加深对计算机程序执行机制的理解。
语法和文法有什么区别和联系?
文法,英文叫做Grammar,是形式语言(Formal Language)的一个术语。所以也有Formal Grammar这样的说法。这里的文法有定义清晰的规则。比如,我们的词法规则、语法规则和属性规则,使用形式文法来定义的。我们的课程里讲解了正则文法(Regular Grammar)、上下文无关文法(Context-free Grammar)等不同的文法规则,用来描述词法和语法。
语法分析中的这个语法,英文是Syntax,主要是描述词是怎么组成句子的。一个语言的语法规则,通常指的是这个Syntax。
问题是,Grammar这个词,在中文很多应用场景中也叫做语法。这是会引起混淆的地方。我们在使用的时候要小心一点就行了。
比如,我做了一个规则文件,里面都是一些词法规则(Lexer Grammar),我会说,这是一个词法规则文件,或者词法文法文件。这个时候,把它说成是一个语法规则文件,就有点含义模糊。因为这里面并没有语法规则(Syntax Grammar)。
解析变量声明语句:理解“下降”的含义
我们首先把变量声明语句的规则,用形式化的方法表达一下。它的左边是一个非终结符(Non-terminal)。右边是它的产生式(Production Rule)。在语法解析的过程中,左边会被右边替代。如果替代之后还有非终结符,那么继续这个替代过程,直到最后全部都是终结符(Terminal),也就是 Token。只有终结符才可以成为 AST 的叶子节点。这个过程,也叫做推导(Derivation)过程:
intDeclaration : Int Identifier ('=' additiveExpression)?;private SimpleASTNode intDeclare(TokenReader tokens) throws Exception {
SimpleASTNode node = null;
Token token = tokens.peek(); //预读
if (token != null && token.getType() == TokenType.Int) { //匹配Int
token = tokens.read(); //消耗掉int
if (tokens.peek().getType() == TokenType.Identifier) { //匹配标识符
token = tokens.read(); //消耗掉标识符
//创建当前节点,并把变量名记到AST节点的文本值中,这里新建一个变量子节点也是可以的
node = new SimpleASTNode(ASTNodeType.IntDeclaration, token.getText());
token = tokens.peek(); //预读
if (token != null && token.getType() == TokenType.Assignment) {
tokens.read(); //消耗掉等号
SimpleASTNode child = additive(tokens); //匹配一个表达式
if (child == null) {
throw new Exception("invalide variable initialization, expecting an expression");
}
else{
node.addChild(child);
}
}
} else {
throw new Exception("variable name expected");
}
if (node != null) {
token = tokens.peek();
if (token != null && token.getType() == TokenType.SemiColon) {
tokens.read();
} else {
throw new Exception("invalid statement, expecting semicolon");
}
}
}
return node;
}
String script = "int a = b+3;";
System.out.println("解析变量声明语句: " + script);
SimpleLexer lexer = new SimpleLexer();
TokenReader tokens = lexer.tokenize(script);
try {
SimpleASTNode node = calculator.intDeclare(tokens);
calculator.dumpAST(node,"");
}
catch (Exception e){
System.out.println(e.getMessage());
}在语法分析的时候,传入的是token流,调用这些函数跟后面的 Token 串做模式匹配。匹配上了,就返回一个 AST 节点,否则就返回 null。如果中间发现跟语法规则不符,就报编译错误。
在这个过程中,上级文法嵌套下级文法,上级的算法调用下级的算法。表现在生成 AST 中,上级算法生成上级节点,下级算法生成下级节点。这就是“下降”的含义。
分析上面的伪代码和程序语句,你可以看到这样的特点:程序结构基本上是跟文法规则同构的。这就是递归下降算法的优点,非常直观。
用上下文无关文法描述算术表达式
我们解析算术表达式的时候,会遇到更复杂的情况,这时,正则文法不够用,我们必须用上下文无关文法来表达。你可能会问:“正则文法为什么不能表示算术表达式?”
算术表达式要包含加法和乘法两种运算,我们把规则分成两级:第一级是加法规则,第二级是乘法规则。把乘法规则作为加法规则的子规则,这样在解析形成 AST 时,乘法节点就一定是加法节点的子节点,从而被优先计算。
additiveExpression: multiplicativeExpression | additiveExpression Plus multiplicativeExpression;
multiplicativeExpression: IntLiteral | multiplicativeExpression Star IntLiteral;我们可以通过文法的嵌套,实现对运算优先级的支持。这样我们在解析“2 + 3 * 5”这个算术表达式时会形成类似下面的 AST:
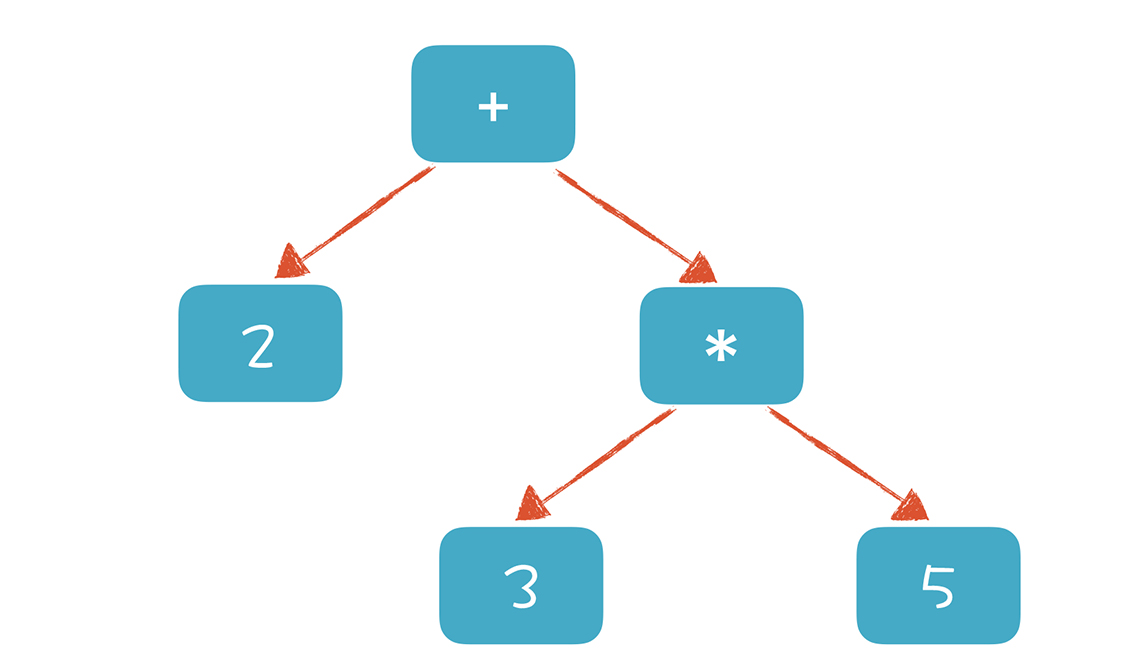
有了这个认知,我们在解析算术表达式的时候,便能拿加法规则去匹配。在加法规则中,会嵌套地匹配乘法规则。我们通过文法的嵌套,实现了计算的优先级。
这种文法已经没有办法改写成正则文法了,它比正则文法的表达能力更强,叫做“上下文无关文法”。正则文法是上下文无关文法的一个子集。它们的区别呢,就是上下文无关文法允许递归调用,而正则文法不允许。
上下文无关的意思是,无论在任何情况下,文法的推导规则都是一样的。比如,在变量声明语句中可能要用到一个算术表达式来做变量初始化,而在其他地方可能也会用到算术表达式。不管在什么地方,算术表达式的语法都一样,都允许用加法和乘法,计算优先级也不变。好在你见到的大多数计算机语言,都能用上下文无关文法来表达它的语法。
那有没有上下文相关的情况需要处理呢?也是有的,但那不是语法分析阶段负责的,而是放在语义分析阶段来处理的。
解析算术表达式:理解“递归”的含义
因为上下文无关文法定义时就是递归定义的,处理时自然要进行递归的处理
为了简单化,我们采用下面这个简化的文法,去掉了乘法的层次:
additiveExpression :IntLiteral |additiveExpression Plus IntLiteral;在解析 “2 + 3”这样一个最简单的加法表达式的时候,我们直观地将其翻译成算法,结果出现了如下的情况:
- 首先匹配是不是整型字面量,发现不是;匹配是要进行最长前缀匹配。
- 然后匹配是不是加法表达式,这里是递归调用;
- 会重复上面两步,无穷无尽。
“additiveExpression Plus multiplicativeExpression”这个文法规则的第一部分就递归地引用了自身,这种情况叫做左递归。通过上面的分析,我们知道左递归是递归下降算法无法处理的,这是递归下降算法最大的问题。
怎么解决呢?把“additiveExpression”调换到加号后面怎么样?我们来试一试。
private SimpleASTNode additive(TokenReader tokens) throws Exception {
SimpleASTNode child1 = multiplicative(); // 计算第一个子节点
SimpleASTNode node = child1; // 如果没有第二个子节点,就返回这个
Token token = tokens.peek();
if (child1 != null && token != null) {
if (token.getType() == TokenType.Plus) {
token = tokens.read();
SimpleASTNode child2 = additive(); // 递归地解析第二个节点
if (child2 != null) {
node = new SimpleASTNode(ASTNodeType.AdditiveExp, token.getText());
node.addChild(child1);
node.addChild(child2);
} else {
throw new Exception("invalid additive expression, expecting the right part.");
}
}
}
return node;
}这个方法其实并没有完美地解决左递归,因为它改变了加法运算的结合性规则。
实现表达式求值
要实现一个表达式计算,只需要基于 AST 做求值运算。这个计算过程比较简单,只需要对这棵树做深度优先的遍历就好了。
04 | 语法分析(二):解决二元表达式中的难点
重点知识:
- 优先级是通过在语法推导中的层次来决定的,优先级越低的,越先尝试推导。
- 结合性是跟左递归还是右递归有关的,左递归导致左结合,右递归导致右结合。
- 左递归可以通过改写语法规则来避免,而改写后的语法又可以表达成简洁的 EBNF 格式,从而启发我们用循环代替右递归。
在二元表达式的语法规则中,如果产生式的第一个元素是它自身,那么程序就会无限地递归下去,这种情况就叫做左递归。比如加法表达式的产生式“加法表达式 + 乘法表达式”,就是左递归的。
书写语法规则,并进行推导
我们已经知道,语法规则是由上下文无关文法表示的,而上下文无关文法是由一组替换规则(又叫产生式)组成的,比如算术表达式的文法规则可以表达成下面这种形式:
add -> mul | add + mul
mul -> pri | mul * pri
pri -> Id | Num | (add) 按照上面的产生式,add 可以替换成 mul,或者 add + mul。这样的替换过程又叫做“推导”
以“2+3*5” 和 “2+3+4”这两个算术表达式为例,这两个算术表达式的推导过程分别如下图所示:
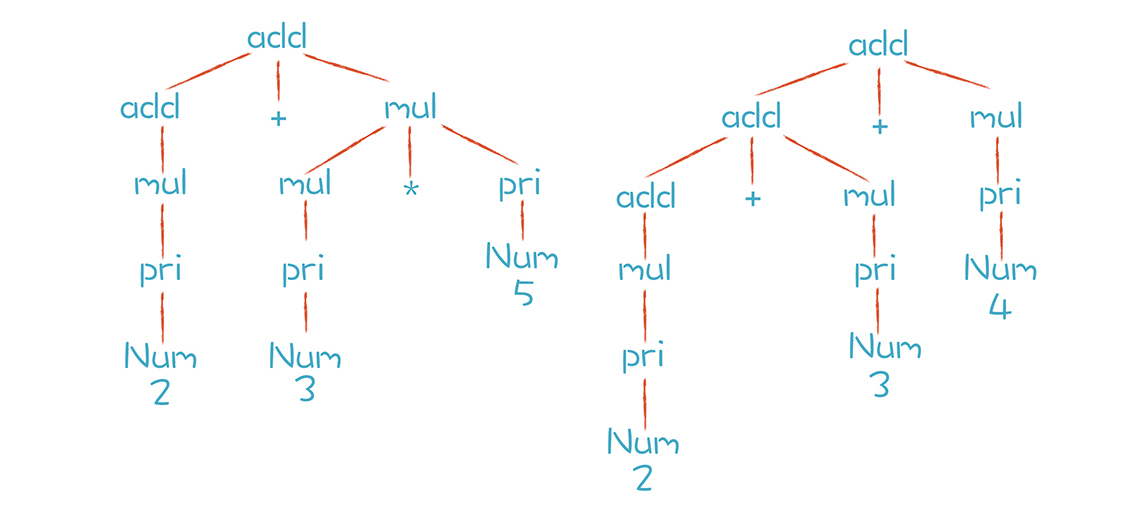
上图中两颗树的叶子节点有哪些呢?Num、+ 和 * 都是终结符,终结符都是词法分析中产生的 Token。而那些非叶子节点,就是非终结符。文法的推导过程,就是把非终结符不断替换的过程,让最后的结果没有非终结符,只有终结符。
而在实际应用中,语法规则经常写成下面这种形式,这种写法叫做“巴科斯范式”,简称 BNF。Antlr 和 Yacc 这两个工具都用这种写法。
add ::= mul | add + mul
mul ::= pri | mul * pri
pri ::= Id | Num | (add) 你有时还会听到一个术语,叫做扩展巴科斯范式 (EBNF)。它跟普通的 BNF 表达式最大的区别,就是里面会用到类似正则表达式的一些写法。比如下面这个规则中运用了 * 号,来表示这个部分可以重复 0 到多次:
add -> mul (+ mul)*其实这种写法跟标准的 BNF 写法是等价的,但是更简洁。为什么是等价的呢?因为一个项多次重复,就等价于通过递归来推导。从这里我们还可以得到一个推论:就是上下文无关文法包含了正则文法,比正则文法能做更多的事情。
确保正确的优先级
掌握了语法规则的写法之后,我们来看看如何用语法规则来保证表达式的优先级。刚刚,我们由加法规则推导到乘法规则,这种方式保证了 AST 中的乘法节点一定会在加法节点的下层,也就保证了乘法计算优先于加法计算。
实际语言中还有更多不同的优先级,优先级越低,所处在语法树的位置就越高。
而且优先级是能够改变的,比如我们通常会在语法里通过括号来改变计算的优先级。这可以在最低层,也就是优先级最高的基础表达式(pri)这里,用括号把表达式包裹起来,递归地引用表达式就可以实改变优先级了。
pri -> Id | Literal | (exp)一个稍完整的语法规则:
exp -> or | or = exp
or -> and | or || and
and -> equal | and && equal
equal -> rel | equal == rel | equal != rel
rel -> add | rel > add | rel < add | rel >= add | rel <= add
add -> mul | add + mul | add - mul
mul -> pri | mul * pri | mul / pri
pri -> Id | Literal | (exp)这里表达的优先级从低到高是:赋值运算、逻辑运算(or)、逻辑运算(and)、相等比较(equal)、大小比较(rel)、加法运算(add)、乘法运算(mul)和基础表达式(pri)。
确保正确的结合性,消除左递归
对于左结合的运算符,递归项要放在左边;而右结合的运算符,递归项放在右边。
消除左递归,用一个标准的方法,就能够把左递归文法改写成非左递归的文法。以加法表达式规则为例,原来的文法是“add -> add + mul | Literal ”,现在我们改写成:
add -> mul add'
add' -> + mul add' | εε(读作 epsilon)是空集的意思
如果用 EBNF 方式表达,也就是允许用 * 号和 + 号表示重复,上面两条规则可以合并成一条:
add -> mul (+ mul)* 写成这样有什么好处呢?能够优化我们写算法的思路。对于 (+ mul)* 这部分,我们其实可以写成一个循环,而不是一次次的递归调用。伪代码如下:
mul();while(next token is +){ mul() createAddNode}我们扩展一下话题。在研究递归函数的时候,有一个概念叫做尾递归,尾递归函数的最后一句是递归地调用自身。
编译程序通常都会把尾递归转化为一个循环语句,使用的原理跟上面的伪代码是一样的。相对于递归调用来说,循环语句对系统资源的开销更低,因此,把尾递归转化为循环语句也是一种编译优化技术。
05 | 语法分析(三):实现一门简单的脚本语言
理解递归下降算法中的回溯
在处理 age = 45;时,语句最左边是一个标识符。根据我们的语法规则,标识符是一个合法的 addtiveExpresion,因此 additive() 函数返回一个非空值。接下来,后面应该扫描到一个分号才对,但是显然不是,标识符后面跟的是等号,这证明模式匹配失败。
失败了该怎么办呢?我们的算法一定要把 Token 流的指针拨回到原来的位置,就像一切都没发生过一样。因为我们不知道 addtive() 这个函数往下尝试了多少步,因为它可能是一个很复杂的表达式,消耗掉了很多个 Token,所以我们必须记下算法开始时候的位置,并在失败时回到这个位置。尝试一个规则不成功之后,恢复到原样,再去尝试另外的规则,这个现象就叫做“回溯”。
因为有可能需要回溯,所以递归下降算法有时会做一些无用功。在 assignmentStatement 的算法中,我们就通过 unread(),回溯了一个 Token。而在 expressionStatement 中,我们不确定要回溯几步,只好提前记下初始位置。匹配 expressionStatement 失败后,算法去尝试匹配 assignmentStatement。这次获得了成功。
试探和回溯的过程,是递归下降算法的一个典型特征。通过上面的例子,你应该对这个典型特征有了更清晰的理解。递归下降算法虽然简单,但它通过试探和回溯,却总是可以把正确的语法匹配出来,这就是它的强大之处。当然,缺点是回溯会拉低一点儿效率。但我们可以在这个基础上进行改进和优化,实现带有预测分析的递归下降,以及非递归的预测分析。有了对递归下降算法的清晰理解,我们去学习其他的语法分析算法的时候,也会理解得更快。
我们接着再讲回溯牵扯出的另一个问题:什么时候该回溯,什么时候该提示语法错误?
大家在阅读示例代码的过程中,应该发现里面有一些错误处理的代码,并抛出了异常。比如在赋值语句中,如果等号后面没有成功匹配一个加法表达式,我们认为这个语法是错的。因为在我们的语法中,等号后面只能跟表达式,没有别的可能性。
token = tokens.read(); // 读出等号
node = additive(); // 匹配一个加法表达式
if (node == null) {
// 等号右边一定需要有另一个表达式
throw new Exception("invalide assignment expression, expecting an additive expression");
}你可能会意识到一个问题,当我们在算法中匹配不成功的时候,我们前面说的是应该回溯呀,应该再去尝试其他可能性呀,为什么在这里报错了呢?换句话说,什么时候该回溯,什么时候该提示这里发生了语法错误呢?
其实这两种方法最后的结果是一样的。我们提示语法错误的时候,是说我们知道已经没有其他可能的匹配选项了,不需要浪费时间去回溯。就比如,在我们的语法中,等号后面必然跟表达式,否则就一定是语法错误。你在这里不报语法错误,等试探完其他所有选项后,还是需要报语法错误。所以说,提前报语法错误,实际上是我们写算法时的一种优化。
在写编译程序的时候,我们不仅仅要能够解析正确的语法,还要尽可能针对语法错误提供友好的提示,帮助用户迅速定位错误。错误定位越是准确、提示越是友好,我们就越喜欢它。
06 | 编译器前端工具(一):用Antlr生成词法、语法分析器
一个完善的编译程序还要在词法方面以及语法方面实现很多工作,我这里特意画了一张图,你可以直观地看一下。

如果让编译程序实现上面这么多工作,完全手写效率会有点儿低,那么我们有什么方法可以提升效率呢?答案是借助工具。
编译器前端工具有很多,比如 Lex(以及 GNU 的版本 Flex)、Yacc(以及 GNU 的版本 Bison)、JavaCC 等等。你可能会问了:“那为什么我们这节课只讲 Antlr,不选别的工具呢?”主要有两个原因。
- 第一个原因是 Antlr 支持更广泛的目标语言,包括 Java、C#、JavaScript、Python、Go、C++、Swift。无论你用上面哪种语言,都可以用它生成词法和语法分析的功能。而我们就使用它生成了 Java 语言和 C++ 语言两个版本的代码。
- 第二个原因是 Antlr 的语法更加简单。它能把类似左递归的一些常见难点在工具中解决,对提升工作效率有很大的帮助。
而我们今天的目标就是了解 Antlr,然后能够使用 Antlr 生成词法分析器与语法分析器。
初识 Antlr
Antlr(/ˈænt.lər/)(ANother Tool for Language Recognition) 是一个开源的工具,支持根据规则文件生成词法分析器和语法分析器,它自身是用 Java 实现的。
Antlr 通过解析规则文件来生成编译器。规则文件以.g4 结尾,词法规则和语法规则可以放在同一个文件里。不过为了清晰起见,我们还是把它们分成两个文件。
Antlr安装
- Install Java,and config java path
- Download antlr-4.13.1-complete.jar (or whatever version) from https://www.antlr.org/download.html Save to your directory for 3rd party Java libraries, say
C:\Javalib - Add
antlr-4.13.1-complete.jarto CLASSPATH - test is ok,
java org.antlr.v4.Tool - Create short convenient commands for the ANTLR Tool, and TestRig, using batch files
antlr4.bat
java org.antlr.v4.Tool %*grun.bat
@ECHO OFF
SET TEST_CURRENT_DIR=%CLASSPATH:.;=%
if "%TEST_CURRENT_DIR%" == "%CLASSPATH%" ( SET CLASSPATH=.;%CLASSPATH% )
@ECHO ON
java org.antlr.v4.gui.TestRig %*用 Antlr 生成词法分析器
Antlr格式:
每个词法规则都是大写字母开头,这是 Antlr 对词法规则的约定。而语法规则是以小写字母开头的
antlr Hello.g4会生成Hello.java、Hello.tokens、Hello.interp
javac Hello*.java生成Hello.class
grun Hello tokens -tokens hello.play上面的命令会把hello.play文件生成token流并打印出来
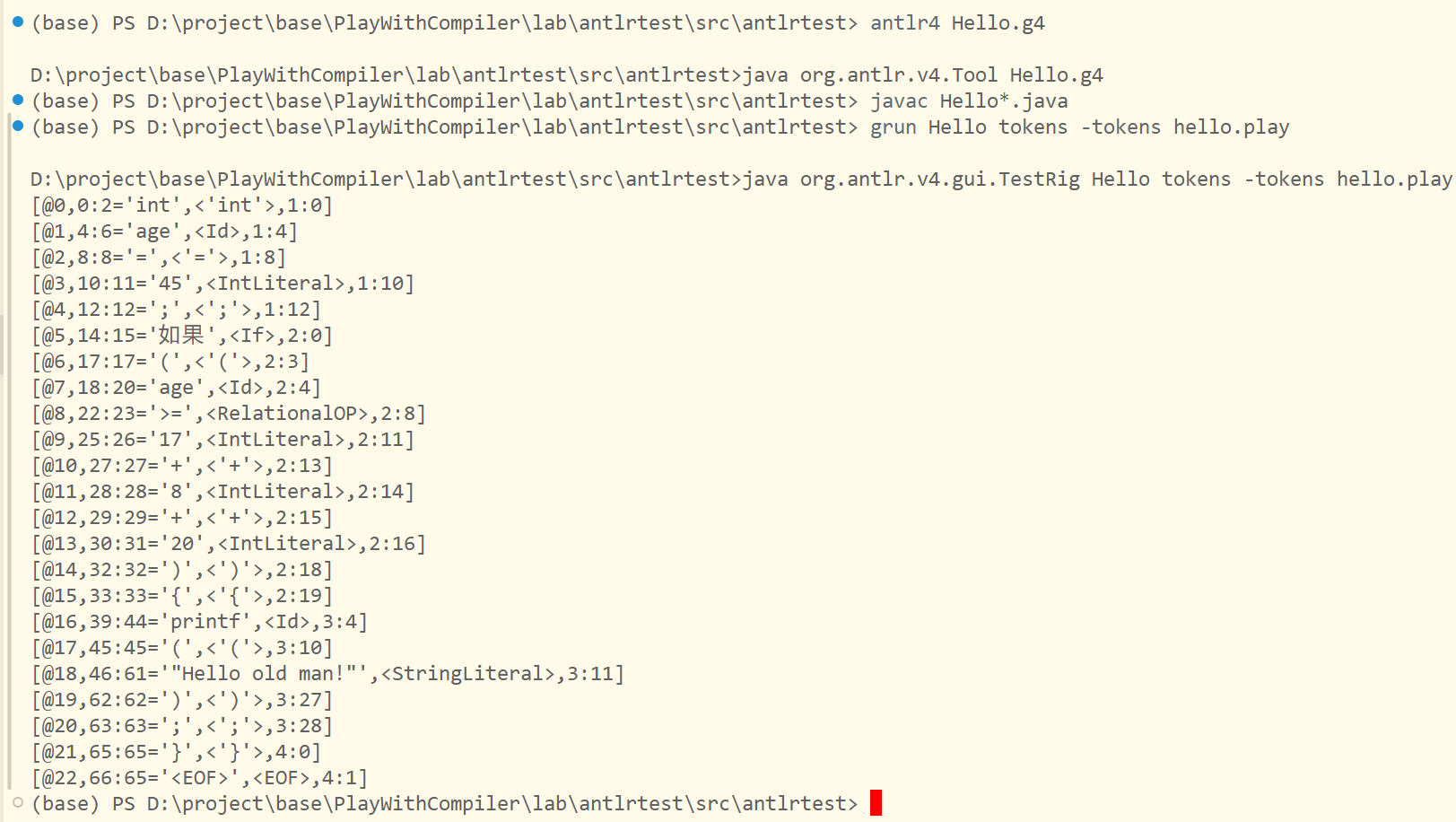
我们再来回顾一下在“02 | 正则文法和有限自动机:纯手工打造词法分析器”里做词法分析时遇到的一个问题。当时,我们分析了词法冲突的问题,即标识符和关键字的规则是有重叠的。Antlr 是怎么解决这个问题的呢?很简单,它引入了优先级的概念。在 Antlr 的规则文件中,越是前面声明的规则,优先级越高。所以,我们把关键字的规则放在 ID 的规则前面。算法在执行的时候,会首先检查是否为关键字,然后才会检查是否为 ID,也就是标识符。
这跟我们当时构造有限自动机做词法分析是一样的。那时,我们先判断是不是关键字,如果不是关键字,才识别为标识符。而在 Antlr 里,仅仅通过声明的顺序就解决了这个问题,省了很多事儿啊!
用 Antlr 生成语法分析器
antlr4 PlayScript.g4
javac antlrtest/*.java
grun antlrtest.PlayScript expression -gui07 | 编译器前端工具(二):用Antlr重构脚本语言
完善表达式(Expression)的语法
我们可以把所有的运算都用一个语法规则来涵盖,然后用最简洁的方式支持表达式的优先级和结合性。
- 优先级
那么它是怎样支持优先级的呢?原来,优先级是通过右侧不同产生式的顺序决定的。在标准的上下文无关文法中,产生式的顺序是无关的,但在具体的算法中,会按照确定的顺序来尝试各个产生式。
- 结合性
在语法文件中,Antlr 对于赋值表达式做了 <assoc=right> 的属性标注,说明赋值表达式是右结合的。如果不标注,就是左结合的,交给 Antlr 实现了!
* 区别表达式类型
“如果都是同样的表达式节点,怎么在解析器里把它们区分开呢?怎么知道哪个节点是做加法运算或乘法运算呢?”很简单,我们可以查找一下当前节点有没有某个运算符的 Token
完善各类语句(Statement)的语法
if语句的二义性文法
if的语法规则:
statement :
...
| IF parExpression statement (ELSE statement)?
...
;
parExpression : '(' expression ')';学计算机语言的时候,提到 if 语句,会特别提一下嵌套 if 语句和悬挂 else 的情况
一旦你语法规则写得不够好,就很可能形成二义性,也就是用同一个语法规则可以推导出两个不同的句子,或者说生成两个不同的 AST。这种文法叫做二义性文法
再说回我们给 Antlr 定义的语法,这个语法似乎并不复杂,怎么就能确保不出现二义性问题呢?因为 Antlr 解析语法时用到的是 LL 算法。最左推导、深度优先
LL 算法是一个深度优先的算法,所以在解析到第一个 statement 时,就会建立下一级的 if 节点,在下一级节点里会把 else 子句解析掉。如果 Antlr 不用 LL 算法,就会产生二义性。这再次验证了我们前面说的那个知识点:文法要经常和解析算法配合。
我们实现一个算法的时候,是有确定的顺序来匹配的。所以,即使是二义性文法,在某种算法下也可以正常解析。
严格的非二义性文法要求得比较高。它要求是算法无关的。也就是不管你用最左还是最右推导,得出的结果是一样的。
关键点,在于把“文法”和“算法”这两件事区分开。文法是二义的,用某个具体算法却不一定是二义的。
for 语句
statement :
...
| FOR '(' forControl ')' statement
...
;
forControl
: forInit? ';' expression? ';' forUpdate=expressionList?
;
forInit
: variableDeclarators
| expressionList
;
expressionList
: expression (',' expression)*
;用 Vistor 模式升级脚本解释器
我们在纯手工编写的脚本语言解释器里,用了一个 evaluate() 方法自上而下地遍历了整棵树。随着要处理的语法越来越多,这个方法的代码量会越来越大,不便于维护。而 Visitor 设计模式针对每一种 AST 节点,都会有一个单独的方法来负责处理,能够让代码更清晰,也更便于维护。
Antlr 能帮我们生成一个 [[A-IT/00-CS基础/50-algorithm/设计模式/设计模式#Visitor 模式]]的框架,我们在命令行输入:
antlr -visitor PlayScript.g408 | 作用域和生存期:实现块作用域和函数
作用域(Scope)
作用域是指计算机语言中变量、函数、类等起作用的范围,空间的作用范围
- 变量的作用域有大有小,外部变量在函数内可以访问,而函数中的本地变量,只有本地才可以访问。
- 变量的作用域,从声明以后开始。
- 在函数里,我们可以声明跟外部变量相同名称的变量,这个时候就覆盖了外部变量。
对比了三种语言的作用域特征之后,你是否发现原来看上去差不多的语法,内部机理却不同?这种不同其实是语义差别的一个例子。你要注意的是,现在我们讲的很多内容都已经属于语义的范畴了,对作用域的分析就是语义分析的任务之一。
生存期(Extent)
它是变量可以访问的时间段,也就是从分配内存给它,到收回它的内存之间的时间。时间的作用范围
那么为什么说作用域和生存期是计算机语言更加基础的概念呢?其实是因为它们对应到了运行时的内存管理的基本机制。它们可以帮你深入地理解函数、块、闭包、面向对象、静态成员、本地变量和全局变量等概念。
实现作用域和栈
在之前的 PlayScript 脚本的实现中,处理变量赋值的时候,我们简单地把变量存在一个哈希表里,用变量名去引用,就像下面这样:
public class SimpleScript {
private HashMap<String, Integer> variables = new HashMap<String, Integer>();
...
}但如果变量存在多个作用域,这样做就不行了。这时,我们就要设计一个数据结构,区分不同变量的作用域。
我们在解释执行 playscript 的 AST 的时候,需要建立起作用域的树结构,对作用域的分析过程是语义分析的一部分。也就是说,并不是有了 AST,我们马上就可以运行它,在运行之前,我们还要做语义分析,比如对作用域做分析,让每个变量都能做正确的引用,这样才能正确地执行这个程序。
代码执行时进入和退出一个个作用域的过程,可以用栈来实现。每进入一个作用域,就往栈里压入一个数据结构,这个数据结构叫做栈桢(Stack Frame)。栈桢能够保存当前作用域的所有本地变量的值,当退出这个作用域的时候,这个栈桢就被弹出,里面的变量也就失效了。
09 | 面向对象:实现数据和方法的封装
本节课,我将从语义设计和运行时机制的角度剖析面向对象的特性,带你深入理解面向对象的实现机制
我们针对面向对象的封装特性,从类型、作用域和生存期的角度进行了重新解读,这样能够更好地把握面向对象的本质特征。我们还设计了与面向对象的相关的语法并做了解析,然后讨论了面向对象程序的运行期机制,例如如何实例化一个对象,如何在内存里管理对象的数据,以及如何访问对象的属性和方法。
10 | 闭包: 理解了原理,它就不反直觉了
使用闭包特性要解决两个问题:
- 函数要变成 playscript 的一等公民。也就是要能把函数像普通数值一样赋值给变量,可以作为参数传递给其他函数,可以作为函数的返回值。
- 要让内层函数一直访问它环境中的变量,不管外层函数退出与否。
用静态作用域的概念描述一下闭包,我们可以这样说:因为我们的语言是静态作用域的,它能够访问的变量,需要一直都能访问,为此,需要把某些变量的生存期延长。
其实,闭包就是把函数在静态作用域中所访问的变量的生存期拉长,形成一份可以由这个函数单独访问的数据。正因为这些数据只能被闭包函数访问,所以也就具备了对信息进行封装、隐藏内部细节的特性。
11 | 语义分析(上):如何建立一个完善的类型系统?
类型系统是一门语言所有的类型的集合,操作这些类型的规则,以及类型之间怎么相互作用的
对类型做定义很难,但大家公认的有一个说法:类型是针对一组数值,以及在这组数值之上的一组操作。比如,对于数字类型,你可以对它进行加减乘除算术运算,对于字符串就不行。
所以,类型是高级语言赋予的一种语义,有了类型这种机制,就相当于定了规矩,可以检查施加在数据上的操作是否合法。因此类型系统最大的好处,就是可以通过类型检查降低计算出错的概率。
通过这个类型推导的例子,我们又可以引出S 属性(Synthesized Attribute) 的知识点。如果一种属性能够从下级节点推导出来,那么这种属性就叫做 S 属性,字面意思是综合属性,就是在 AST 中从下级的属性归纳、综合出本级的属性。更准确地说,是通过下级节点和自身来确定的。
与 S 属性相对应的是I 属性(Inherited Attribute), 也就是继承属性,即 AST 中某个节点的属性是由上级节点、兄弟节点和它自身来决定的
12 | 语义分析(下):如何做上下文相关情况的处理?
语义分析的本质,就是针对上下文相关的情况做处理
我们之前讲到的作用域,是一种上下文相关的情况,因为如果作用域不同,能使用的变量也是不同的。类型系统也是一种上下文相关的情况,类型推导和类型检查都要基于上下文中相关的 AST 节点。
语义分析场景:引用的消解
语义分析场景:左值和右值
属性计算需要用到属性文法。在词法、语法分析阶段,我们分别学习了正则文法和上下文无关文法,在语义分析阶段我们要了解的是属性文法(Attribute Grammar)。
下面是上下文无关文法表达加法和乘法运算的例子:
add → add + mul
add → mul
mul → mul * primary
mul → primary
primary → "(" add ")"
primary → integer然后看一看对 value 属性进行计算的属性文法:
add1 → add1 + mul [ add1.value = add2.value + mul.value ]
add → mul [ add.value = mul.value ]
mul1 → mul2 * primary [ mul1.value = mul2.value * primary.value ]
mul → primary [ mul.value = primary.value ]
primary → "(" add ")" [ primary.value = add.value ]
primary → integer [ primary.value = strToInt(integer.str) ]总结一下属性计算的特点:它会基于语法规则,增加一些与语义处理有关的规则。
所以,我们也把这种语义规则的定义叫做语法制导的定义(Syntax directed definition,SDD),如果变成计算动作,就叫做语法制导的翻译(Syntax directed translation,SDT)。
属性计算,可以伴随着语法分析的过程一起进行,也可以在做完语法分析以后再进行。这两个阶段不一定完全切分开。甚至,我们有时候会在语法分析的时候做一些属性计算,然后把计算结果反馈回语法分析的逻辑,帮助语法分析更好地执行
在我看来,语义分析这个阶段十分重要。因为词法和语法都有很固定的套路,甚至都可以工具化的实现。但语言设计的核心在于语义,特别是要让语义适合所解决的问题。比如 SQL 语言针对的是数据库的操作,那就去充分满足这个目标就好了。我们在前端技术的应用篇中,也会复盘讨论这个问题,不断实现认知的迭代升级。
如果想做一个自己领域的 DSL,学习了这几讲语义分析的内容之后,你会更好地做语义特性的设计与取舍,也会对如何完成语义分析有清晰的思路。
13 | 继承和多态:面向对象运行期的动态特性
继承和多态对类型系统提出的新概念,就是子类型。我们之前接触的类型往往是并列关系,你是整型,我是字符串型,都是平等的。而现在,一个类型可以是另一个类型的子类型,比如我是一只羊,又属于哺乳动物。这会导致我们在编译期无法准确计算出所有的类型,从而无法对方法和属性的调用做完全正确的消解(或者说绑定)。这部分工作要留到运行期去做,也因此,面向对象编程会具备非常好的优势,因为它会导致多态性。
从类型体系的角度理解继承和多态
子类型有两种实现方式:一种就是像 Java 和 C++ 语言,需要显式声明继承了什么类,或者实现了什么接口。这种叫做名义子类型(Nominal Subtyping)。
另一种是结构化子类型(Structural Subtyping),又叫鸭子类型(Duck Type)。也就是一个类不需要显式地说自己是什么类型,只要它实现了某个类型的所有方法,那就属于这个类型。鸭子类型是个直观的比喻,如果我们定义鸭子的特征是能够呱呱叫,那么只要能呱呱叫的,就都是鸭子。
14 | 前端技术应用(一):如何透明地支持数据库分库分表?
这节课,我们主要讨论,一个分布式数据库领域的需求。我会带你设计一个中间层,让应用逻辑不必关心数据库的物理分布。这样,无论把数据库拆成多少个分库,编程时都会像面对一个物理库似的没什么区别。
分布式数据库解决了什么问题,又带来了哪些挑战
分库分表(Sharding)有时也翻译成“数据库分片”。分片可以依据各种不同的策略,比如我开发过一个与社区有关的应用系统,这个系统的很多业务逻辑都是围绕小区展开的。对于这样的系统,按照地理分布的维度来分片就很合适,因为每次对数据库的操作基本上只会涉及其中一个分库。
通过数据库分片,我们可以提高数据库服务的性能和可伸缩性。当数据量和访问量增加时,增加数据库节点的数量就行了。不过,虽然数据库的分片带来了性能和伸缩性的好处,但它也带来了一些挑战。
最明显的一个挑战,是数据库分片逻辑侵入到业务逻辑中。过去,应用逻辑只访问一个数据库,现在需要根据分片的规则,判断要去访问哪个数据库,再去跟这个数据库服务器连接。如果增加数据库分片,或者对分片策略进行调整,访问数据库的所有应用模块都要修改。这会让软件的维护变得更复杂,显然也不太符合软件工程中模块低耦合、把变化隔离的理念。
所以如果有一种技术,能让我们访问很多数据库分片时,像访问一个数据库那样就好了。数据库的物理分布,对应用是透明的。
可是,“理想很吸引人,现实很骨感”。要实现这个技术,需要解决很多问题:
首先是跨库查询的难题。
如果我们前端显示的时候需要分页,每页显示一百行,那就更麻烦了。我们不可能从 10 个分库中各查出 10 行,合并成 100 行,这 100 行不一定排在前面,最差的情况,可能这 100 行恰好都在其中一个分库里。所以,你可能要从每个分库查出 100 行来,合并、排序后,再取出前 100 行。如果涉及数据库表跨库做连接,你想象一下,那就更麻烦了。
其次就是跨库做写入的难题。如果对数据库写入时遇到了跨库的情况,那么就必须实现分布式事务。所以,虽然分布式数据库的愿景很吸引人,但我们必须解决一系列技术问题。
这一讲,我们先解决最简单的问题,也就是当每次数据操作仅针对一个分库的时候,能否自动确定是哪个分库的问题。 解决这个问题我们不需要依据别的信息,只需要提供 SQL 就行了。这就涉及对 SQL 语句的解析了,自然要用到编译技术。
15 | 前端技术应用(二):如何设计一个报表工具?
16 | NFA和DFA:如何自己实现一个正则表达式工具?
接下来,我就带你完成编写正则表达式工具的任务,与此同时,你就能用正则文法生成词法分析器了:
首先, 把正则表达式翻译成非确定的有限自动机(Nondeterministic Finite Automaton,NFA)。
其次, 基于 NFA 处理字符串,看看它有什么特点。
然后, 把非确定的有限自动机转换成确定的有限自动机(Deterministic Finite Automaton,DFA)
最后, 运行 DFA,看看它有什么特点。
认识 DFA 和 NFA
在讲词法分析时,我提到有限自动机(FSA)有有限个状态。识别 Token 的过程,就是 FSA 状态迁移的过程。其中,FSA 分为确定的有限自动机(DFA) 和非确定的有限自动机(NFA)。
DFA 的特点是, 在任何一个状态,我们基于输入的字符串,都能做一个确定的转换
NFA 的特点是, 它存在某些状态,针对某些输入,不能做一个确定的转换,这又细分成两种情况:
- 对于一个输入,它有两个状态可以转换。
- 存在ε转换。也就是没有任何输入的情况下,也可以从一个状态迁移到另一个状态。
需要注意的是,无论是 NFA 还是 DFA,都等价于正则表达式。也就是,所有的正则表达式都能转换成 NFA 或 DFA,所有的 NFA 或 DFA,也都能转换成正则表达式。
从正则表达式生成 NFA
我们需要把它分为两个子任务:
- 第一个子任务, 是把正则表达式解析成一个内部的数据结构,便于后续的程序使用。因为正则表达式也是个字符串,所以要先做一个小的编译器,去理解代表正则表达式的字符串。我们可以偷个懒,直接针对示例的正则表达式生成相应的数据结构,不需要做出这个编译器。
- 第二个子任务, 就是把表示正则表达式的数据结构,转换成一个 NFA。这个过程比较简单,因为针对正则表达式中的每一个结构,我们都可以按照一个固定的规则做转换。
测试的正则表达式可以是 int 关键字、标识符,或者数字字面量:
int | [a-zA-Z][a-zA-Z0-9]* | [0-9]*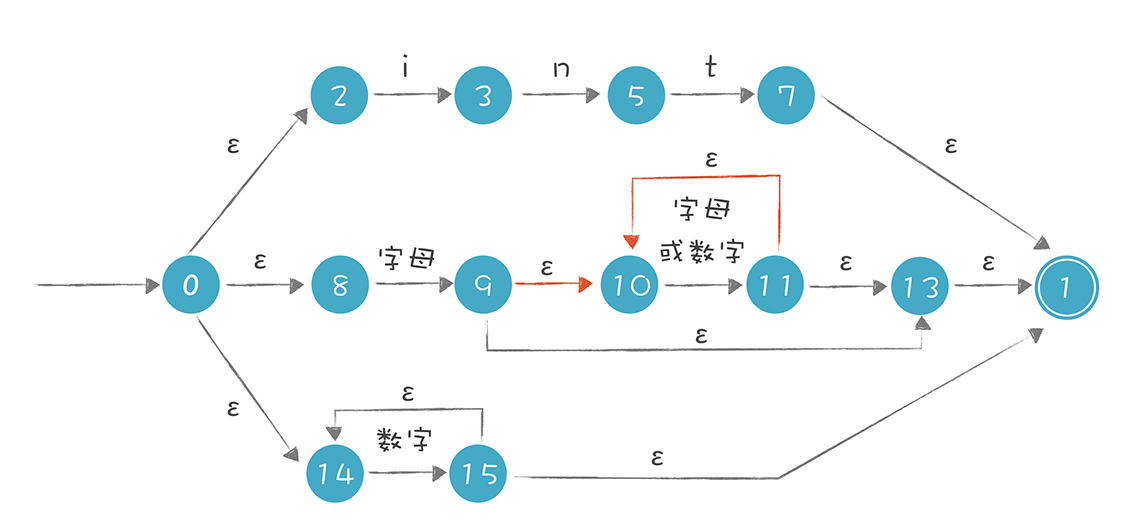
以上图为例,当我们解析 intA 这个字符串时,首先选择最上面的路径去匹配,匹配完 int 这三个字符以后,来到状态 7,若后面没有其他字符,就可以到达接受状态 1,返回匹配成功的信息。可实际上,int 后面是有 A 的,所以第一条路径匹配失败。
失败之后不能直接返回“匹配失败”的结果,因为还有其他路径,所以我们要回溯到状态 0,去尝试第二条路径,在第二条路径中,尝试成功了
NFA 算法的特点: 因为存在多条可能的路径,所以需要试探和回溯,在比较极端的情况下,回溯次数会非常多,性能会变得非常慢。特别是当处理类似 s* 这样的语句时,因为 s 可以重复 0 到无穷次,所以在匹配字符串时,可能需要尝试很多次。
NFA 的运行可能导致大量的回溯,所以能否将 NFA 转换成 DFA,让字符串的匹配过程更简单呢?如果能的话,那整个过程都可以自动化,从正则表达式到 NFA,再从 NFA 到 DFA。
把 NFA 转换成 DFA
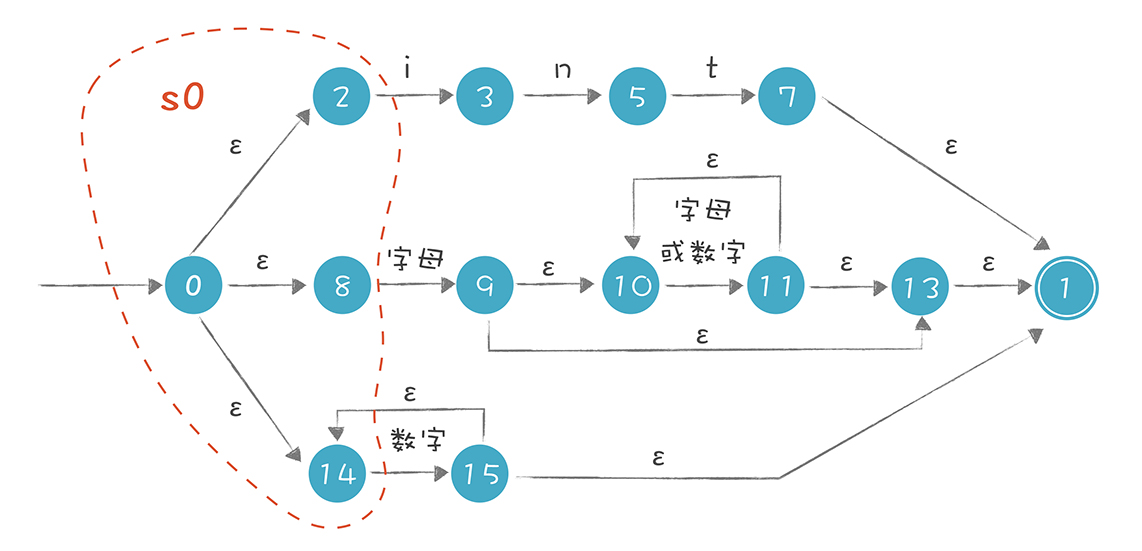
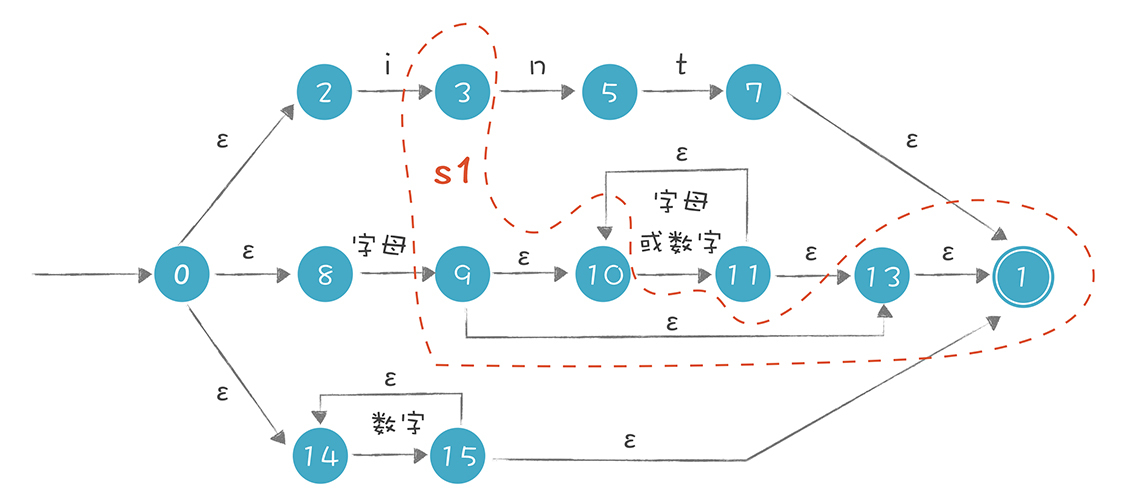
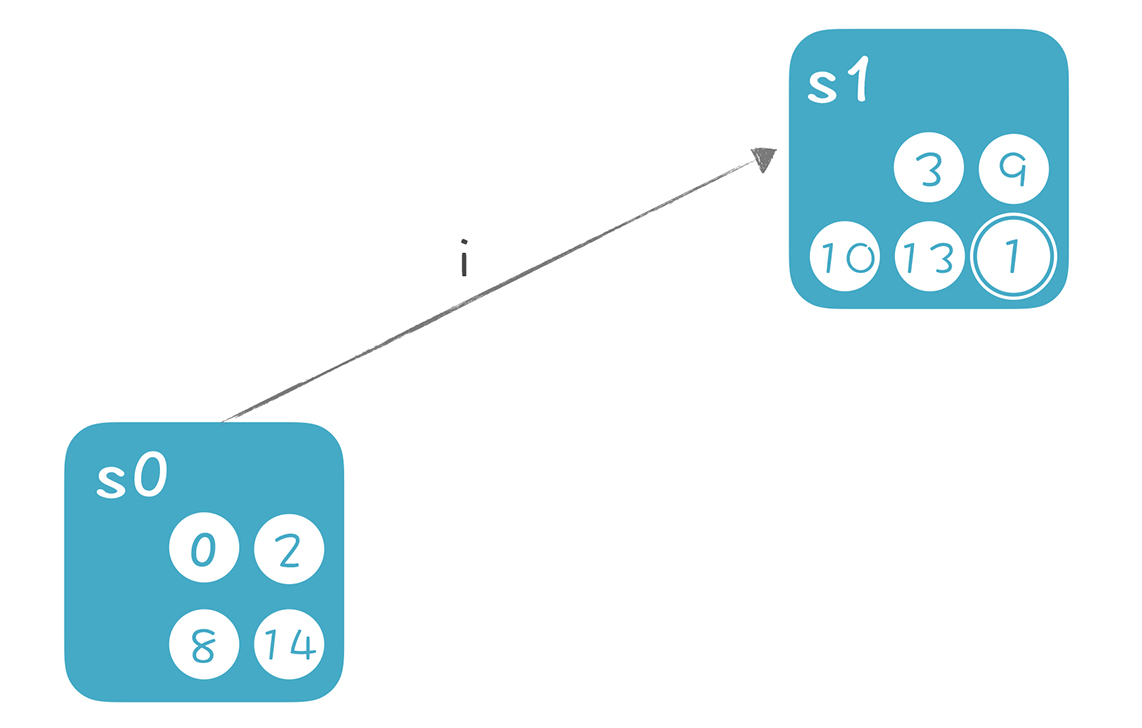
在上面的推导过程中,我们有两个主要的计算:
1.ε-closure(s),即集合 s 的ε闭包。也就是从集合 s 中的每个节点,加上从这个节点出发通过ε转换所能到达的所有状态。
2.move(s, ‘i’),即从集合 s 接收一个字符 i,所能到达的新状态的集合。
所以,s1 = ε-closure(move(s0,‘i’))
本节课,我带你实现了一个正则表达式工具,或者说根据正则表达式自动做了词法分析,它们的主要原理是相同的。
首先,我们需要解析正则表达式,形成计算机内部的数据结构,然后要把这个正则表达式生成 NFA。我们可以基于 NFA 进行字符串的匹配,或者把 NFA 转换成 DFA,再进行字符串匹配。
NFA 和 DFA 有各自的优缺点:NFA 通常状态数量比较少,可以直接用来进行计算,但可能会涉及回溯,从而性能低下;DFA 的状态数量可能很大,占用更多的空间,并且生成 DFA 本身也需要消耗计算资源。所以,我们根据实际需求选择采用 NFA 还是 DFA 就可以了。
不过,一般来说,正则表达式工具可以直接基于 NFA。而词法分析器(如 Lex),则是基于 DFA。原因很简单,因为在生成词法分析工具时,只需要计算一次 DFA,就可以基于这个 DFA 做很多次词法分析。
17 | First和Follow集合:用LL算法推演一个实例
在前面的课程中,我讲了递归下降算法。这个算法很常用,但会有回溯的现象,在性能上会有损失。所以我们要把算法升级一下,实现带有预测能力的自顶向下分析算法,避免回溯。而要做到这一点,就需要对自顶向下算法有更全面的了解。
自顶向下分析算法概述
自顶向下分析的算法是一大类算法。总体来说,它是从一个非终结符出发,逐步推导出跟被解析的程序相同的 Token 串。
根据搜索的策略,有深度优先(Depth First)和广度优先(Breadth First) 两种,这两种策略的推导过程是不同的。
深度优先是沿着一条分支把所有可能性探索完。以“add->mul+add”产生式为例,它会先把 mul 这个非终结符展开,比如替换成 pri,然后再把它的第一个非终结符 pri 展开。只有把这条分支都向下展开之后,才会回到上一级节点,去展开它的兄弟节点。
递归下降算法就是深度优先的,这也是它不能处理左递归的原因,因为左边的分支永远也不能展开完毕。
而针对“add->add+mul”这个产生式,广度优先会把 add 和 mul 这两个都先展开,这样就形成了四条搜索路径,分别是 mul+mul、add+mul+mul、add+pri 和 add+mul+pri。接着,把它们的每个非终结符再一次展开,会形成 18 条新的搜索路径。
所以,广度优先遍历,需要探索的路径数量会迅速爆炸,成指数级上升。哪怕用下面这个最简单的语法,去匹配“2+3”表达式,都需要尝试 20 多次,更别提针对更复杂的表达式或者采用更加复杂的语法规则了。
这样看来,指数级上升的内存消耗和计算量,使得广度优先根本没有实用价值。虽然上面的算法有优化空间,但无法从根本上降低算法复杂度。当然了,它也有可以使用左递归文法的优点,不过我们不会为了这个优点去忍受算法的性能。
而深度优先算法在内存占用上是线性增长的。考虑到回溯的情况,在最坏的情况下,它的计算量也会指数式增长,但我们可以通过优化,让复杂度降为线性增长。
针对深度优先算法的优化方向是减少甚至避免回溯,思路就是给算法加上预测能力。比如,我在解析 statement 的时候,看到一个 if,就知道肯定这是一个条件语句,不用再去尝试其他产生式了。
LL 算法就属于这类预测性的算法。 第一个 L,是 Left-to-right,代表从左向右处理程序代码。第二个 L,是 Leftmost,意思是最左推导。
按照语法规则,一个非终结符展开后,会形成多个子节点,其中包含终结符和非终结符。最左推导是指,从左到右依次推导展开这些非终结符。采用 Leftmost 的方法,在推导过程中,句子的左边逐步都会被替换成终结符,只有右边的才可能包含非终结符。
18 | 移进和规约:用LR算法推演一个实例
LR 算法是一种自底向上的算法,它能够支持更多的语法,而且没有左递归的问题。第一个字母 L,与 LL 算法的第一个 L 一样,代表从左向右读入程序。第二个字母 R,指的是 RightMost(最右推导),也就是在使用产生式的时候,是从右往左依次展开非终结符。
自顶向下的算法,是递归地做模式匹配,从而逐步地构造出 AST。那么自底向上的算法是如何构造出 AST 的呢?答案是用移进 - 规约的算法。
整个语法解析过程,实质是反向最右推导(Reverse RightMost Derivation)。 什么意思呢?如果把 AST 节点根据创建顺序编号,就是下面这张图呈现的样子,根节点编号最大是 13:
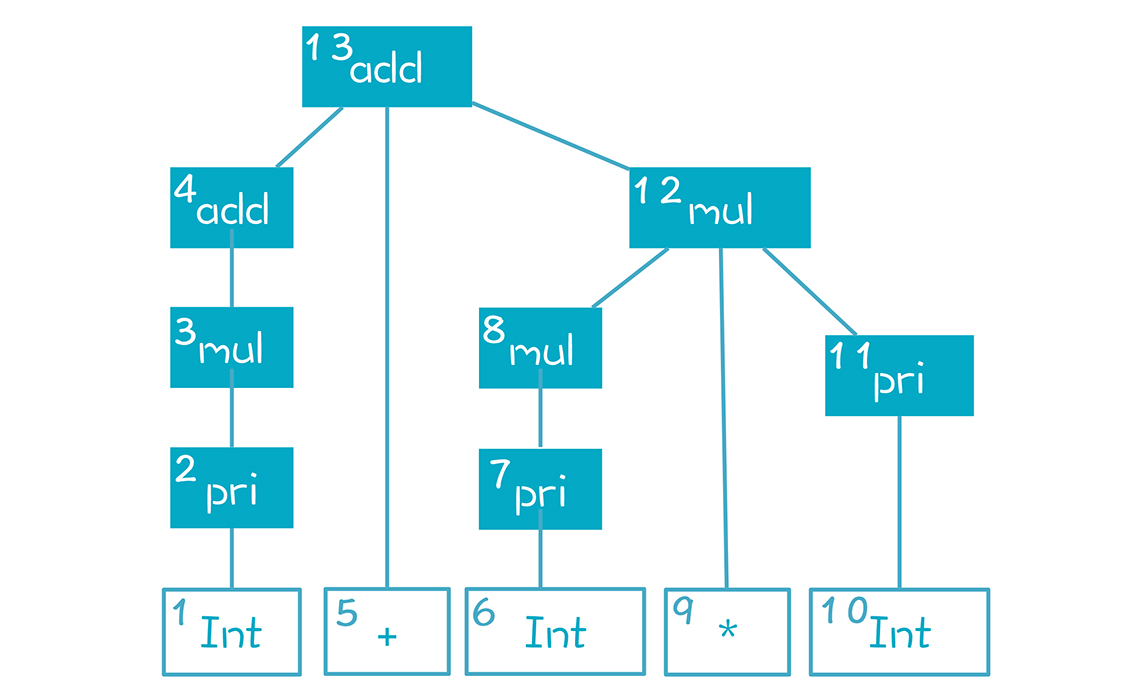
但这是规约的过程,如果是从根节点开始的推导过程,顺序恰好是反过来的,先是 13 号,再是右子节点 12 号,再是 12 号的右子节点 11 号,以此类推。
在语法解析的时候,我们是从底下反推回去,所以叫做反向的最右推导过程。从这个意义上讲,LR 算法中的 R,带有反向(Reverse)和最右(Reightmost)这两层含义。
今天,我们讲了自底向上的 LR 算法的原理,包括移进 - 规约,如何寻找正确的句柄,如果基于 NFA 和 DFA 决定如何做移进和规约。
LR 算法是公认的比较难学的一个算法。好在我们已经在前两讲给它做了技术上的铺垫了,包括 NFA 和 DFA,First 和 Follow 集合。这节课我们重点在于建立直观理解,特别是如何依据栈里的信息做正确的反推。这个直觉认知很重要,建立这个直觉的最好办法,就是像本节课一样,根据实例来画图、推导。这样,在你真正动手写算法的时候,就胸有成竹了!
19 | 案例总结与热点问题答疑:对于左递归的语法,为什么我的推导不是左递归的?
问题一:对于左递归的语法,为什么我的推导不是左递归的?
比如用下面这个语法,来推导“2+3”这个简单的表达式:
// 简化的左递归文法
add->Int
add->add + Int你可能会拿第一个产生式做推导:add->2,但是再往下的是+ 3,这个用哪个产生式推导都推导不出来,于是只能回退再进行处理。
而拿第二个产生式推导,按左递归方式进行推导的话,则又得先推导出add来,add又有两个选择,于是又选第二个产生式,然后就陷入死循环了。
问题二:二元表达式的结合性的实现。
问题三 :二义性文法为什么也能正常解析?
问题四:“语法”和“文法”有什么区别和联系?
20 | 高效运行:编译器的后端技术
实际上,学完前端技术以后,我们已经能做很多事情了,比如让软件有自定义功能,就像我们在15 讲中提到的报表系统,这时,不需要涉及编译器后端技术。
但很多情况下,我们需要继续把程序编译成机器能读懂的代码,并高效运行。这时,我们就面临了三个问题:
1. 我们必须了解计算机运行一个程序的原理(也就是运行期机制),只有这样,才知道如何生成这样的程序。
2. 要能利用前端生成的 AST 和属性信息,将其正确翻译成目标代码。
3. 需要对程序做尽可能多的优化,比如让程序执行效率更高,占空间更少等等。
弄清程序的运行机制
总的来说,编译器后端要解决的问题是:现在给你一台计算机,你怎么生成一个可以运行的程序,然后还能让这个程序在计算机上正确和高效地运行?
基本上,我们需要面对的是两个硬件:
一个是 CPU,它能接受机器指令和数据,并进行计算。 它里面有寄存器、高速缓存和运算单元,充分利用寄存器和高速缓存会让系统的性能大大提升。
另一个是内存。 我们要在内存里保存编译好的代码和数据,还要设计一套机制,让程序最高效地利用这些内存。
通常情况下,我们的程序要受某个操作系统的管理,所以也要符合操作系统的一些约定。但有时候我们的程序也可能直接跑在硬件上,单片机和很多物联网设备采用这样的结构,甚至一些服务端系统,也可以不跑在操作系统上。
编译器后端技术跟计算机体系结构的关系很密切。我们必须清楚地理解计算机程序是怎么运行的,有了这个基础,才能探讨如何编译生成这样的程序。
也有的时候,我们的面对的机器是虚拟机,Java 的运行环境就是一个虚拟机(JVM),那我们需要就了解这个虚拟机的特点,以便生成可以在这个虚拟机上运行的代码,比如 Java 的字节码。同时,字节码有时仍然需要编译成机器码。
生成代码
编译器后端的最终结果,就是生成目标代码。如果目标是在计算机上直接运行,就像 C 语言程序那样,那这个目标代码指的是汇编代码。而如果运行目标是 Java 虚拟机,那这个目标代码就是指 JVM 的字节码。
你可能惧怕汇编代码,觉得它肯定很难,能写汇编的人一定很牛。在我看来,这是一个偏见,因为汇编代码并不难写,为什么呢?
其实汇编没有类型,也没有那么多的语法结构,它要做的通常就是把数据拷贝到寄存器,处理一下,再保存回内存。所以,从汇编语言的特性看,就决定了它不可能复杂到哪儿去。
写汇编跟使用高级语言有很多不同,其中一点就是要关心 CPU 和内存这样具体的硬件。 比如,你需要了解不同的 CPU 指令集的差别,你还需要知道 CPU 是 64 位的还是 32 位的,有几个寄存器,每个寄存器可以用于什么指令,等等。但这样导致的问题是,每种语言,针对每种不同的硬件,都要生成不同的汇编代码。你想想看,一般我们设计一门语言要支持尽可能多的硬件平台,这样的工作量是不是很庞大?
所以,为了降低后端工作量,提高软件复用度,就需要引入中间代码(Intermediate Representation,IR)的机制,它是独立于具体硬件的一种代码格式。各个语言的前端可以先翻译成 IR,然后再从 IR 翻译成不同硬件架构的汇编代码。如果有 n 个前端语言,m 个后端架构,本来需要做 m*n个翻译程序,现在只需要 m+n 个了。这就大大降低了总体的工作量。
其实,IR 这个词直译成中文,是“中间表示方式”的意思,不一定非是像汇编代码那样的一条条的指令。所以,AST 其实也可以看做一种 IR。我们在前端部分实现的脚本语言,就是基于 AST 这个 IR 来运行的。
每种 IR 的目的和用途是不一样的:
- AST 主要用于前端的工作。
- Java 的字节码,是设计用来在虚拟机上运行的。
- LLVM 的中间代码,主要是用于做代码翻译和编译优化的。
代码分析和优化
生成正确的、能够执行的代码比较简单,可这样的代码执行效率很低,因为直接翻译生成的代码往往不够简洁,比如会生成大量的临时变量,指令数量也较多。因为翻译程序首先照顾的是正确性,很难同时兼顾是否足够优化,这是一方面。另一方面,由于高级语言本身的限制和程序员的编程习惯,也会导致代码不够优化,不能充分发挥计算机的性能。所以我们一定要对代码做优化。
优化工作又分为 “独立于机器的优化”和“依赖于机器的优化” 两种。
独立于机器的优化,是基于 IR 进行的。
依赖于机器的优化,则是依赖于硬件的特征。 现代的计算机硬件设计了很多特性,以便提供更高的处理能力,比如并行计算能力,多层次内存结构(使用多个级别的高速缓存)等等。编译器要能够充分利用硬件提供的性能,比如 :
寄存器优化。 对于频繁访问的变量,最好放在寄存器中,并且尽量最大限度地利用寄存器,不让其中一些空着,有不少算法是解决这个问题的,教材上一般提到的是染色算法;
充分利用高速缓存。 高速缓存的访问速度可以比内存快几十倍上百倍,所以我们要尽量利用高速缓存。比如,某段代码操作的数据,在内存里尽量放在一起,这样 CPU 读入数据时,会一起都放到高速缓存中,不用一遍一遍地重新到内存取。
并行性。 现代计算机都有多个内核,可以并行计算。我们的编译器要尽可能把充分利用多个内核的计算能力。 这在编译技术中是一个专门的领域。
流水线。 CPU 在处理不同的指令的时候,需要等待的时间周期是不一样的,在等待某些指令做完的过程中其实还可以执行其他指令。就比如在星巴克买咖啡,交了钱就可以去等了,收银员可以先去处理下一个顾客,而不是要等到前一个顾客拿到咖啡才开始处理下一个顾客。
指令选择。 有的时候,CPU 完成一个功能,有多个指令可供选择。而针对某个特定的需求,采用 A 指令可能比 B 指令效率高百倍。比如 X86 架构的 CPU 提供 SIMD 功能,也就是一条指令可以处理多条数据,而不是像传统指令那样一条指令只能处理一条数据。在内存计算领域,SIMD 也可以大大提升性能,我们在第 30 讲的应用篇,会针对 SIMD 做一个实验。
其他优化。 比如可以针对专用的 AI 芯片和 GPU 做优化,提供 AI 计算能力,等等。
可以看出来,做好依赖于机器的优化要对目标机器的体系结构有清晰的理解,如果能做好这些工作,那么开发一些系统级的软件也会更加得心应手。实际上,数据库系统、大数据系统等等,都是要融合编译技术的。
刚接触编译技术的时候,你可能会把视线停留在前端技术上,以为能做 Lexer、Parser 就是懂编译了。实际上,词法分析和语法分析比较成熟,有成熟的工具来支撑。相对来说,后端的工作量更大,挑战更多,研究的热点也更多。 比如,人工智能领域又出现了一些专用的 AI 芯片和指令集,就需要去适配。
前端关注的是正确反映了代码含义的静态结构,而后端关注的是让代码良好运行的动态结构。它们之间的差别,从我讲解“作用域”和“生存期”两个概念时就能看出来。作用域是前端的概念,而生存期是后端的概念。
21 | 运行时机制:突破现象看本质,透过语法看运行时
程序运行的环境
程序运行的过程中,主要是跟两个硬件(CPU 和内存)以及一个软件(操作系统)打交道。
本质上,我们的程序只关心 CPU 和内存这两个硬件。你可能说:“不对啊,计算机还有其他硬件,比如显示器和硬盘啊。”但对我们的程序来说,操作这些硬件,也只是执行某些特定的驱动代码,跟执行其他代码并没有什么差异。
CPU 的内部有很多组成部分,对于本课程来说,我们重点关注的是寄存器以及高速缓存, 它们跟程序的执行机制和优化密切相关。
你写程序时,尽量把某个操作所需的数据都放在内存中的连续区域中,不要零零散散地到处放,这样有利于充分利用高速缓存。这种优化思路,叫做数据的局部性。
这里提一句, 在写系统级的程序时,你要对各种 IO 的时间有基本的概念,比如高速缓存、内存、磁盘、网络的 IO 大致都是什么数量级的。因为这都影响到系统的整体性能,也影响到你如何做程序优化。如果你需要对程序做更多的优化,还需要了解更多的 CPU 运行机制,包括流水线机制、并行机制等等,这里就不展开了
大多数语言还是会采用一些通用的内存管理模式。以 C 语言为例,会把内存划分为代码区、静态数据区、栈和堆。

程序和操作系统的关系
程序跟操作系统的关系比较微妙:
- 一方面我们的程序可以编译成不需要操作系统也能运行,就像一些物联网应用那样,完全跑在裸设备上。
- 另一方面,有了操作系统的帮助,可以为程序提供便利,比如可以使用超过物理内存的存储空间,操作系统负责进行虚拟内存的管理。
在存在操作系统的情况下,因为很多进程共享计算机资源,所以就要遵循一些约定。这就仿佛办公室是所有同事共享的,那么大家就都要遵守一些约定,如果一个人大声喧哗,就会影响到其他人。
程序需要遵守的约定包括: 程序文件的二进制格式约定,这样操作系统才能程序正确地加载进来,并为同一个程序的多个进程共享代码区。在使用寄存器和栈的时候也要遵守一些约定,便于操作系统在不同的进程之间切换的时候、在做系统调用的时候,做好上下文的保护。
所以,我们编译程序的时候,要知道需要遵守哪些约定。因为就算是使用同样的 CPU,针对不同的操作系统,编译的结果也是非常不同的。
程序运行的过程

22 | 生成汇编代码(一):汇编语言其实不难学
就算像 JavaScript 这样的解释执行的语言,也要在运行时利用类似的机制生成机器码,以便调高执行的速度。Java 的字节码,在运行时通常也会通过 JIT 机制编译成机器码。而汇编语言是完成这些工作的基础。
了解汇编语言
机器语言都是 0101 的二进制的数据,不适合我们阅读。而汇编语言,简单来说,是可读性更好的机器语言,基本上每条指令都可以直接翻译成一条机器码。
汇编语言的语法特别简单,但它要跟硬件(CPU 和内存)打交道。
计算机的处理器有很多不同的架构,比如 x86-64、ARM、Power 等,每种处理器的指令集都不相同,那也就意味着汇编语言不同。
1.汇编语言的组成元素
这段代码里有指令、伪指令、标签和注释四种元素,每个元素单独占一行。
- 指令(instruction)是直接由 CPU 进行处理的命令
- 伪指令以“.”开头,末尾没有冒号“:”。伪指令是是辅助性的,汇编器在生成目标文件时会用到这些信息,但伪指令不是真正的 CPU 指令,就是写给汇编器的。每种汇编器的伪指令也不同,要查阅相应的手册
- 标签以冒号“:”结尾,用于对伪指令生成的数据或指令做标记。标签很有用,它可以代表一段代码或者常量的地址
课程小结
本节课,我讲解了汇编语言的一些基础知识,由于汇编语言的特点,涉及的知识点和细节比较多,在这个过程中,你无需死记硬背,只需要掌握几个重点内容:
1. 汇编语言是由指令、标签、伪指令和注释构成的。其中主要内容都是指令。指令包含一个该指令的助记符和操作数。操作数可以使用直接数、寄存器,以及用两种方式访问内存地址。
2. 汇编指令中会用到一些通用寄存器。这些寄存器除了用于计算以外,还可以根据调用约定帮助传递参数和返回值。使用寄存器时,要区分由调用者还是被调用者负责保护寄存器中原来的内容。
23 | 生成汇编代码(二):把脚本编译成可执行文件
课程小结
这节课,我们实现了从 AST 到汇编代码,汇编代码到可执行文件的完整过程。现在,你应该对后端工作的实质建立起了直接的认识。我建议你抓住几个关键点:
首先,从 AST 生成汇编代码,可以通过比较机械的翻译来完成,我们举了加法运算的例子。阅读示例程序,你也可以看看函数调用、参数传递等等的实现过程。总体来说,这个过程并不难。
第二,这种机械地翻译生成的代码,一定是不够优化的。我们已经看到了加法运算不够优化的情况,所以一定要增加一个优化的过程。
第三,在生成汇编的过程中,最需要注意的就是要遵守调用约定。这就需要了解调用约定的很多细节。只要遵守调用约定,不同语言生成的二进制目标文件也可以链接在一起,形成最后的可执行文件。
24 | 中间代码:兼容不同的语言和硬件
IR 的作用:我们能基于 IR 对接不同语言的前端,也能对接不同的硬件架构,还能做很多的优化。
介于中间的语言
IR 的意思是中间表达方式,它在高级语言和汇编语言的中间,这意味着,它的特征也是处于二者之间的。
与高级语言相比,IR 丢弃了大部分高级语言的语法特征和语义特征,比如循环语句、if 语句、作用域、面向对象等等,它更像高层次的汇编语言;而相比真正的汇编语言,它又不会有那么多琐碎的、与具体硬件相关的细节。
IR 不会像 x86-64 汇编语言那么繁琐,但它却包含了足够的细节信息,能方便我们实现优化算法,以及生成针对目标机器的汇编代码。
另外,我在 20 讲提到,IR 有很多种类(AST 也是一种 IR),每种 IR 都有不同的特点和用途,有的编译器,甚至要用到几种不同的 IR。
我们在后端部分所讲的 IR,目的是方便执行各种优化算法,并有利于生成汇编。这种 IR,可以看做是一种高层次的汇编语言,主要体现在:
- 它可以使用寄存器,但寄存器的数量没有限制;
- 控制结构也跟汇编语言比较像,比如有跳转语句,分成多个程序块,用标签来标识程序块等;
- 使用相当于汇编指令的操作码。这些操作码可以一对一地翻译成汇编代码,但有时一个操作码会对应多个汇编指令。
认识典型的 IR:三地址代码(Three Address Code, TAC)
每条三地址代码最多有三个地址,其中两个是源地址(比如第一行代码的 y 和 z),一个是目的地址(也就是 x),每条代码最多有一个操作(op)。
x := y op z // 二元操作
x := op y // 一元操作基本的算术运算
int a, b, c, d;
a = b + c * d;
t1 := c * d
a := b + t1 布尔值的计算
int a, b;
bool x, y;
x = a * 2 < b;
y = a + 3 == b;
t1 := a * 2;
x := t1 < b;
t2 := a + 3;
y := t2 == b;条件语句:
int a, b c;
if (a < b )
c = b;
else
c = a;
c = c * 2;
t1 := a < b;
IfZ t1 Goto L1;
c := a;
Goto L2;
L1:
c := b;
L2:
c := c * 2; 循环语句
int a, b;
while (a < b){
a = a + 1;
}
a = a + b;
L1:
t1 := a < b;
IfZ t1 Goto L2;
a := a + 1;
Goto L1;
L2:
a := a + b; 在课程中,三地址代码主要用来描述优化算法,因为它比较简洁易读,操作(指令)的类型很少,书写方式也符合我们的日常习惯。不过,我并不用它来生成汇编代码,因为它含有的细节信息还是比较少, 比如,整数是 16 位的、32 位的还是 64 位的?目标机器的架构和操作系统是什么?生成二进制文件的布局是怎样的等等?
我会用 LLVM 的 IR 来承担生成汇编的任务, 因为它有能力描述与目标机器(CPU、操作系统)相关的更加具体的信息,准确地生成目标代码,从而真正能够用于生产环境。
在讲这个问题之前,我想先延伸一下,讲讲另外几种 IR 的格式, 主要想帮你开拓思维,如果你的项目需求,恰好能用这种 IR 实现,到时不妨拿来用一下:
- 首先是四元式。它是与三地址代码等价的另一种表达方式,格式是:(OP,arg1,arg2,result)所以,“a := b + c” 就等价于(+,b,c,a)。
- 另一种常用的格式是逆波兰表达式。它把操作符放到后面,所以也叫做后缀表达式。“b + c”对应的逆波兰表达式是“b c +”;而“a = b + c”对应的逆波兰表达式是“a b c + =”。
逆波兰表达式特别适合用栈来做计算。 比如计算“b c +”,先从栈里弹出加号,知道要做加法操作,然后从栈里弹出两个操作数,执行加法运算即可。这个计算过程,跟深度优先的遍历 AST 是等价的。所以,采用逆波兰表达式,有可能让你用一个很简单的方式就实现公式计算功能,如果你编写带有公式功能的软件时可以考虑使用它。 而且,从 AST 生成逆波兰表达式也非常容易。
三地址代码主要是学习算法的工具,或者用于实现比较简单的后端,要实现工业级的后端,充分发挥硬件的性能,你还要学习 LLVM 的 IR。
认识 LLVM 汇编码
LLVM 汇编码(LLVM Assembly),是 LLVM 的 IR。有的时候,我们就简单地称呼它为 LLVM 语言
- 首先,LLVM 汇编码是采用静态单赋值代码形式的。
在三地址代码上再加一些限制,就能得到另一种重要的代码,即静态单赋值代码(Static Single Assignment, SSA),在静态单赋值代码中,一个变量只能被赋值一次。为什么要费力写成这种形式呢,还要为此多添加 t1 和 t2 两个临时变量?原因是 SSA 的形式,体现了精确的“使用 - 定义”关系。
- 其次,LLVM IR 比起三地址代码,有更多的细节信息。比如整型变量的字长、内存对齐方式等等,所以使用 LLVM IR 能够更准确地翻译成汇编码。
看看下面这段 C 语言代码:
int fun1(int a, int b){ int c = 10; return a + b + c;}对应的 LLLM 汇编码如下(这是我在 macOS 上生成的):
; ModuleID = 'fun1.c'
source_filename = "fun1.c"
target datalayout = "e-m:o-i64:64-f80:128-n8:16:32:64-S128"
target triple = "x86_64-apple-macosx10.14.0"
; Function Attrs: noinline nounwind optnone ssp uwtable
define i32 @fun1(i32, i32) #0 {
%3 = alloca i32, align 4 // 为 3 个变量申请空间
%4 = alloca i32, align 4
%5 = alloca i32, align 4
store i32 %0, i32* %3, align 4 // 参数 1 赋值给变量 1
store i32 %1, i32* %4, align 4 // 参数 2 赋值给变量 2
store i32 10, i32* %5, align 4 // 常量 10 赋值给变量 3
%6 = load i32, i32* %3, align 4 //
%7 = load i32, i32* %4, align 4
%8 = add nsw i32 %6, %7
%9 = load i32, i32* %5, align 4
%10 = add nsw i32 %8, %9
ret i32 %10
}
attributes #0 = { noinline nounwind optnone ssp uwtable "correctly-rounded-divide-sqrt-fp-math"="false" "disable-tail-calls"="false" "less-precise-fpmad"="false" "no-frame-pointer-elim"="true" "no-frame-pointer-elim-non-leaf" "no-infs-fp-math"="false" "no-jump-tables"="false" "no-nans-fp-math"="false" "no-signed-zeros-fp-math"="false" "no-trapping-math"="false" "stack-protector-buffer-size"="8" "target-cpu"="penryn" "target-features"="+cx16,+fxsr,+mmx,+sahf,+sse,+sse2,+sse3,+sse4.1,+ssse3,+x87" "unsafe-fp-math"="false" "use-soft-float"="false" }
!llvm.module.flags = !{!0, !1, !2}
!llvm.ident = !{!3}
!0 = !{i32 2, !"SDK Version", [2 x i32] [i32 10, i32 14]}
!1 = !{i32 1, !"wchar_size", i32 4}
!2 = !{i32 7, !"PIC Level", i32 2}
!3 = !{!"Apple LLVM version 10.0.1 (clang-1001.0.46.4)"}这些代码看上去确实比三地址代码复杂,但还是比汇编精简多了,比如 LLVM IR 的指令数量连 x86-64 汇编的十分之一都不到。
我们来熟悉一下LLVM里面的元素:
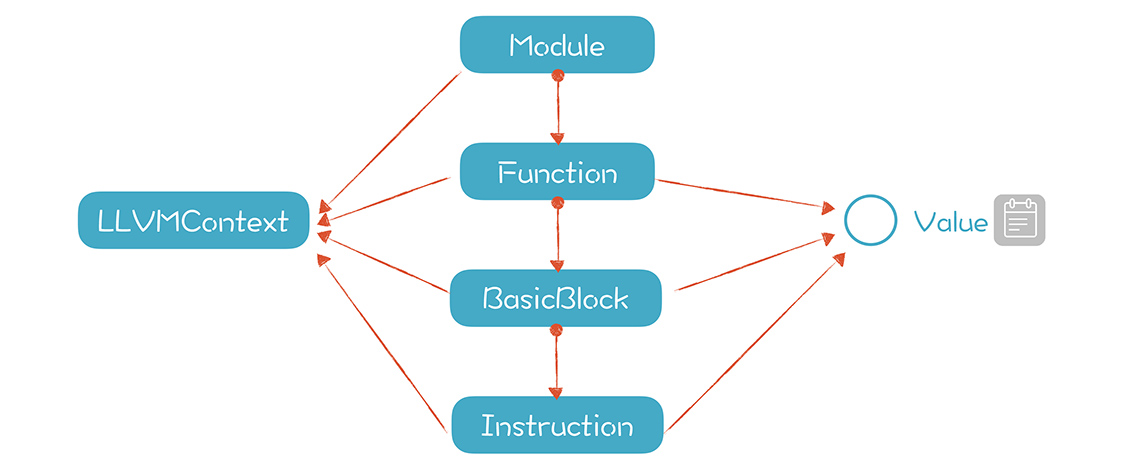
- 模块
LLVM 程序是由模块构成的,这个文件就是一个模块。模块里可以包括函数、全局变量和符号表中的条目。链接的时候,会把各个模块拼接到一起,形成可执行文件或库文件。
- 函数
- 标识符
- 操作码
- 类型系统
- 元数据
- 基本块
这样,你实际上就可以用 LLVM 汇编码来编写程序了,或者将 AST 翻译成 LLVM 汇编码。听上去有点让人犯怵,因为 LLVM 汇编码的细节也相当不少,好在,LLVM 提供了一个 IR 生成的 API(应用编程接口),可以让我们更高效、更准确地生成 IR。
25 | 后端技术的重用:LLVM不仅仅让你高效
两个编译器后端框架:LLVM 和 GCC
LLVM 是一个开源的编译器基础设施项目,主要聚焦于编译器的后端功能(代码生成、代码优化、JIT……)
- LLVM 的出名是由于苹果公司全面采用了这个框架。苹果系统上的 C 语言、C++、Objective-C 的编译器 Clang 就是基于 LLVM 的,最新的 Swift 编程语言也是基于 LLVM,支撑了无数的移动应用和桌面应用。无独有偶,在 Android 平台上最新的开发语言 Kotlin,也支持基于 LLVM 编译成本地代码。
- 由 Mozilla 公司(Firefox 就是这个公司的产品)开发的系统级编程语言 RUST,也是基于 LLVM 开发的。还有一门相对小众的科学计算领域的语言,叫做 Julia,它既能像脚本语言一样灵活易用,又可以具有 C 语言一样的速度,在数据计算方面又有特别的优化,它的背后也有 LLVM 的支撑。
- 在人工智能领域炙手可热的 TensorFlow 框架,在后端也是用 LLVM 来编译。它把机器学习的 IR 翻译成 LLVM 的 IR,然后再翻译成支持 CPU、GPU 和 TPU 的程序
GCC(GNU Compiler Collection,GNU 编译器套件)。它支持了 GNU Linux 上的很多语言,例如 C、C++、Objective-C、Fortran、Go 语言和 Java 语言等。其实,它最初只是一个 C 语言的编译器,后来把公共的后端功能也提炼了出来,形成了框架,支持多种前端语言和后端平台。最近华为发布的方舟编译器,据说也是建立在 GCC 基础上的。
LLVM入门
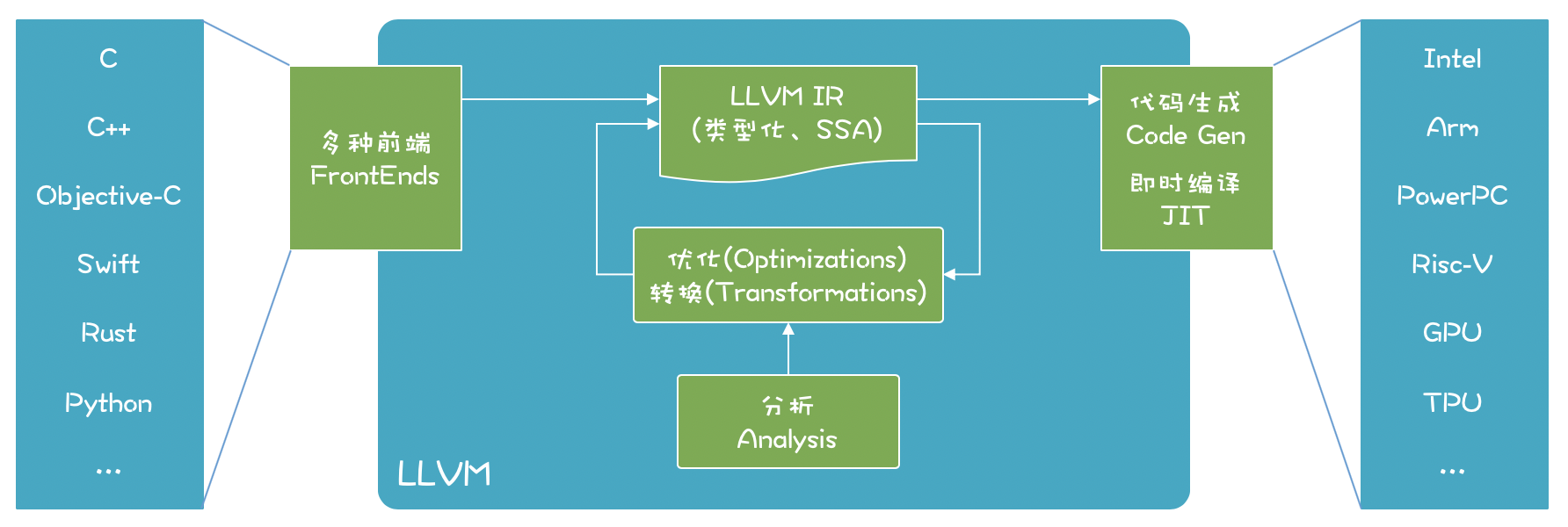
LLVM 项目包含了很多组成部分:
- LLVM 核心(core)。就是上图中的优化和分析工具,还包括了为各种 CPU 生成目标代码的功能;这些库采用的是 LLVM IR,一个良好定义的中间语言,在上一讲,我们已经初步了解它了。
- Clang 前端(是基于 LLVM 的 C、C++、Objective-C 编译器)。
- LLDB(一个调试工具)。
- LLVM 版本的 C++ 标准类库。
- 其他一些子项目。
我个人很喜欢 LLVM,想了想,主要有几点原因:
首先,LLVM 有良好的模块化设计和接口。以前的编译器后端技术很难复用,而 LLVM 具备定义了良好接口的库,方便使用者选择在什么时候,复用哪些后端功能。比如,针对代码优化,LLVM 提供了很多算法,语言的设计者可以自己选择合适的算法,或者实现自己特殊的算法,具有很好的灵活性。
第二,LLVM 同时支持 JIT(即时编译)和 AOT(提前编译)两种模式。过去的语言要么是解释型的,要么编译后运行。习惯了使用解释型语言的程序员,很难习惯必须等待一段编译时间才能看到运行效果。很多科学工作者,习惯在一个 REPL 界面中一边写脚本,一边实时看到反馈。LLVM 既可以通过 JIT 技术支持解释执行,又可以完全编译后才执行,这对于语言的设计者很有吸引力。
第三,有很多可以学习借鉴的项目。Swift、Rust、Julia 这些新生代的语言,实现了很多吸引人的特性,还有很多其他的开源项目,而我们可以研究、借鉴它们是如何充分利用 LLVM 的。
第四,全过程优化的设计思想。LLVM 在设计上支持全过程的优化。Lattner 和 Adve 最早关于 LLVM 设计思想的文章《LLVM: 一个全生命周期分析和转换的编译框架》,就提出计算机语言可以在各个阶段进行优化,包括编译时、链接时、安装时,甚至是运行时。
以运行时优化为例,基于 LLVM 我们能够在运行时,收集一些性能相关的数据对代码编译优化,可以是实时优化的、动态修改内存中的机器码;也可以收集这些性能数据,然后做离线的优化,重新生成可执行文件,然后再加载执行,这一点非常吸引我, 因为在现代计算环境下,每种功能的计算特点都不相同,确实需要针对不同的场景做不同的优化。
第五,LLVM 的授权更友好。GNU 的很多软件都是采用 GPL 协议的,所以如果用 GCC 的后端工具来编写你的语言,你可能必须要按照 GPL 协议开源。而 LLVM 则更友好一些,你基于 LLVM 所做的工作,完全可以是闭源的软件产品。
LLVM 的 IR 有两种格式。 第一种文本格式,文件名一般以.ll 结尾。第二种格式是字节码(bitcode)格式,文件名以.bc 结尾。为什么要用两种格式呢? 因为文本格式的文件便于程序员阅读,而字节码格式的是二进制文件,便于机器处理,比如即时编译和执行。生成字节码格式之后,所占空间会小很多,所以可以快速加载进内存,并转换为内存中的对象格式。而如果加载文本文件,则还需要一个解析的过程,才能变成内存中的格式,效率比较慢。
LLVM 的一个优点,就是可以即时编译运行字节码,不一定非要编译生成汇编码和可执行文件才能运行(这一点有点儿像 Java 语言),这也让 LLVM 具有极高的灵活性,比如,可以在运行时根据收集的性能信息,改变优化策略,生成更高效的机器码。
实际上,使用 LLVM 从源代码到生成可执行文件有两条可能的路径:
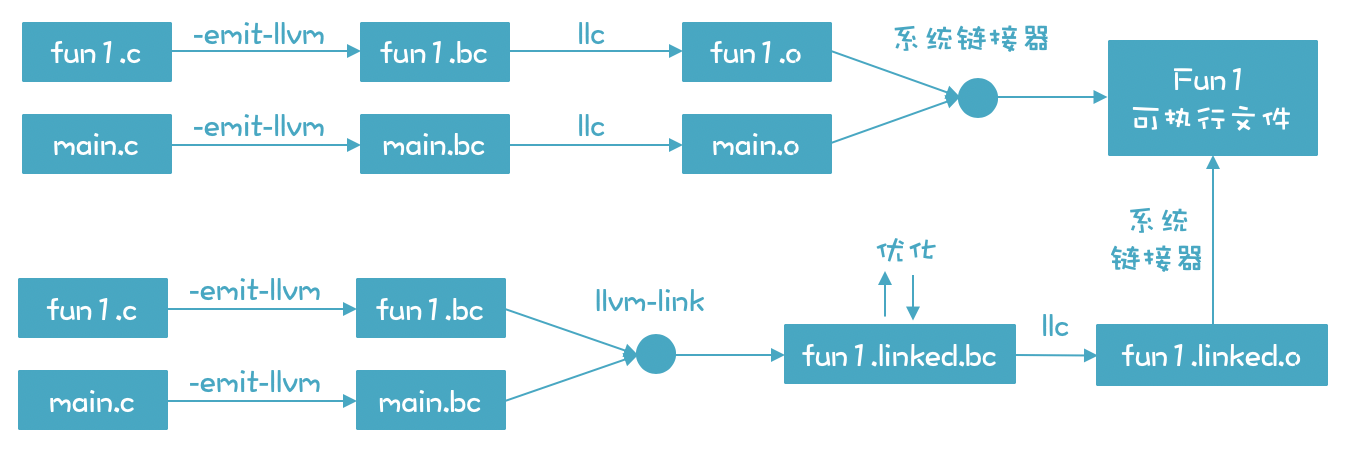
- 第一条路径,是把每个源文件分别编译成字节码文件,然后再编译成目标文件,最后链接成可执行文件。
- 第二条路径,是先把编译好的字节码文件链接在一起,形成一个更大的字节码文件,然后对这个字节码文件进行进一步的优化,之后再生成目标文件和可执行文件。
第二条路径比第一条路径多了一个优化的步骤,第一条路径只对每个模块做了优化,没有做整体的优化。所以,如有可能,尽量采用第二条路径,这样能够生成更加优化的代码。
LLVM 本身是用 C++ 开发的,所以最好采用 C++ 调用它的功能
当然,采用其他语言也有办法调用 LLVM:
- C 语言可以调用专门的 C 接口;
- 像 Go、Rust、Python、Ocaml、甚至 Node.js 都有对 LLVM API 的绑定;
- 如果使用 Java,也可以通过 JavaCPP(类似 JNI)技术调用 LLVM。
26 | 生成IR:实现静态编译的语言
如果我们要像前面生成汇编语言那样,通过字符串拼接来生成 LLVM 的 IR,除了要了解 LLVM IR 的很多细节之外,代码一定比较啰嗦和复杂,因为字符串拼接不是结构化的方法,所以,最好用一个定义良好的数据结构来表示 IR。
好在 LLVM 项目已经帮我们考虑到了这一点,它提供了代表 LLVM IR 的一组对象模型,我们只要生成这些对象,就相当于生成了 IR,这个难度就低多了。而且,LLVM 还提供了一个工具类,IRBuilder,我们可以利用它,进一步提升创建 LLVM IR 的对象模型的效率,让生成 IR 的过程变得更加简单!
LLVM IR 的对象模型
LLVM 在内部有用 C++ 实现的对象模型,能够完整表示 LLVM IR,当我们把字节码读入内存时,LLVM 就会在内存中构建出这个模型。只有基于这个对象模型,我们才可以做进一步的工作,包括代码优化,实现即时编译和运行,以及静态编译生成目标文件。所以说,这个对象模型是 LLVM 运行时的核心。
本节课,我们我们完成了从生成 IR 到编译执行的完整过程,同时,也初步熟悉了 LLVM 的接口。当然了,完全熟悉 LLVM 的接口还需要多做练习,掌握更多的细节。就本节课而言,我希望你掌握的重点如下:
- LLVM 用一套对象模型在内存中表示 IR,包括模块、函数、基本块和指令,你可以通过 API 来生成这些对象。这些对象一旦生成,就可以编译和执行。
- 对于 if 语句和循环语句,需要生成多个基本块,并通过跳转指令形成正确的控制流图(CFG)。当存在多个前序节点可能改变某个变量的值的时候,使用 phi 指令来确定正确的值。
- 存储在内存中的本地变量,可以多次赋值。
- LLVM 能够把外部函数和 IR 模型中的函数等价对待。
27 | 代码优化:为什么你的代码比他的更高效?
问题:
* 代码优化的目标是什么?除了性能上的优化,还有什么优化?
* 代码优化可以在多大的范围内执行?是在一个函数内,还是可以针对整个应用程序?
* 常见的代码优化场景有哪些?
了解代码优化的目标、对象、范围和策略
代码优化的目标:
CPU利用率(主要)、代码大小、内存占用大小、磁盘访问次数、网络通讯次数等等
代码优化的对象:
大多数的代码优化都是在 IR 上做的,而不是在前一阶段的 AST 和后一阶段汇编代码上进行的
在 AST上抽象层次太高,含有的硬件架构信息太少。在汇编代码上进行优化会让算法跟机器相关,当换一个目标机器的时候,还要重新编写优化代码。
代码优化的范围
从优化的范围看,分为:
本地优化
针对基本块进行优化
全局优化
如果通过分析 控制流图(Control Flow Graph,CFG),我们发现 t 在其他地方没有被使用,就可以把第二行删掉。这种针对一个函数、基于 CFG 的优化,叫做全局优化(Global Optimization)
过程间优化
它能跨越函数的边界,对多个函数之间的关系进行优化,而不是仅针对一个函数做优化。
代码优化的策略
你不需要每次都把代码优化做彻底,因为做代码优化本身也需要消耗计算机的资源。
所以,你需要权衡代码优化带来的好处和优化本身的开支这两个方面,然后确定做多少优化。
一些优化的场景
代数优化(Algebraic Optimazation)
常数折叠(Constant Folding)
删除不可达的基本块
删除公共子表达式(Common Subexpression Elimination)
拷贝传播(Copy Propagation)和常数传播(Constant Propagation)
死代码删除(Ded code elimintation)
多次优化
一个优化可能导致另一个需优化的地方,比如,拷贝传播导致 y 不再被使用,我们又可以进行死代码删除的优化。所以,一般进行多次优化、多次扫描。
用 LLVM 来演示优化功能
opt -S -O2 fun1.ll -o fun1-O2.ll另外,我解释一下 -O2 参数:-O2 代表的是二级优化,LLVM 中定义了多个优化级别,基本上数字越大,所做的优化就越多。
如何用程序实现 IR 的优化
在 LLVM 内部,优化工作是通过一个个的 Pass(遍)来实现的,它支持三种类型的 Pass:
- 一种是分析型的 Pass(Analysis Passes),只是做分析,产生一些分析结果用于后序操作。
- 一些是做代码转换的(Transform Passes),比如做公共子表达式删除。
- 还有一类 pass 是工具型的,比如对模块做正确性验证。
下面的代码创建了一个 PassManager,并添加了两个优化 Pass:
// 创建一个 PassManager
TheFPM = std::make_unique<legacy::FunctionPassManager>(TheModule.get());
// 窥孔优化和一些位计算优化
TheFPM->add(createInstructionCombiningPass());
// 表达式重关联
TheFPM->add(createReassociatePass());
TheFPM->doInitialization();
TheFPM->run(*fun);课程小结
本节课,我带你学习了代码优化的原理,然后通过 LLVM 实践了一下,演示了优化功能,我希望你能记住几个关键点:
1. 代码优化分为本地优化、全局优化和过程间优化三个范围。有些优化对于这三个范围都是适用的,但也有一些优化算法是全局优化和过程间优化专有的。
2. 可用表达式分析和活跃性分析是本地优化时的两个关键算法。这些算法都是由扫描方向、值、转换函数和初始值这四个要素构成的。
3. LLVM 用 pass 来做优化,你可以通过命令行或程序来使用这些 Pass。你也可以编写自己的 Pass。
28 | 数据流分析:你写的程序,它更懂
全局优化中的算法,不会像在本地优化中一样,只针对一个基本块。而是更复杂一些,因为要覆盖多个基本块。这些基本块构成了一个 CFG,代码在运行时有多种可能的执行路径,这会造成多路径下,值的计算问题,比如活跃变量集合的计算。
当然了,还有些优化只能在全局优化中做,在本地优化中做不了,比如:
- 代码移动(code motion)能够将代码从一个基本块挪到另一个基本块,比如从循环内部挪到循环外部,来减少不必要的计算。
- 部分冗余删除(Partial Redundancy Elimination),它能把一个基本块都删掉。
总之,全局优化比本地优化能做的工作更多,分析算法也更复杂,因为 CFG 中可能存在多条执行路径。不过,我们可以在上一节课提到的本地优化的算法思路上,解决掉多路径情况下,V 值的计算问题。而这种基于 CFG 做优化分析的方法框架,就叫做数据流分析。
课程小结
本节课,我们基于全局优化分析的任务,介绍了数据流分析这个框架,并且介绍了半格这个数学工具。我希望你在本讲记住几个要点:
- 全局分析比本地分析多处理的部分就是 CFG,因为有了多条执行分支,所以要计算分支相遇时的值,当 CFG 存在环路的时候,要用不动点法来计算出所有的 V 值。
- 数据流分析框架包含方向(D)、值(V)、转换函数(F)、初始值(I)和交运算(Λ)5 个元素,只要分析清楚这 5 个元素,就可以按照固定的套路来编写分析程序。
- 对于半格理论,关键是要知道如何比较偏序集中元素的大小,理解了这个核心概念,那么求最大下界、最小上界这些也就没有问题了。
数据流分析也是一个容易让学习者撞墙的知识点,特别是再加上“半格”这样的数学术语的时候。不过,我们通过全局活跃性分析和全局常数传播的示例,对“半格”的抽象数学概念建立了直觉的理解。遇到全局分析的任务,你也应该能够比照这两个示例,设计出完整的数据流分析的算法了。不过我建议你,还是要按照上一讲中对 LLVM 优化功能的介绍,多做几个例子实验一下。
29 | 目标代码的生成和优化(一):如何适应各种硬件架构?
一个正式的编译器后端,代码生成部分需要考虑得更加严密才可以。
那么具体要考虑哪些问题呢?其实主要有三点:
- 指令的选择。同样一个功能,可以用不同的指令或指令序列来完成,而我们需要选择比较优化的方案。
- 寄存器分配。每款 CPU 的寄存器都是有限的,我们要有效地利用它。
- 指令重排序。计算执行的次序会影响所生成的代码的效率。在不影响运行结果的情况下,我们要通过代码重排序获得更高的效率。
- 这种算法很幼稚(机械的生成代码),正确性没有问题,但代码量太大,代价太高。所以我们最好用聪明一点儿的算法来生成更加优化的代码。这是我们要做指令选择的原因之一。
- 做指令选择的第二个原因是,实现同一种功能可以使用多种指令,特别是 CISC 指令集(可替代的选择很多,但各自有适用的场景)。
在这里我想再次强调一下,无论是为了生成更简短的代码,还是从多种可能的指令中选择最优的,我们确实需要关注指令的选择。那么,我们做指令选择的思路是什么呢?目前最成熟的算法都是基于树覆盖的方法,我通过一个例子带你了解一下,什么是树覆盖算法。
分配寄存器
寄存器优化的任务是:最大程度地利用寄存器,但不要超过寄存器总数量的限制。
因为我们生成 IR 时,是不知道目标机器的信息的,也就不知道目标机器到底有几个寄存器可以用,所以我们在 IR 中可以使用无限个临时变量,每个临时变量都代表一个寄存器。
现在既然要生成针对目标机器的代码,也就知道这些信息了,那么就要把原来的 IR 改写一下,以便使用寄存器时不超标。
课程小结
目标代码生成过程中有三个关键知识点:指令选择、寄存器分配和指令重排序,本节课,我讲了前两个,期望能帮你理解这两个问题的实质,让你对指令选择和寄存器分配这两个问题建立直观理解。这样你再去研究不同的算法时,脑海里会有这两个概念的顶层的、图形化的认识,事半功倍。与此同时,本节课我希望你记住几个要点如下:
相同的 IR 可以由不同的机器指令序列来实现。你要理解瓦片为什么长那个样子,并且在大脑里建立用瓦片覆盖一棵 AST 的直观印象,最好具备多种覆盖方式,从而把这个问题由抽象变得具象。
寄存器分配是编译器必须要做的一项工作,它把可以使用无限多寄存器的 IR,变成了满足物理寄存器数量的 IR,超出的要溢出到内存中保管。染色算法是其中一个可行的算法。
30 | 目标代码的生成和优化(二):如何适应各种硬件架构?
LLVM 的实现
LLVM 的后端需要多个处理步骤来生成目标代码:
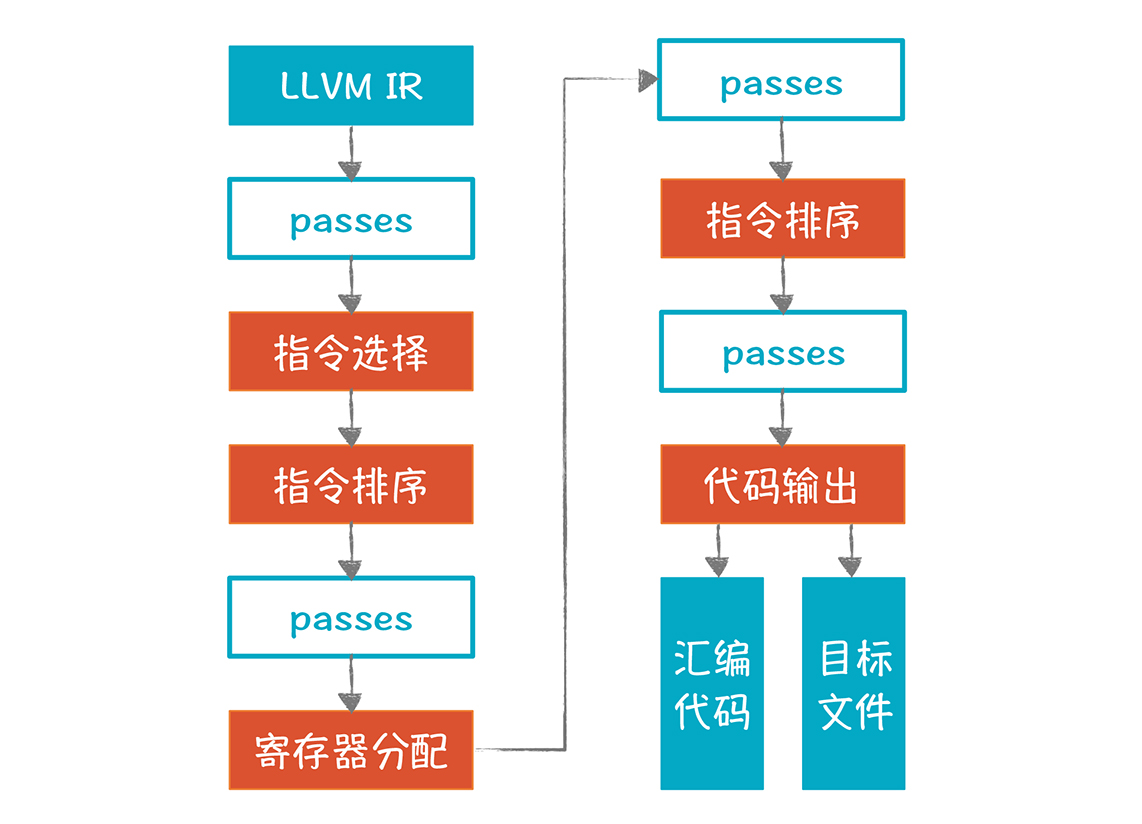
图中橙色的部分是重要的步骤,它本身包含了多个 Pass,所以也叫做超级 Pass。图中蓝框的 Pass,是用来做一些额外的优化处理
课程小结
本节课,我讲解了目标代码生成的第三个主题:指令重排序。
- 要理解这个主题,你首先要知道 CPU 内部是分成多个功能部件的,要知道一条指令的执行过程中,指令获取、解码、执行、访问数据都是如何发生的,这样你会知道指令级并行的原理。
- 其次,从算法角度,你要知道 List Scheduling 的步骤,掌握基于最大时延的优先级计算策略。有了这个基础之后,你可以进一步地研究其他算法。
我想强调的是,指令选择、寄存器分配、指令重排序这三个领域的算法,都是“NP- 完全”的,所以寻找优化的算法,是这个领域最富有挑战的任务。要研究清楚这些算法,你需要阅读相关的资料,比如本讲推荐的论文和其他该领域的经典论文。
加餐 | 汇编代码编程与栈帧管理
31 | 内存计算:对海量数据做计算,到底可以有多快?
内存计算是近十几年来,在数据库和大数据领域的一个热点。随着内存越来越便宜,CPU 的架构越来越先进,整个数据库都可以放在内存中,并通过 SIMD 和并行计算技术,来提升数据处理的性能。
了解 SIMD
SIMD的实际作用主要有以下几点:
- SIMD 有助于多媒体的处理,比如在电脑上流畅地播放视频,或者开视频会议;
- 在游戏领域,图形渲染主要靠 GPU,但如果你没有强大的 GPU,还是要靠 CPU 的 SIMD 指令来帮忙;
- 在商业领域,数据库系统会采用 SIMD 来快速处理海量的数据;
- 人工智能领域,机器学习需要消耗大量的计算量,SIMD 指令可以提升机器学习的速度。
- 你平常写的程序,编译器也会优化成,尽量使用 SIMD 指令来提高性能。
所以,我们所用到的程序,其实天天在都在执行 SIMD 指令。
课程小结
本节课,我带你了解了内存计算的特点,以及与编译技术的关系,我希望你能记住几点:
- SIMD 是一种指令级并行技术,它能够矢量化地一次计算多条数据,从而提升计算性能,在计算密集型的需求中,比如多媒体处理、海量数据处理、人工智能、游戏等领域,你可以考虑充分利用 SIMD 技术。
- 充分保持程序的局部性,能够更好地利用计算机的高速缓存,从而提高程序的性能。
- SIMD,加上数据局部性,和多个 CPU 内核的并行处理能力,再加上低价的海量的内存,推动了内存计算技术的普及,它能够同时满足计算密集,和海量数据的需求。
- 有时候,我们必须在运行期,根据一些数据来做优化,生成更优的目标代码,在编译期不可能做到尽善尽美。
32 | 字节码生成:为什么Spring技术很强大?
Java 程序员几乎都了解 Spring。它的 IoC(依赖反转)和 AOP(面向切面编程)功能非常强大、易用。而它背后的字节码生成技术(在运行时,根据需要修改和生成 Java 字节码的技术)就是就是一项重要的支撑技术。
Java 字节码能够在 JVM(Java 虚拟机)上解释执行,或即时编译执行。其实,除了 Java,JVM 上的 Groovy、Kotlin、Closure、Scala 等很多语言,也都需要生成字节码。另外,playscript 也可以生成字节码,从而在 JVM 上高效地运行!
而且,字节码生成技术很有用。你可以用它将高级语言编译成字节码,还可以向原来的代码中注入新代码,来实现对性能的监测等功能。
而虚拟机的设计又有两种技术:一是基于栈的虚拟机;二是基于寄存器的虚拟机。
指令的操作数是由栈确定的,我们不需要为每个操作数显式地指定存储位置,所以指令可以比较短,这是栈机的一个优点。
例子:
public class MyClass {
public int foo(int a){
return a + 3;
}
}
public int foo(int);
Code:
0: iload_1 // 把下标为 1 的本地变量入栈
1: iconst_3 // 把常数 3 入栈
2: iadd // 执行加法操作
3: ireturn // 返回与此对应的是基于寄存器的虚拟机。这类虚拟机的运行机制跟机器码的运行机制是差不多的,它的指令要显式地指出操作数的位置(寄存器或内存地址)。它的优势是:可以更充分地利用寄存器来保存中间值,从而可以进行更多的优化。
例如,当存在公共子表达式时,这个表达式的计算结果可以保存在某个寄存器中,另一个用到该公共子表达式的指令,就可以直接访问这个寄存器,不用再计算了。在栈机里是做不到这样的优化的,所以基于寄存器的虚拟机,性能可以更高。而它的典型代表,是 Google 公司为 Android 开发的 Dalvik 虚拟机
java字节码生成工具 asm
其实,有很多工具会帮我们生成字节码,比如 Apache BCEL、Javassist 等,选择 asm 是因为它的性能比较高,并且它还被 Spring 等著名软件所采用。
asm是一个开源的字节码生成工具。Grovvy 语言就是用它来生成字节码的,它还能解析 Java 编译后生成的字节码,从而进行修改。
asm 解析字节码的过程,有点像 xml 的解析器解析 xml 的过程:先解析类,再解析类的成员,比如类的成员变量(Field)、类的方法(Mothod)。在方法里,又可以解析出一行行的指令。
你需要掌握两个核心的类的用法:
- ClassReader,用来解析字节码。
- ClassWriter,用来生成字节码。
这两个类如果配合起来用,就可以一边读入,做一定修改后再写出,从而实现对原来代码的修改。
Spring 与字节码生成技术
Spring 的 AOP 是基于代理(proxy)的机制实现的。在调用某个对象的方法之前,要先经过代理,在代理这儿,可以进行安全检查、记日志、支持事务等额外的功能。
Spring 采用的代理技术有两个:一个是 Java 的动态代理(dynamic proxy)技术;一个是采用 cglib 自动生成代理,cglib 采用了 asm 来生成字节码。
Java 的动态代理技术,只支持某个类所实现的接口中的方法。如果一个类不是某个接口的实现,那么 Spring 就必须用到 cglib,从而用到字节码生成技术来生成代理对象的字节码。
33 | 垃圾收集:能否不停下整个世界?
课程小结
垃圾收集是高级语言的重要特征,我们针对垃圾收集,探讨了它的原理和常见的算法,我希望你记住以下几点:
- 内存垃圾是从根节点不能到达的对象。
- 标记 - 清除算法中,你要记住不占额外的内存来做标记的技巧,也就是指针逆转。
- 停止 - 拷贝算法比较适合活对象比例比较低的情况,因为只需要拷贝少量对象。
- 引用计数的方法比较简单,但不能处理循环引用的情况,所以可以考虑跟其他算法配合。
- 分代收集算法非常有效,关键在于计算老一代中的根节点。
- 增量收集和并发收集是当前的前沿,因为它能解决垃圾收集中最大的痛点,时延问题
- LLVM 给垃圾收集提供安全点、栈图、读写屏障方面的支持,GC 要跟编译器配合才能很好的工作。
总之,垃圾收集是一项很前沿的技术,如果你有兴趣在这方面做些工作,有一些开源的 GC 可以参考。不过,就算不从事 GC 的编写,仅仅了解原理,也会有助于你更好地使用自己的语言,比如把 Java 和 Go 语言做好调优。
34 | 运行时优化:即时编译的原理和作用
前面所讲的编译过程,都存在一个明确的编译期,编译成可执行文件后,再执行,这种编译方式叫做提前编译(AOT, Ahead-of-Time Compilation)。 与之对应的,另一个编译方式是即时编译(JIT, Just-in-Time Compilation),也就是,在需要运行某段代码的时候,再去编译。其实,Java、JavaScript 等语言,都是通过即时编译来提高性能的。
一般来说,一个稍微大点儿的程序,静态编译一次,花费的时间很长,而这个等待时间是很煎熬的。如果采用 JIT 机制,你的程序就可以像,解释执行的程序一样,马上运行,得到反馈结果。
其次,JIT 能保证代码的可移植性。
最后,JIT 是编译成机器码的,在这个过程中,可以进行深度的优化,因此程序的性能要比解释执行高很多。
而从实际应用来看,原来一些解释执行的语言,后来也采用 JIT 技术,优化其运行机制,在保留即时运行、可移植的优点的同时,又提升了运行效率,JavaScript 就是其中的典型代表。基于谷歌推出的 V8 开源项目,JavaScript 的性能获得了极大的提升,使基于 Web 的前端应用的体验,越来越好,这其中就有 JIT 的功劳。
JIT原理
在静态编译的情况下,应用程序会被操作系统加载,目标代码被放到了代码区。从安全角度出发,操作系统给每个内存区域,设置了不同的权限,代码区具备可执行权限,所以我们才能运行程序。
在 JIT 的情况下,我们需要为这种动态生成的目标代码,申请内存,并给内存设置可执行权限
用 mmap 申请 9 个字节的一块内存。用这个函数(不是 malloc 函数)的好处是,可以指定内存的权限。我们先让它的权限是可读可写的。
然后用 memcp 函数,把刚才那 9 个字节的数组,拷贝到,所申请的内存块中。
用 mprotect 函数,把内存的权限,修改为可读和可执行。
再接着,用一个int(*)(int) 型的函数指针,指向这块内存的起始地址,也就是说,该函数有一个 int 型参数,返回值也是 int。
最后,通过这个函数指针,调用这段机器码,比如 fun(1)。你打印它的值,看看是否符合预期。
LLVM 对即时编译提供了很好的支持,它大致的机制是这样的:
我们编写的任何模块 (Module),都以内存 IR 的形式存在,LLVM 会把模块中的符号,都统一保存到符号表中。当程序要调用模块的方法时,这个模块就会被即时编译,形成可重定位的目标对象,并被调用执行。动态链接库中的方法(如 printf)也能够被重定位并调用。
课程小结
对现代编程语言来说,编译期和运行期的界限,越来越模糊了,解释型语言和编译型语言的区别,也越来越模糊了。即时编译技术可以生成,最满足你需求的目标代码。那么通过今天的内容,我强调这样几点:
为了实现 JIT 功能,你可以动态申请内存,加载目标代码到内存,并赋予内存可执行的权限。在这个过程中,你要注意安全因素。比如,向内存写完代码以后,要取消写权限。
可重定位的目标代码,加上动态链接技术,让 JIT 产生的代码可以互相调用,以及调用共享库的功能。
JIT 技术可以让数据库这类基础软件,获得性能上的提升,如果你有志参与研发这类软件,掌握 JIT 技术会给你加分很多
35 | 案例总结与热点问题答疑:后端部分真的比前端部分难吗?
- 后端技术部分真的比前端技术部分难吗?
- 怎样更好地理解栈和栈桢(有几个同学提出的问题很好,有必要在这里探究一下)?这样,你对栈桢的理解会更加扎实。
- 有关数据流分析框架。数据流分析是后端技术的几个重点之一,需要再细化一下。
- 关于 Java 的两个知识点:泛型和反射。我会从编译技术的角度讲一讲。
从编译技术的角度看,实现反射很容易。因为在32 讲中,你已经了解了字节码的结构。当时,我比较侧重讲指令,其实你还会看到它前面的,完整的符号表(也就是记录了类名、方法名等信息)。正因为有这些信息,所以反编译工具能够从字节码重新生成 Java 的源文件。
所以,虽然在运行时,Java 类已经编译成字节码了,但我们仍然可以列出它所有的方法,可以实例化它,可以执行它的方法(因为可以查到方法的入口地址)。所以你看,一旦你掌握了底层机制,理解上层的一些特性就很容易了。
36 | 当前技术的发展趋势以及其对编译技术的影响
为了拓展你的视野,我带你探讨了三个技术的发展趋势,以及它们对编译技术和编程方式所带来的影响。我希望,在学完本节课之后,你能有以下收获:
人工智能有可能提升现有的编译技术框架,并带来自动编程等,编程模式的重大变化。
应用程序的运行环境,不能仅仅考虑单机,还要考虑云这个更大的环境。因此,新一代的编程语言和开发平台,可能会让开发云原生的应用更加简单。
在应用开发的前端技术方面,如果要想支持多种平台,可能还需要通过编译技术来获得大的突破