 忧郁的大能猫
忧郁的大能猫
好奇的探索者,理性的思考者,踏实的行动者。
blog/A-IT/00-CS基础/30-编译原理/编译原理实战课
Table of Contents:
- 开篇词 | 在真实世界的编译器中游历
- 01 | 编译的全过程都悄悄做了哪些事情?
- 02 | 词法分析:用两种方式构造有限自动机
- 03 | 语法分析:两个基本功和两种算法思路
- 04 | 语义分析:让程序符合语义规则
- 05 | 运行时机制:程序如何运行,你有发言权
- 06 | 中间代码:不是只有一副面孔
- 07 | 代码优化:跟编译器做朋友,让你的代码飞起来
- 08 | 代码生成:如何实现机器相关的优化?
- 09 | Java编译器(一):手写的编译器有什么优势?
- 10 | Java编译器(二):语法分析之后,还要做些什么?
- 11 | Java编译器(三):属性分析和数据流分析
- 12 | Java编译器(四):去除语法糖和生成字节码
- 13 | Java JIT编译器(一):动手修改Graal编译器
- 14 | Java JIT编译器(二):Sea of Nodes为何如此强大?
- 15 | Java JIT编译器(三):探究内联和逃逸分析的算法原理
- 16 | Java JIT编译器(四):Graal的后端是如何工作的?
- 17 | Python编译器(一):如何用工具生成编译器?
- 18 | Python编译器(二):从AST到字节码
- 19 | Python编译器(三):运行时机制
- 20 | JavaScript编译器(一):V8的解析和编译过程
- 课程小结
- 21 | JavaScript编译器(二):V8的解释器和优化编译器
- 22 | Julia编译器(一):如何让动态语言性能很高?
- 24 | Go语言编译器:把它当作教科书吧
- 25 | MySQL编译器(一):解析一条SQL语句的执行过程
- 26 | MySQL编译器(二):编译技术如何帮你提升数据库性能?
- 27 | 课前导读:学习现代语言设计的正确姿势
- 28 | 前端总结:语言设计也有人机工程学
- 29 | 中端总结:不遗余力地进行代码优化
- 30 | 后端总结:充分发挥硬件的能力
- 31 | 运行时(一):从0到语言级的虚拟化
- 32 | 运行时(二):垃圾收集与语言的特性有关吗?
RichardGong/CompilersInPractice - Gitee.com
开篇词 | 在真实世界的编译器中游历
为什么要解析真实编译器?
说到把编译技术的知识与实践相结合,无外乎就是解决以下问题:
- 我已经知道,语法分析有自顶向下的方法和自底向上的方法,但要自己动手实现的话,到底该选择哪个方法呢?是应该自己手写,还是用工具生成呢?
- 我已经知道,在语义分析的过程中要做引用消解、类型检查,并且会用到符号表。那具体到自己熟悉的语言,这些工作是如何完成的呢?有什么难点和实现技巧呢?符号表又被设计成什么样子呢?
- 我已经知道,编译器中会使用 IR,但实际使用中的 IR 到底是什么样子的呢?使用什么数据结构呢?完成不同的处理任务,是否需要不同的 IR 呢?
- 我已经知道,编译器要做很多优化工作,但针对自己熟悉的语言,这些优化是如何发生的?哪些优化最重要?又要如何写出便于编译器优化的代码呢?
类似的问题还有很多,但总结起来其实就是:真实世界的编译器,到底是怎么写出来的?
那弄明白了这个问题,到底对我们有什么帮助呢?
第一,研究这些语言的编译机制,能直接提高我们的技术水平。一方面,深入了解自己使用的语言的编译器,会有助于你吃透这门语言的核心特性,更好地运用它,从而让自己向着专家级别的工程师进军。另一方面,IT 技术的进化速度是很快的,作为技术人,我们需要迅速跟上技术更迭的速度。而这些现代语言的编译器,往往就是整合了最前沿的技术。
第二,阅读语言编译器的源码,是高效学习编译原理的重要路径。当你真正了解了身边的语言的编译器是怎样编写的之后,那些抽象的理论就会变得生动和具体,你也就会在编译技术领域里往前跨出一大步了。
我是如何规划课程模块的?
为了达到本课程的目标,我仔细规划了课程的内容,将其划分为预备知识篇、真实编译器解析篇和现代语言设计篇三部分。
在预备知识篇,我会简明扼要地帮你重温一下编译原理的知识体系,让你对这些关键概念的理解变得更清晰。磨刀不误砍柴工,你学完预备知识篇后,再去看各种语言编译器的源代码和相关文档时,至少不会被各种名词、术语搞晕,也能更好地建立具体实现跟原理之间的关联,能互相印证它们。
在真实编译器解析篇,我会带你研究语言编译器的源代码,跟踪它们的运行过程,分析编译过程的每一步是如何实现的,并对有特点的编译技术点加以分析和点评。这样,我们在研究了 Java、Java JIT、Python、JavaScript、Julia、Go、MySQL 这 7 个编译器以后,就相当于把编译原理印证了 7 遍。
在现代语言设计篇,我会带你分析和总结前面已经研究过的编译器,进一步提升你对相关编译技术的认知高度。学完这一模块以后,你对于如何设计编译器的前端、中端、后端、运行时,都会有比较全面的了解,知道如何在不同的技术路线之间做取舍。
01 | 编译的全过程都悄悄做了哪些事情?

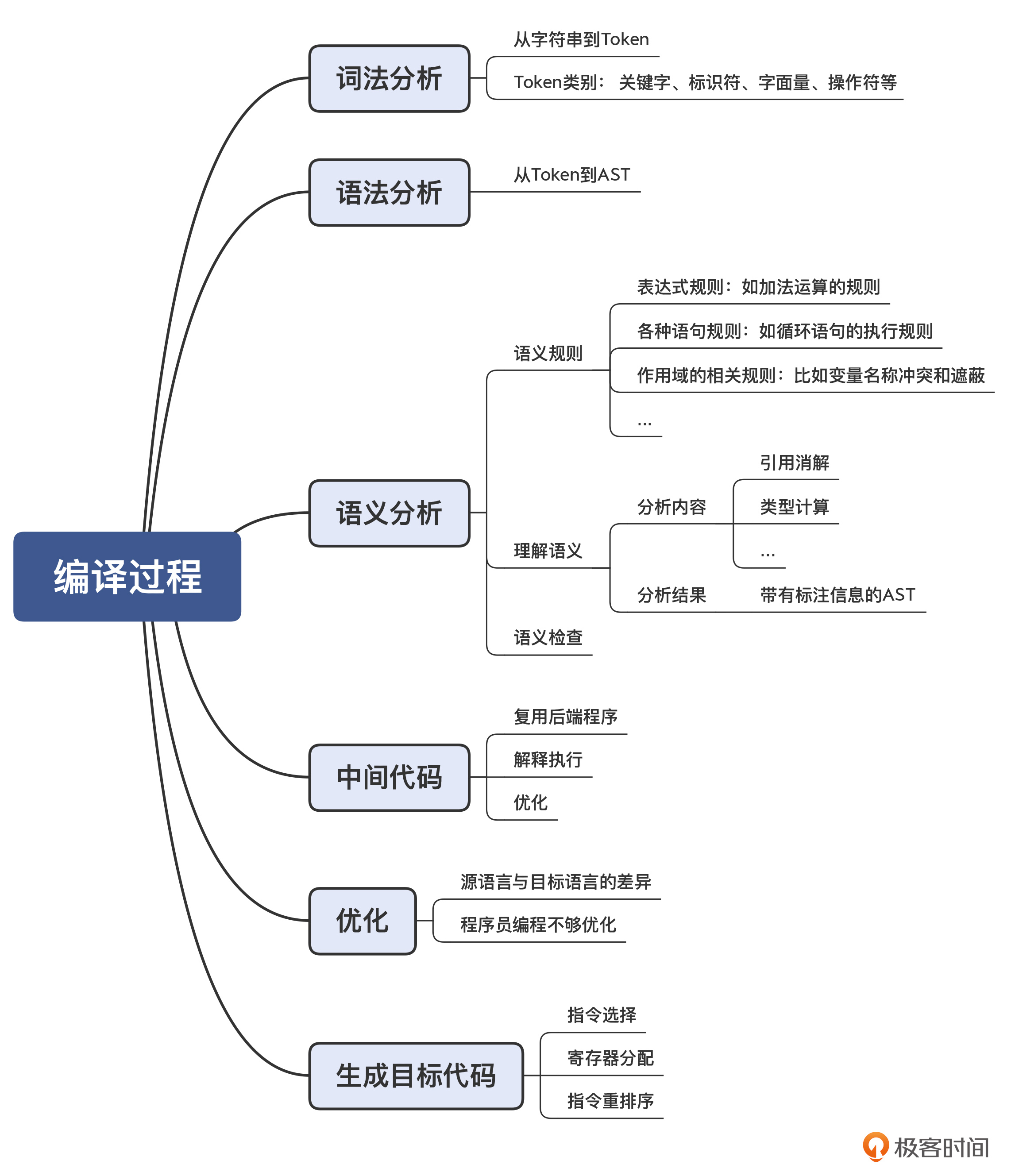
语义分析(Semantic Analysis)
生成 AST 以后,程序的语法结构就很清晰了,编译工作往前迈进了一大步。但这棵树到底代表了什么意思,我们目前仍然不能完全确定。
比如说,表达式“a+3”在计算机程序里的完整含义是:“获取变量 a 的值,把它跟字面量 3 的值相加,得到最终结果。”但我们目前只得到了这么一棵树,干秃秃的数,完全没有上面这么丰富的含义,真正的含义得需要一份相应的说明才行。
所以,我们可以在每个 AST 节点上附加一些语义规则,让它能反映语言设计者的本意。
AST 加上这些语义规则,就能完整地反映源代码的含义。这个时候,你就可以做很多事情了。比如,你可以深度优先地遍历 AST,并且一边遍历,一边执行语法规则。那么这个遍历过程,就是解释执行代码的过程。你相当于写了一个基于 AST 的解释器。
语义分析是要解决什么问题呢?
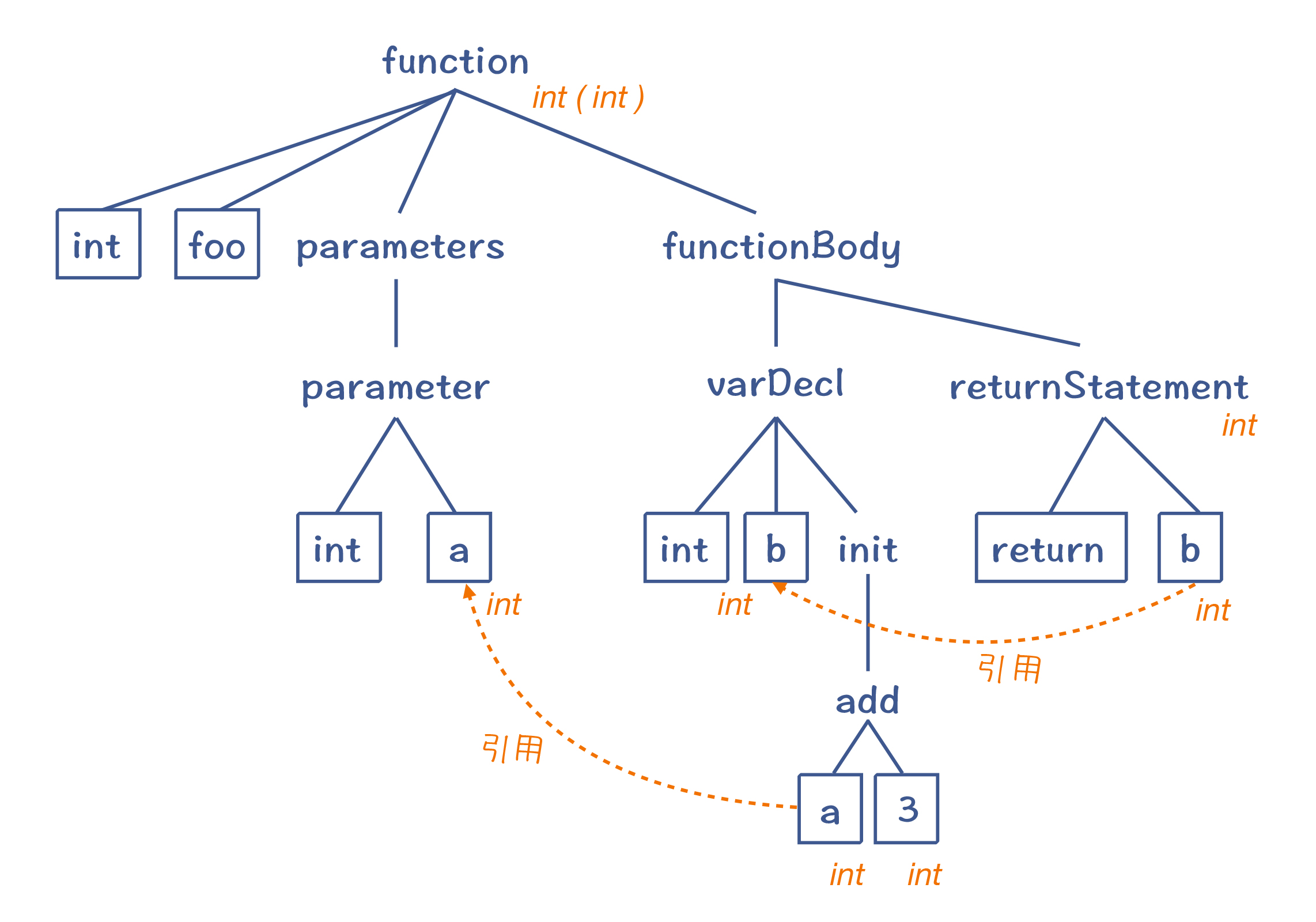
举个例子,如果我把示例程序稍微变换一下,加一个全局变量的声明,这个全局变量也叫 a。那你觉得“a+3”中的变量 a 指的是哪个变量?
int a = 10; //全局变量
int foo(int a){ //参数里有另一个变量a
int b = a + 3; //这里的a指的是哪一个?
return b;
}我们知道,编译程序要根据 C 语言在作用域方面的语义规则,识别出“a+3”中的 a,所以这里指的其实是函数参数中的 a,而不是全局变量的 a。这样的话,我们在计算“a+3”的时候才能取到正确的值。
而把“a+3”中的 a,跟正确的变量定义关联的过程,就叫做引用消解(Resolve)。这个时候,变量 a 的语义才算是清晰了。引用消解其实就是找到真正的引用的对象。
引用消解需要在上下文中查找某个标识符的定义与引用的关系,所以我们现在可以回答前面的问题了,语义分析的重要特点,就是做上下文相关的分析。
在语义分析阶段,编译器还会识别出数据的类型。比如int类型和浮点类型处理的方式是不一样的。
语义分析获得的一些信息(引用消解信息、类型信息等),会附加到 AST 上。这样的 AST 叫做带有标注信息的 AST(Annotated AST/Decorated AST),用于更全面地反映源代码的含义。
带有标注信息的 AST:
总结起来,在语义分析阶段,编译器会做语义理解和语义检查这两方面的工作。词法分析、语法分析和语义分析,统称编译器的前端,它完成的是对源代码的理解工作。
做完语义分析以后,接下来编译器要做什么呢?
本质上,编译器这时可以直接生成目标代码,因为编译器已经完全理解了程序的含义,并把它表示成了带有语义信息的 AST、符号表等数据结构。
中间代码(IR)
我们倾向于使用 IR 有两个原因。
第一个原因,是很多解释型的语言,可以直接执行 IR,比如 Python 和 Java
第二个原因更加重要。我们生成代码的时候,需要做大量的优化工作。而采用中间代码来编写优化算法的好处,是可以把大部分的优化算法,写成与具体 CPU 架构无关的形式,从而大大降低编译器适配不同 CPU 的工作量。
那为什么需要做优化工作呢?这里又有两大类的原因。
- 第一个原因,是源语言和目标语言有差异。
源语言:
Class Person{
private String name;
public String getName(){
return name;
}
public void setName(String newName){
this.name = newName
}
}如果你在程序里用“person.getName()”来获取 Person 的 name 字段,会是一个开销很大的操作,因为它涉及函数调用。
怎样简化呢?就是跳过方法的调用。
这种优化方法就叫做内联(inlining),也就是把原来程序中的函数调用去掉,把函数内的逻辑直接嵌入函数调用者的代码中。在 Java 语言里,这种属性读写的代码非常多。所以,Java 的 JIT 编译器(把字节码编译成本地代码)很重要的工作就是实现内联优化,这会让整体系统的性能提高很大的一个百分比!
- 第二个需要优化工作的原因,是程序员写的代码不是最优的,而编译器会帮你做纠正。比如:常数折叠、死代码删除、分支的提取确定
生成目标代码
编译器最后一个阶段的工作,是生成高效率的目标代码,也就是汇编代码。这个阶段,编译器也有几个重要的工作。
- 第一,是要选择合适的指令,生成性能最高的代码。
- 第二,是要优化寄存器的分配,让频繁访问的变量(比如循环变量)放到寄存器里,因为访问寄存器要比访问内存快 100 倍左右。
- 第三,是在不改变运行结果的情况下,对指令做重新排序,从而充分运用 CPU 内部的多个功能部件的并行计算能力。
02 | 词法分析:用两种方式构造有限自动机
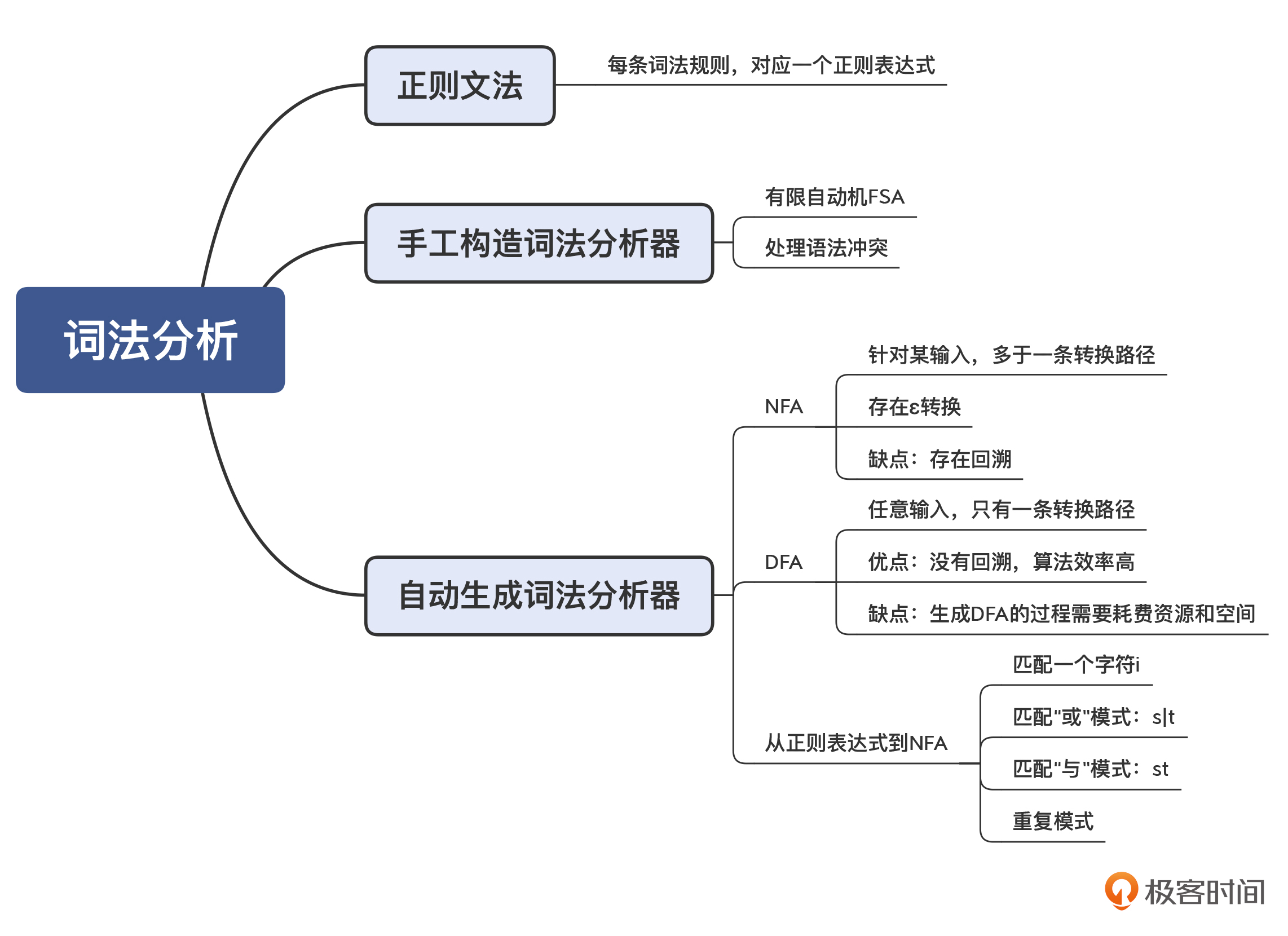
手写有限自动机
正则表达式也可以用来描述词法规则。这种描述方法,我们叫做正则文法(Regular Grammar)。
比如,数字字面量和标识符的正则文法描述是这样的:
IntLiteral : [0-9]+; //至少有一个数字
Id : [A-Za-z][A-Za-z0-9]*; //以字母开头,后面可以是字符或数字与普通的正则表达式工具不同的是,词法分析器要用到很多个词法规则,每个词法规则都采用“Token 类型: 正则表达式”这样一种格式,用于匹配一种 Token。
然而,当我们采用了多条词法规则的时候,有可能会出现词法规则冲突的情况。比如说,int 关键字其实也是符合标识符的词法规则的。
所以,词法规则里面要有优先级,比如排在前面的词法规则优先级更高。这样的话,我们就能够设计出区分 int 关键字和标识符的有限自动机了
从正则表达式生成有限自动机
我们能否只写出词法规则,就自动生成相对应的有限自动机呢?
当然是可以的,实际上,正则表达式工具就是这么做的。此外,词法分析器生成工具 lex(及 GNU 版本的 flex)也能够基于规则自动生成词法分析器。
它的具体实现思路是这样的:把一个正则表达式翻译成 NFA(Nondeterministic Finite Automaton),然后把 NFA 转换成 DFA(Deterministic Finite Automaton)。
无论是 NFA 还是 DFA,都等价于正则表达式。也就是说,所有的正则表达式都能转换成 NFA 或 DFA;而所有的 NFA 或 DFA,也都能转换成正则表达式。
一个正则表达式可以机械地翻译成一个 NFA。它的翻译方法如下:
- 识别字符 i 的 NFA。
- 转换“s|t”这样的正则表达式。
- 转换“st”这样的正则表达式。
- 对于“?”“*”和“+”这样的符号,它们的意思是可以重复 0 次、0 到多次、1 到多次,转换时要增加额外的状态和边。
基于 NFA,你仍然可以实现一个词法分析器,只不过算法会跟基于 DFA 的不同:当某个状态存在一条以上的转换路径的时候,你要先尝试其中的一条;如果匹配不上,再退回来,尝试其他路径。这种试探不成功再退回来的过程,叫做回溯(Backtracking)。
NFA 算法的特点:因为存在多条可能的路径,所以需要试探和回溯,在比较极端的情况下,回溯次数会非常多,性能会变得非常差。
NFA 的运行可能导致大量的回溯,那么能否将 NFA 转换成 DFA,让字符串的匹配过程更简单呢?如果能的话,那整个过程都可以自动化,从正则表达式到 NFA,再从 NFA 到 DFA。
方法是有的,这个算法就是子集构造法
在实际的编译器中,词法分析器一般都是手写的,依据的基本原理就是构造有限自动机。不过有一些地方也会用手工编码的方式做一些优化(如 javac 编译器),有些编译器会做用一些特别的技巧来提升解析速度(如 JavaScript 的 V8 编译器)
03 | 语法分析:两个基本功和两种算法思路
掌握语法分析阶段的核心知识点,也就是两个基本功和两种算法思路。理解了这些重要的知识点,对于语法分析,你就不是外行了。
- 两个基本功:第一,必须能够阅读和书写语法规则,也就是掌握上下文无关文法;第二,必须要掌握递归下降算法。
- 两种算法思路:一种是自顶向下的语法分析,另一种则是自底向上的语法分析。
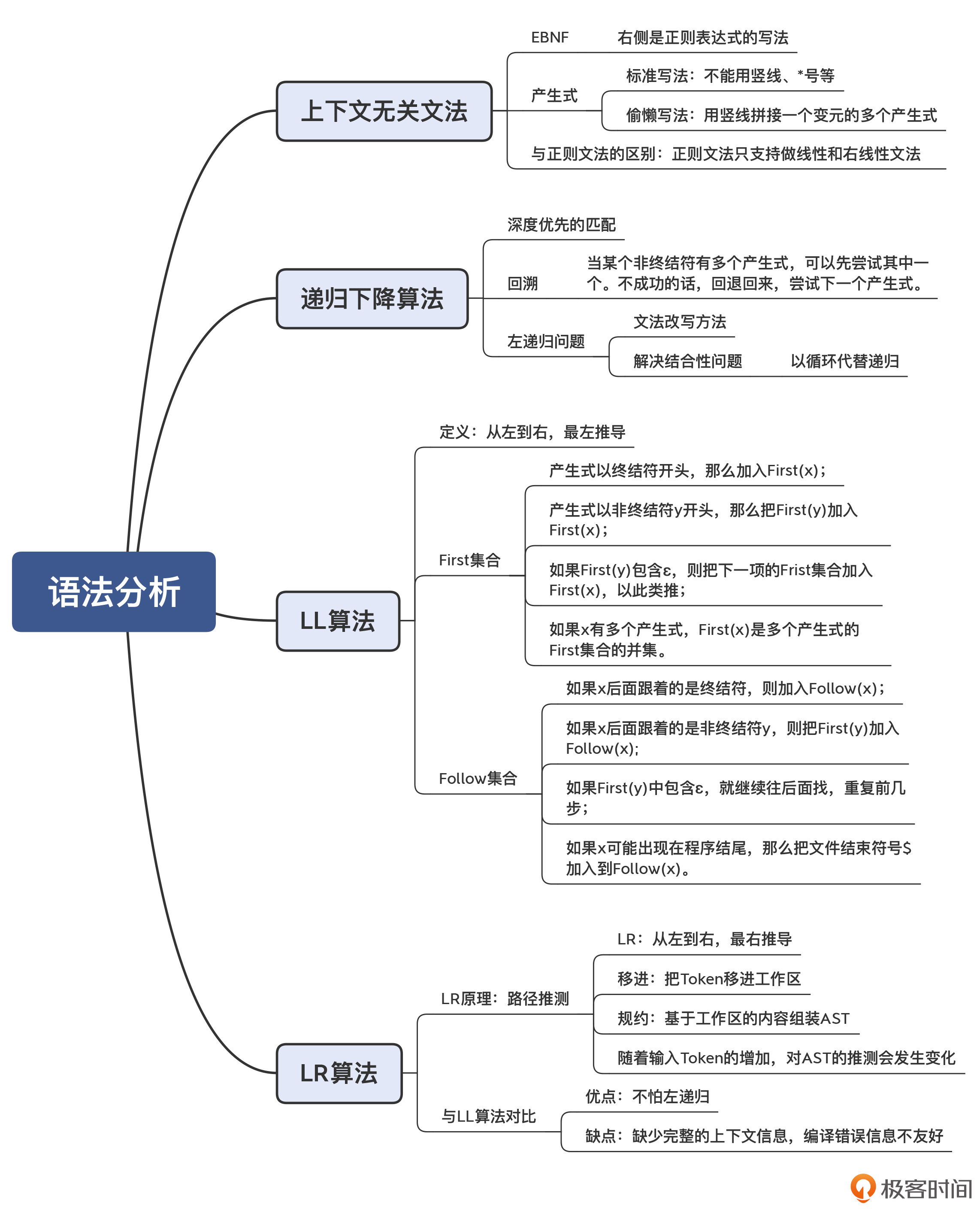
上下文无关文法(Context-Free Grammar)
用上下文无关文法可以描述程序的语法结构
第一种写法: 扩展巴科斯范式(EBNF)
exp : add ; //表达式
add : add '+' mul | mul; //加法表达式
mul : mul '*' pri | pri; //乘法表达式
pri : IntLiteral | Id | '(' exp ')' ; //基础表达式 第二种写法: 产生式(Production Rule),又叫做替换规则(Substitution Rule)
产生式不用“ * ”和“+”来表示重复,而是用迭代,并引入“ε”(空字符串)
add -> add + mul | mul
mul -> mul * pri | pri你可能会问,上下文无关文法和词法分析中用到的正则文法是否有一定的关系?
是的,正则文法是上下文无关文法的一个子集。其实,正则文法也可以写成产生式的格式。比如,数字字面量(正则表达式为“[0-9]+”)可以写成:
IntLiteral -> Digit IntLiteral1
IntLiteral1 -> Digit IntLiteral1
IntLiteral1 -> ε
Digit -> [0-9]但是,在上下文无关文法里,产生式的右边可以放置任意的终结符和非终结符,而正则文法只是其中的一个子集,叫做线性文法(Linear Grammar)。它的特点是产生式的右边部分最多只有一个非终结符
为什么它会叫“上下文无关文法”这样一个奇怪的名字呢?难道还有上下文相关的文法吗?
答案的确是有的。举个例子来说,在高级语言里,本地变量必须先声明,才能在后面使用。这种制约关系就是上下文相关的。
不过,在语法分析阶段,我们一般不管上下文之间的依赖关系,这样能使得语法分析的任务更简单。而对于上下文相关的情况,则放到语义分析阶段再去处理。
递归下降算法(Recursive Descent Parsing)
递归下降算法其实很简单,它的基本思路就是按照语法规则去匹配 Token 串, 遇到终结符的直接匹配,遇到非终结符的递归下降进行匹配。
那么总结起来,递归下降算法的特点是:
- 对于一个非终结符,要从左到右依次匹配其产生式中的每个项,包括非终结符和终结符。
- 在匹配产生式右边的非终结符时,要下降一层,继续匹配该非终结符的产生式。
- 如果一个语法规则有多个可选的产生式,那么只要有一个产生式匹配成功就行。如果一个产生式匹配不成功,那就回退回来,尝试另一个产生式。这种回退过程,叫做回溯(Backtracking)。
递归下降算法是非常容易理解的。它能非常有效地处理很多语法规则,但是它也有两个缺点。
1. 就是著名的左递归(Left Recursion)问题,会导致无限递归。若把产生式改成右递归,又会产生结合性的问题。 最终解决办法是:把递归调用转化成循环。这里利用了很多同学都知道的一个原理,即递归调用可以转化为循环
2. 就是当产生式匹配失败的时候,必须要“回溯”,这就可能导致浪费。这个时候,我们有个针对性的解决办法,就是预读后续的一个 Token,判断该选择哪个产生式。
LL 算法:计算 First 和 Follow 集合
如果我们手写递归下降算法,可以用肉眼识别出每次应该基于哪个 Token,选择用哪个产生式。但是,对于一些比较复杂的语法规则,我们要去看好几层规则,这样比较辛苦。
那么能否有一个算法,来自动计算出选择不同产生式的依据呢?当然是有的,这就是 LL 算法家族。
LL 算法是带有预测能力的自顶向下算法。在推导的时候,我们希望当存在多个候选的产生式时,瞄一眼下一个(或多个)Token,就知道采用哪个产生式。如果只需要预看一个 Token,就是 LL(1) 算法。
LL 算法的要点,就是计算 First 和 Follow 集合。
计算 First
First 集合是每个产生式开头可能会出现的 Token 的集合。
总体来说,针对非终结符 x,它的 First 集合的计算规则是这样的:
- 如果产生式以终结符开头,那么把这个终结符加入 First(x);
- 如果产生式以非终结符 y 开头,那么把 First(y) 加入 First(x);
- 如果 First(y) 包含ε,那要把下一个项的 First 集合也加入进来,以此类推;
- 如果 x 有多个产生式,那么 First(x) 是每个产生式的并集。
计算 Follow
对于某个非终结符后面可能跟着的 Token 的集合,我们叫做 Follow 集合
Follow 的算法也比较简单,以非终结符 x 为例:
- 扫描语法规则,看看 x 后面都可能跟着哪些符号;
- 对于后面跟着的终结符,都加到 Follow(x) 集合中去;
- 如果后面是非终结符 y,就把 First(y) 加 Follow(x) 集合中去;
- 最后,如果 First(y) 中包含ε,就继续往后找;
- 如果 x 可能出现在程序结尾,那么要把程序的终结符 $ 加入到 Follow(x) 中去。
这样在计算了 First 和 Follow 集合之后,你就可以通过预读一个 Token,来完全确定采用哪个产生式。这种算法,就叫做 LL(1) 算法。
First 和 Follow 集合的用途:
- LL(1)分析表构建:First 集合用于确定预测分析表中的预测项(需要考虑输入串的首符号);Follow 集合用于处理推导时的语法冲突。
- 语法分析决策:在LL(1)算法中,First 和 Follow 集合帮助确定在每一步应该选择哪个产生式,哪个符号可以推导出另一个符号,以及如何处理可能的语法歧义或冲突。
LL(1) 中的第一个 L,是 Left-to-right 的缩写,代表从左向右处理 Token 串。第二个 L,是 Leftmost 的缩写,意思是最左推导。最左推导是什么呢?就是它总是先把产生式中最左侧的非终结符展开完毕以后,再去展开下一个。这也就相当于对 AST 从左子节点开始的深度优先遍历。LL(1) 中的 1,指的是预读一个 Token。
递归下降算法和LL算法都是自顶向下的。递归下降强调的是用“递归调用”和“层层下降”的方式来书写代码。所以LL算法可以用递归下降的方式编写(Java编译器),也可以用查表的方式编写(Python编译器),这两种方式你在后面的课程里都可以看到。
LR 算法:移进和规约
前面讲的递归下降和 LL 算法,都是自顶向下的算法。还有一类算法,是自底向上的,其中的代表就是 LR 算法。
自顶向下的算法,是从根节点逐层往下分解,形成最后的 AST;而 LR 算法的原理呢,则是从底下先拼凑出 AST 的一些局部拼图,并逐步组装成一棵完整的 AST。所以,其中的关键之处在于如何“拼凑”
相对于 LL 算法,LR 算法的优点是能够处理左递归文法。但它也有缺点,比如不利于输出全面的编译错误信息。因为在没有解析完毕之前,算法并不知道最后的 AST 是什么样子,所以也不清楚当前的语法错误在整体 AST 中的位置。
最后我再提一下 LR 的意思,来帮你更完整地理解 LR 算法。L 还是代表从左到右读入 Token,而 R 是最右推导(Rightmost)的意思。
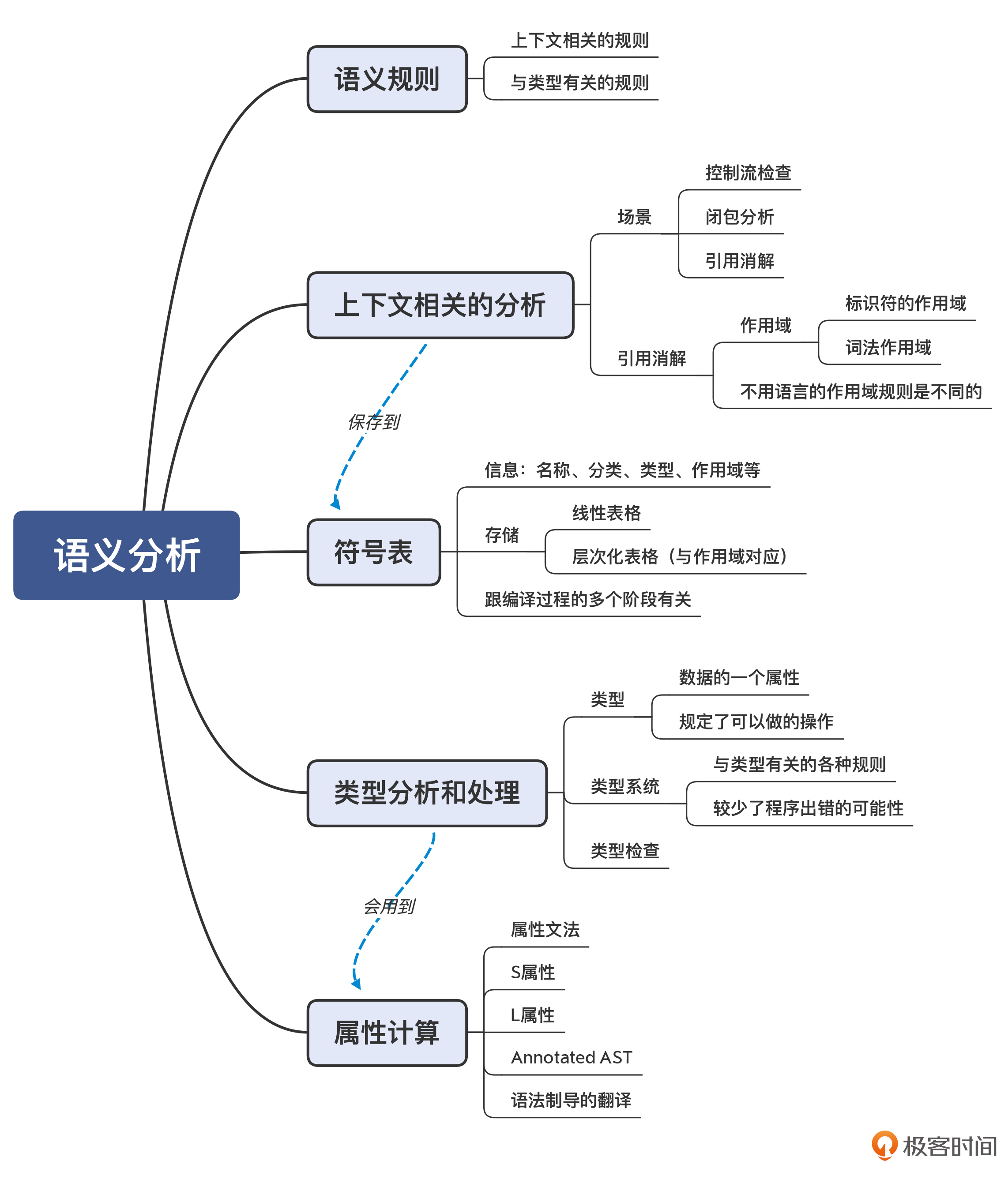
04 | 语义分析:让程序符合语义规则
语义,就是程序要表达的意思。因为计算机最终是用来做计算的,那么理解程序表达的意思,就是要知道让计算机去执行什么计算动作,这样才好翻译成目标代码。
语义规则可以分为两大类。
- 第一类规则与上下文有关。因为我们说了,语法分析只能处理与上下文无关的工作。而与上下文有关的工作呢,自然就放到了语义分析阶段。
- 第二类规则与类型有关。在计算机语言中,类型是语义的重要载体。所以,语义分析阶段要处理与类型有关的工作。比如,声明新类型、类型检查、类型推断等。在做类型分析的时候,我们会用到一个工具,就是属性计算,也是需要你了解和掌握的。
在语义分析过程中,会使用两个数据结构。一个还是 AST,但我们会把语义分析时获得的一些信息标注在 AST 上,形成带有标注的 AST。另一个是符号表,用来记录程序中声明的各种标识符,并用于后续各个编译阶段。
补充:某些与类型有关的处理工作,还必须到运行期才能去做。比如,在多态的情况,调用一个方法时,到底要采用哪个子类的实现,只有在运行时才会知道。这叫做动态绑定。
上下文相关的分析
场景 1:控制流检查
场景 2:闭包分析
场景 3:引用消解
引用消解(Reference Resolution),有时也被称作名称消解(Name Resolution)或者标签消解(Label Resolution)。对变量名称、常量名称、函数名称、类型名称、包名称等的消解,都属于引用消解
在高级语言里,我们会做变量、函数(或方法)和类型的声明,然后在其他地方使用它们。这个时候,我们要找到定义和使用之间的正确引用关系。
符号表(Symbol Table)
那针对引用消解,其实就是从符号表里查找被引用的符号的定义
更进一步地,符号表除了用于引用消解外,还可以辅助完成语义分析的其他工作。比如,在做类型检查的时候,我们可以从符号表里查找某个符号的类型,从而检查类型是否兼容。
在 Java 的字节码文件里也需要保存符号信息,以便在加载后我们可以定位其中的类、方法和成员变量。
类型分析和处理
在计算机语言里,类型是数据的一个属性,它的作用是来告诉编译器或解释器,程序可以如何使用这些数据
关于类型检查,编译器一般会采用属性计算的方法,来计算出每个 AST 节点的类型属性,然后检查它们是否匹配。
属性计算
例如:int b = a+3
有些属性是通过子节点计算出来的,这叫做 S 属性(Synthesized Attribute,综合出来的属性),比如等号右边的类型。
而另一些属性,则要根据父节点或者兄弟节点计算而来,这种属性叫做I 属性 (Inherited Attribute,继承到的属性),比如等号左边的 b 变量的类型。
计算出来的属性,我们可以标注在 AST 上,这就形成我第 1 讲曾经提过的带有标注信息的 AST,(Annotated Tree),也有人称之为 Decorated Tree,或者 Attributed Tree
属性计算的方法,就是基于语法规则,来定义一些属性计算的规则,在遍历 AST 的时候执行这些规则,我们就可以计算出属性值。这种基于语法规则定义的计算规则,被叫做属性文法(Attribute Grammar)。
你可能会问,属性计算的方法,除了计算类型,还可以计算什么属性呢?
其实,value(值)也可以看做是一个属性,你可以给每个节点定义一个“value”属性。对表达式求值,也就是对 value 做属性计算,比如,“a + 3”的值,我们就可以自下而上地计算出来。这样看起来,value 是一个 S 属性。
针对 value 这个属性的属性文法,你可以参考下面这个例子,在做语法解析(或先解析成 AST,再遍历 AST)的时候,执行方括号中的规则,我们就可以计算出 AST 的值了。
add1 → add2 + mul [ add1.value = add2.value + mul.value ]
add → mul [ add.value = mul.value ]
mul1 → mul2 * primary [ mul1.value = mul2.value * primary.value ]
mul → primary [ mul.value = primary.value ]
primary → ( add ) [ primary.value = add.value ]
primary → integer [ primary.value = strToInt(integer.str) ]这种在语法规则上附加一系列动作,在解析语法的时候执行这些动作的方式,是一种编译方法,在龙书里有一个专门的名字,叫做语法制导的翻译(Syntax Directed Translation,SDT)。使用语法制导的翻译可以做很多事情,包括做属性计算、填充符号表,以及生成 IR。
在实际的编译器中,语义分析相关的代码量往往要比词法分析和语法分析的代码量大。因为一门语言有很多语义规则,所以要做的语义分析和检查工作也很多。
并且,因为每门语言之间的差别主要都体现在语义上,所以每门语言在语义处理方面的工作差异也比较大。比如,一门语言支持闭包,另一门语言不支持;有的语言支持泛型,另一门语言不支持;一门语言的面向对象特性是基于继承实现的,而另一门语言则是基于组合实现的,等等。
不过,这没啥关系。我们主要抓住它们的共性就好了。这些共性,就是我们本讲的内容:
- 做好上下文相关的分析,比如对各种引用的消解、控制流的检查、闭包的分析等;
- 做好与类型有关的分析和处理,包括类型检查、类型推断等;
- 掌握属性计算这个工具,用于计算类型、值等属性;
- 最后,把获得的语义信息保存到符号表和 AST 里。
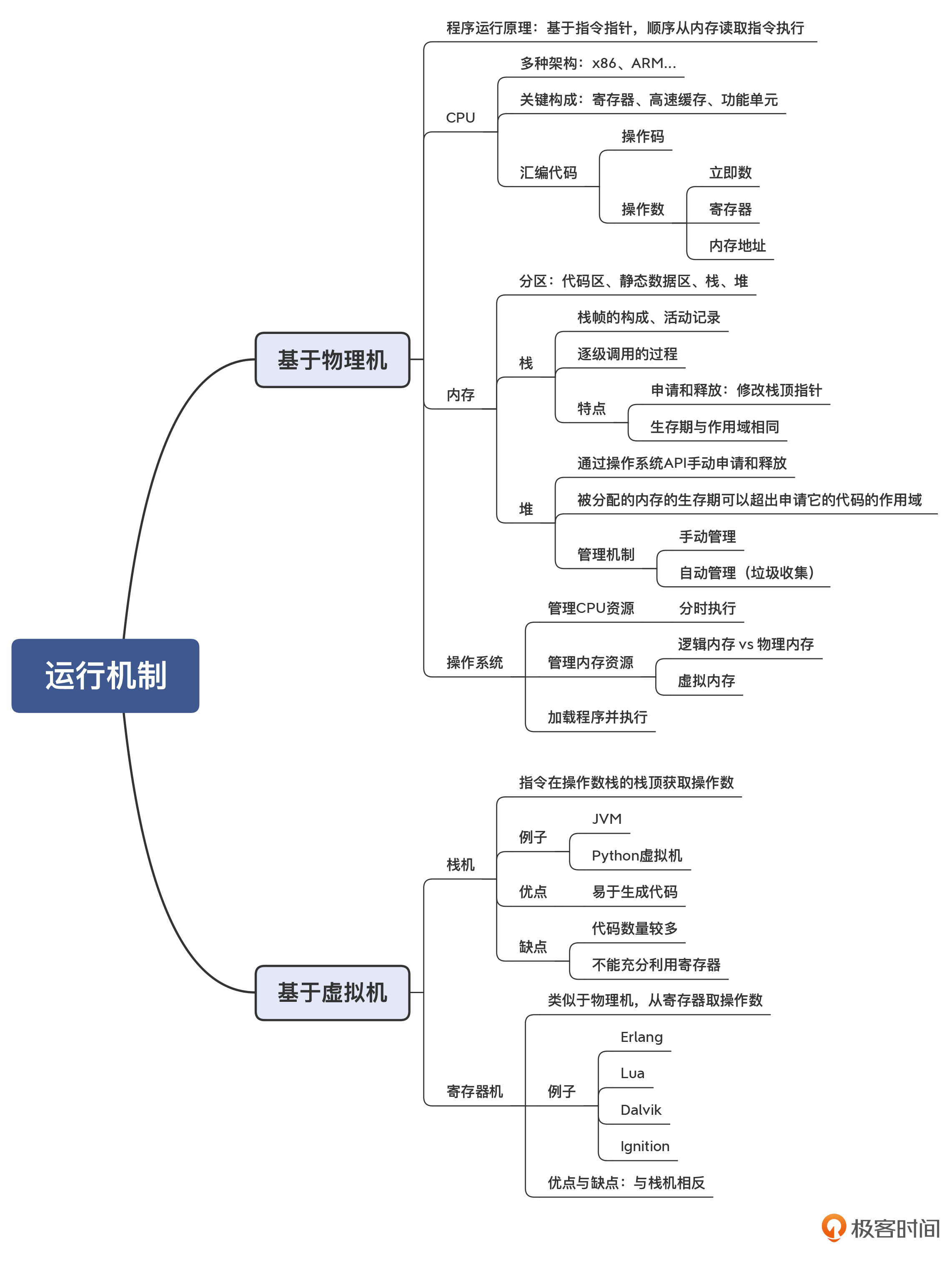
05 | 运行时机制:程序如何运行,你有发言权
经过前端阶段的处理分析,编译器已经充分理解了源代码的含义,准备好把前端处理的结果(带有标注信息的 AST、符号表)翻译成目标代码了。
常情况下,程序有两种执行模式。
- 第一种执行模式是在物理机上运行。针对的是 C、C++、Go 这样的语言,编译器直接将源代码编译成汇编代码(或直接生成机器码),然后生成能够在操作系统上运行的可执行程序。为了实现它们的后端,编译器需要理解程序在底层的运行环境,包括 CPU、内存、操作系统跟程序的互动关系,并要能理解汇编代码。
- 第二种执行模式是在虚拟机上运行。针对的是 Java、Python、Erlang 和 Lua 等语言,它们能够在虚拟机上解释执行。这时候,编译器要理解该语言的虚拟机的运行机制,并生成能够被执行的 IR。
相对于栈来说,这是堆的一个缺点。不过,相应的好处是,应用在堆里申请的对象的生存期,可以由自己控制,不会像栈里的内存那样,在退出作用域之后就被自动收回。所以,如果数据的生存期超过了创建它的作用域的生存期,就必须在堆中申请内存。
扩展:反之,如果数据的生存期跟创建它的作用域一致的话,那么在栈里和堆里申请都是可以的。当然,肯定在栈里申请更划算。所以,编译优化中的逃逸分析,本质就是分析出哪些对象的生存期是跟函数或方法的生存期一致的,那么就不需要到堆里申请了。
另外,在并发的场景下,由于栈是线程独享的,而堆是多个线程共享的,所以在堆里申请内存的效率会更低,因为需要在多个线程之间同步,避免出现竞争。
基于栈的虚拟机
JVM 和 Python 中的解释器,都采用了栈机的模型。
JVM 中,每一个线程都有一个 JVM 栈,每次调用一个方法都会生成一个栈帧,来支持这个方法的运行。这跟 C 语言很相似。但 JVM 的栈帧比 C 语言的复杂,它包含了一个本地变量数组(包括方法的参数和本地变量)、操作数栈、到运行时常量池的引用等信息。
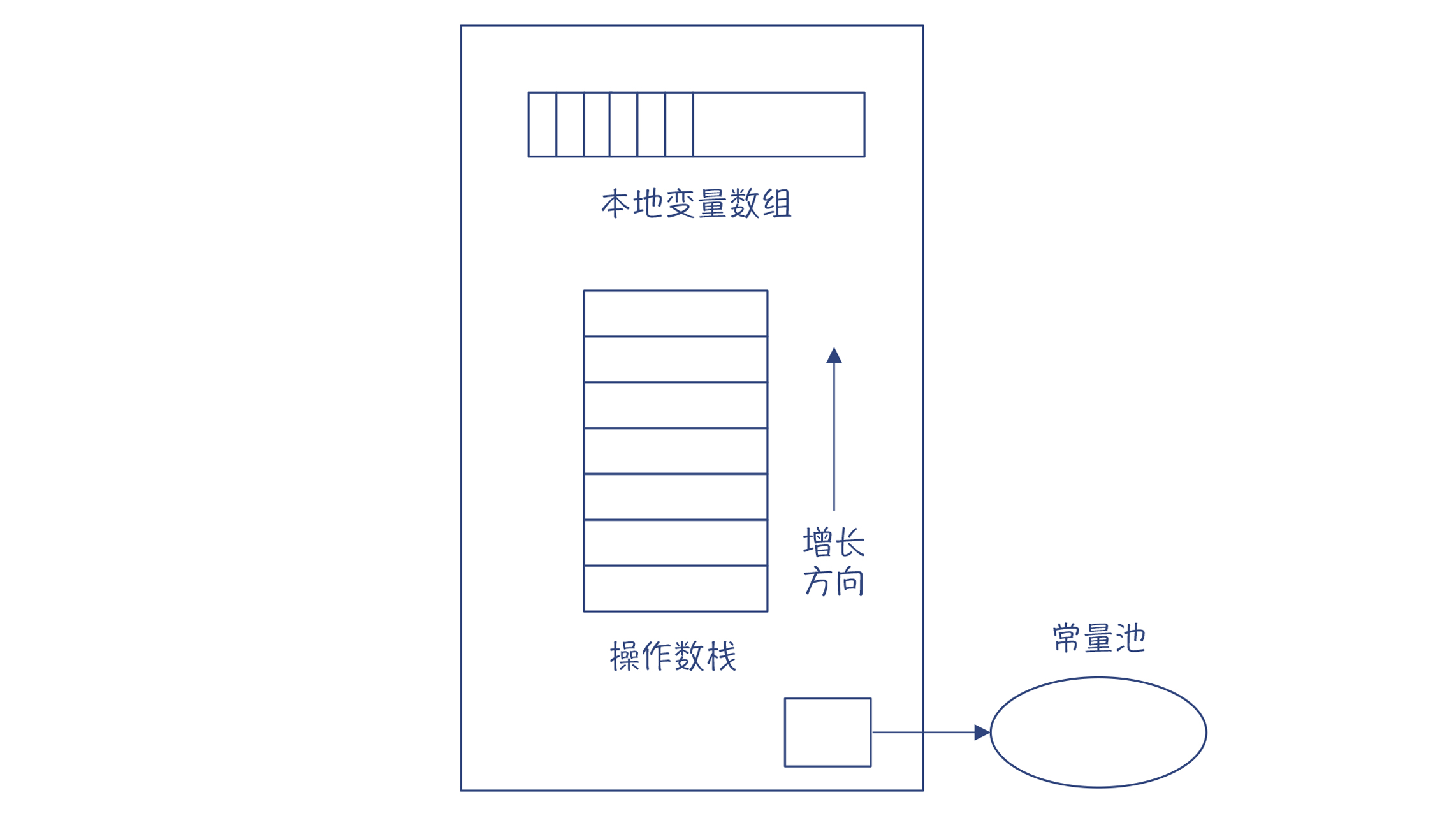
注意,我们这里提到了两个栈,一个是类似于 C 语言的栈的方法栈,另一个是方法栈里每个栈帧中的操作数栈。而我们说的栈机中的“栈”,指的是这个操作数栈,不要弄混了。
对于每个指令,解释器先要把它的操作数压到栈里。在执行指令时,从栈里弹出操作数,计算完毕以后,再把结果压回栈里。
以“2+3*5”为例,它对应的栈机的代码如下:
push 2 //把操作数2入栈
push 3 //把操作数3入栈
push 5 //把操作数5入栈, 栈里目前是2、 3、 5
imul //弹出5和3,执行整数乘法运算,得到15,然后把结果入栈,现在栈里是2、15
iadd //弹出15和2,执行整数加法运算,得到17,然后把结果入栈,最后栈里是17 注意一点,要从 AST 生成上面的代码,你只需要对 AST 做深度优先的遍历(后序遍历)即可。先后经过的节点是:2->3->5->*->+
生成上述栈机代码,只需要深度优先地遍历 AST,并且只需要进行两种操作:
- 在遇到字面量或者变量的时候,生成 push 指令;
- 在遇到操作符的时候,生成相应的操作指令即可。
你能看出,这个算法相当简单,这也是栈机最大的优点。
基于寄存器的虚拟机
除了栈机之外,另一种虚拟机是寄存器机。寄存器机使用寄存器名称来表示操作数,所以它的指令也跟汇编代码相似,像 add 这样的操作码后面要跟操作数。
与栈机相比,利用寄存器机编译所生成的代码更少,因为省去了很多 push 指令。
不过,寄存器机所指的寄存器,不一定是真正的物理寄存器,有可能只是栈帧中的一个位置。当然,有的寄存器机在实现的时候,确实会用到物理寄存器,从而提高计算性能。我们在后面研究 V8 的 Ignition 解释器时,会看到这种实现。
06 | 中间代码:不是只有一副面孔
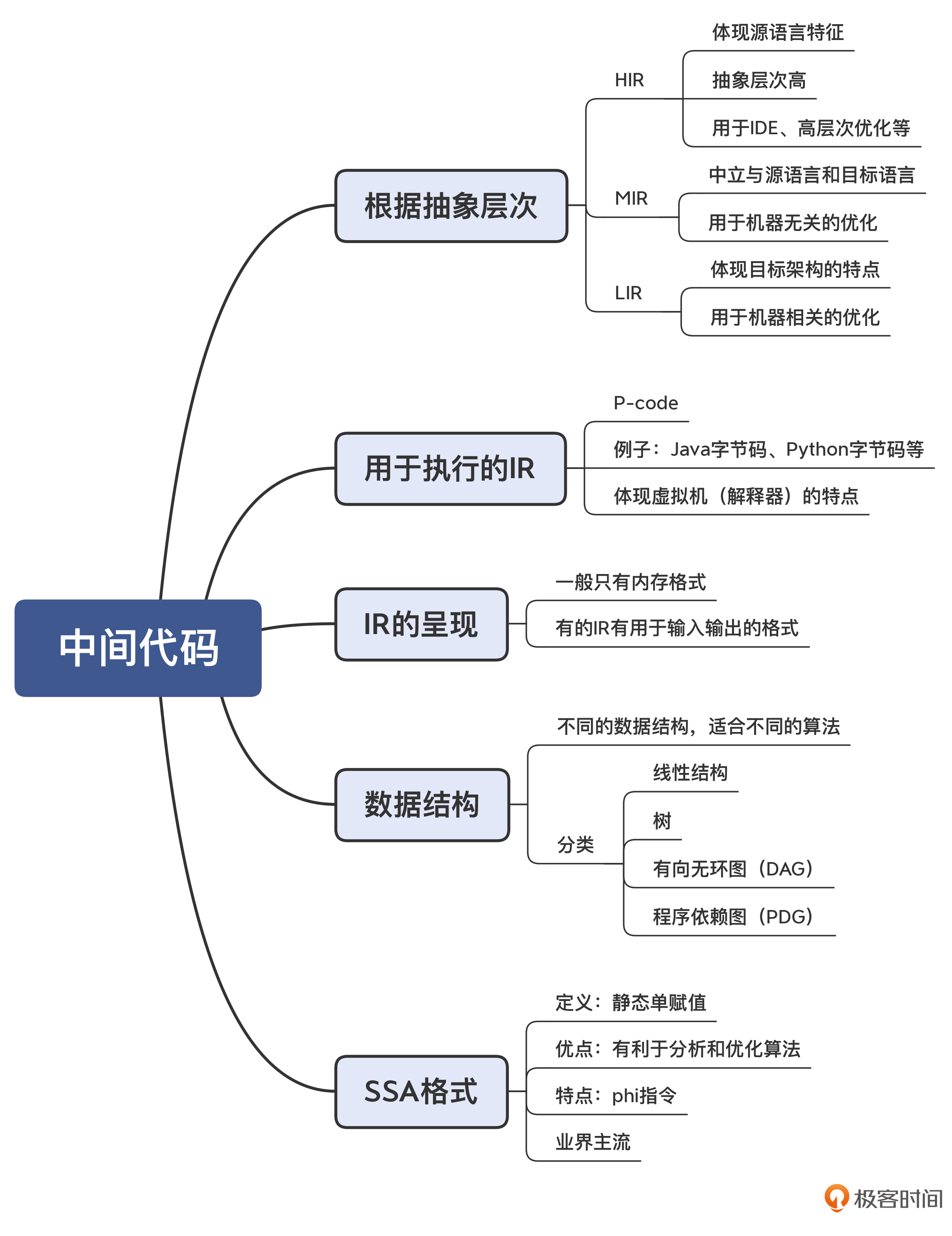
IR 的用途和层次
HIR:基于源语言做一些分析和变换
假设你要开发一款 IDE,那最主要的功能包括:发现语法错误、分析符号之间的依赖关系(以便进行跳转、判断方法的重载等)、根据需要自动生成或修改一些代码(提供重构能力)。
这个时候,你对 IR 的需求,是能够准确表达源语言的语义就行了。这种类型的 IR,可以叫做 High IR,简称 HIR。
其实,AST 和符号表就可以满足这个需求。MIR:独立于源语言和 CPU 架构做分析和优化
大量的优化算法是可以通用的,没有必要依赖源语言的语法和语义,也没有必要依赖具体的 CPU 架构。
这些优化包括部分算术优化、常量和变量传播、死代码删除等,我会在下一讲和你介绍。实现这类分析和优化功能的 IR 可以叫做 Middle IR,简称 MIR。LIR:依赖于 CPU 架构做优化和代码生成
这类 IR 的特点,是它的指令通常可以与机器指令一一对应,比较容易翻译成机器指令(或汇编代码)。因为 LIR 体现了 CPU 架构的底层特征,因此可以做一些与具体 CPU 架构相关的优化。P-code:用于解释执行的 IR
也就是 Portable Code 的意思。由于它与具体机器无关,因此可以很容易地运行在多种电脑上
Java 的字节码就是这种 IR。除此之外,Python、Erlang 也有自己的字节码,.NET 平台、Visual Basic 程序也不例外。
其实,你也完全可以基于 AST 实现一个全功能的解释器,只不过性能会差一些。对于专门用来解释执行 IR,通常会有一些特别的设计,跟虚拟机配合来尽量提升运行速度。
在一个编译器里,有时候会使用抽象层次从高到低的多种 IR,从便于“人”理解到便于“机器”理解。而编译过程可以理解为,抽象层次高的 IR 一直 lower 到抽象层次低的 IR 的过程,并且在每种 IR 上都会做一些适合这种 IR 的分析和处理工作,直到最后生成了优化的目标代码。
IR 的呈现格式
其实 IR 通常是没有书写格式的。一方面,大多数的 IR 跟 AST 一样,只是编译过程中的一个数据结构而已,或者说只有内存格式。比如,LLVM 的 IR 在内存里是一些对象和接口。
另一方面,为了调试的需要,你可以把 IR 以文本的方式输出,用于显示和分析。在这门课里,你也会看到很多 IR 的输出格式。
在少量情况下,IR 有比较严格的输出格式,不仅用于显示和分析,还可以作为结果保存,并可以重新读入编译器中。比如,LLVM 的 bitcode,可以保存成文本和二进制两种格式
IR 的数据结构
第一种:类似 TAC(三地址码) 的线性结构(Linear Form),可以把代码表示成一行行的指令或语句,用数组或者列表保存就行了
第二种:树结构,AST 就是一种树结构。
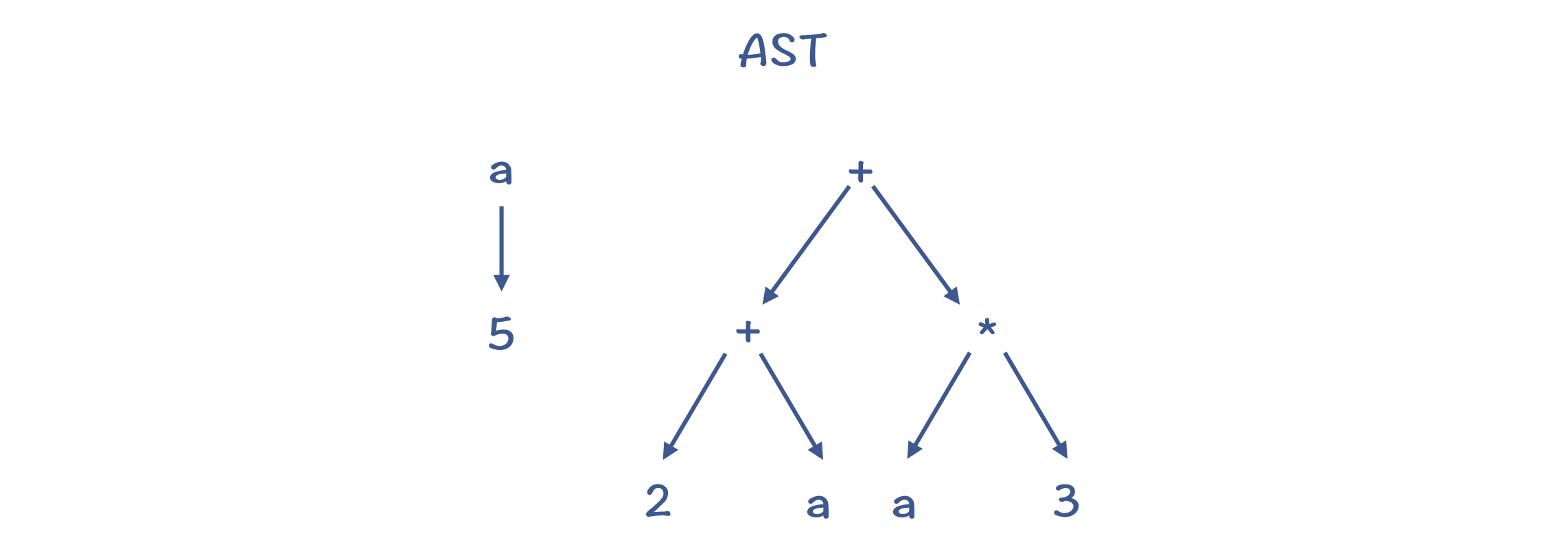
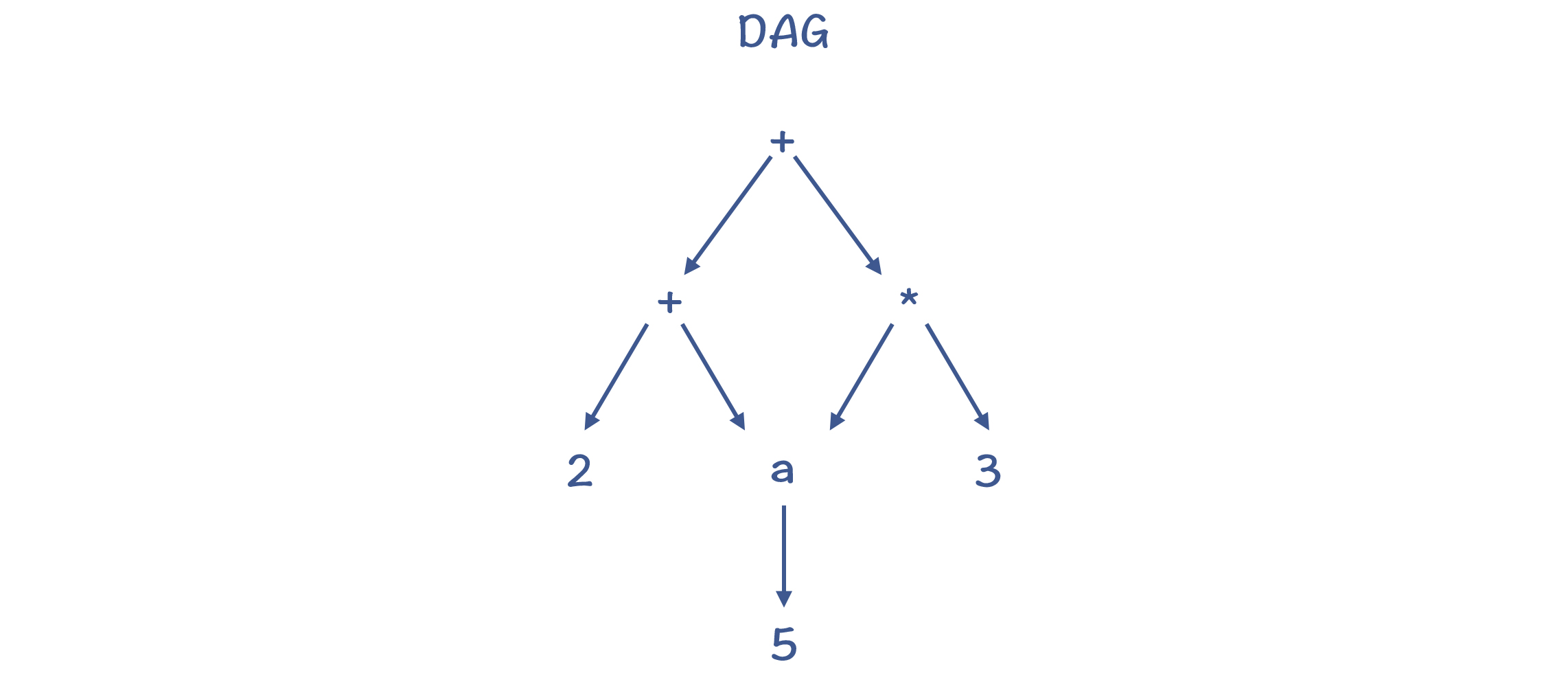
第三种:有向无环图(Directed Acyclic Graph,DAG)
DAG 结构,是在树结构的基础上,消除了冗余的子树。比如,上面的例子转化成 DAG 以后,对 a 的内存访问只做一次就行了。
第四种:程序依赖图(Program Dependence Graph,PDG)
程序依赖图,是显式地把程序中的数据依赖和控制依赖表示出来,形成一个图状的数据结构。基于这个数据结构,我们再做一些优化算法的时候,会更容易实现。
SSA 格式的 IR
SSA 是 Static Single Assignment 的缩写,也就是静态单赋值。这是 IR 的一种设计范式,它要求一个变量只能被赋值一次。
由于变量的值定义出来以后就不再变化,使得基于 SSA 更容易运行一些优化算法
由于 SSA 格式的优点,现代语言用于优化的 IR,很多都是基于 SSA 的了,包括我们本课程涉及的 Java 的 JIT 编译器、JavaScript 的 V8 编译器、Go 语言的 gc 编译器、Julia 编译器,以及 LLVM 工具等
phi 指令
int foo (int a){
int b = 0;
if (a > 10)
b = a;
else
b = 10;
return b;
}
BB1:
b1 := 0
if a>10 goto BB3
BB2:
b2 := 10
goto BB4
BB3:
b3 := a
BB4:
b4 := phi(BB2, BB3, b2, b3)
return b4会根据控制流的实际情况确定 b4 的值。如果 BB4 的前序节点是 BB2,那么 b4 的取值是 b2;而如果 BB4 的前序节点是 BB3,那么 b4 的取值就是 b3。所以你会看到,如果要满足 SSA 的要求,也就是一个变量只能赋值一次,那么在遇到有程序分支的情况下,就必须引入 phi 指令。
07 | 代码优化:跟编译器做朋友,让你的代码飞起来
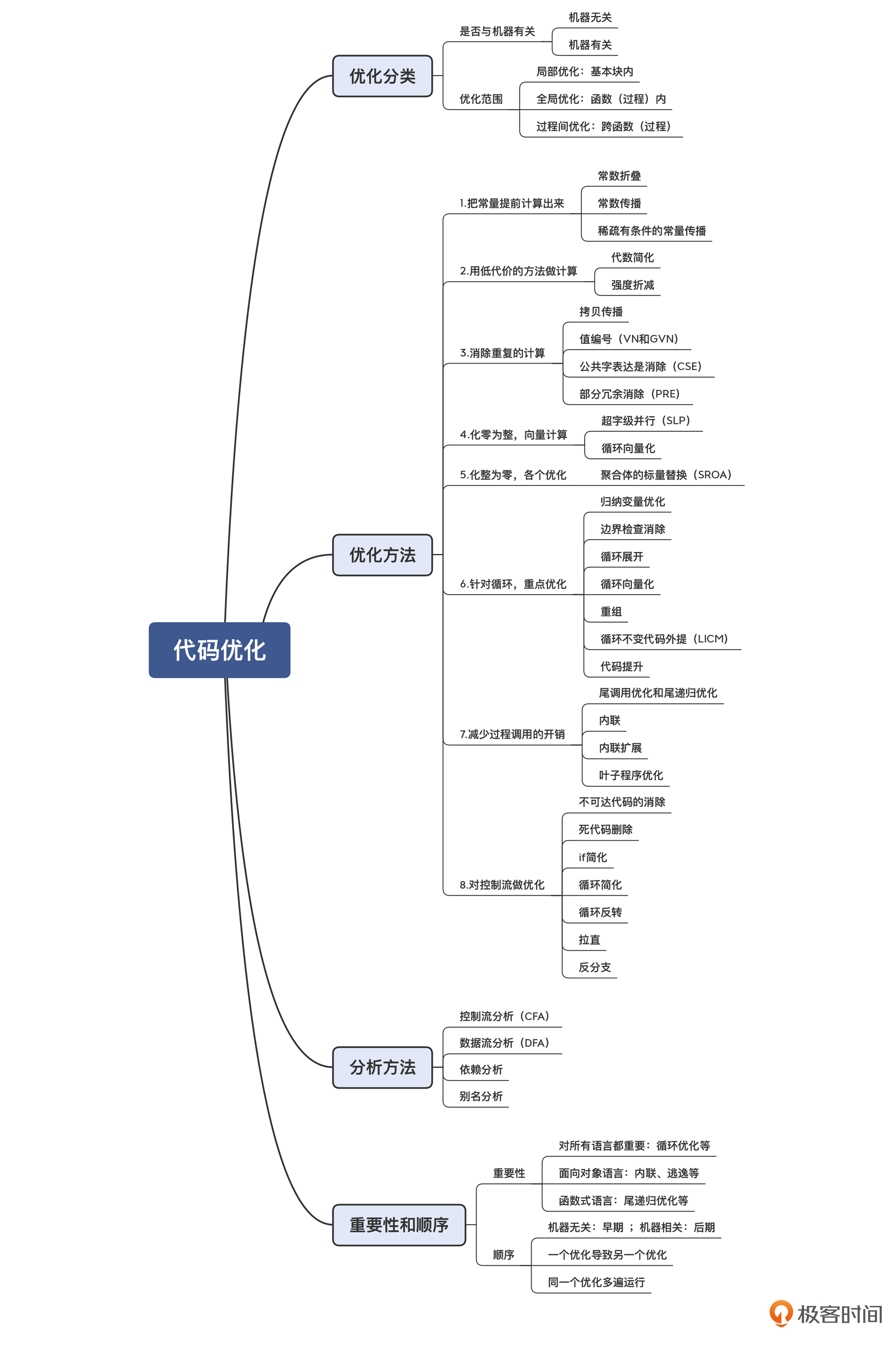
代码优化所依赖的分析方法
代码优化有的比较简单,比如常数折叠,依据 AST 或 MIR 做点处理就可以完成。但有些优化,就需要比较复杂的分析方法做支撑才能完成。这些分析方法包括控制流分析、数据流分析、依赖分析和别名分析等。
控制流分析(Control-Flow Analysis,CFA)。控制流分析是帮助我们建立对程序执行过程的理解,比如哪里是程序入口,哪里是出口,哪些语句构成了一个基本块,基本块之间跳转关系,哪个结构是一个循环结构(从而去做循环优化),等等。
数据流分析(Data-Flow Analysis,DFA)。数据流分析,能够帮助我们理解程序中的数据变化情况。除了做变量活跃性分析以外,数据流分析方法还可以做很多有用的分析。
依赖分析(Dependency Analysis)。依赖分析,就是分析出程序代码的控制依赖(Control Dependency)和数据依赖(Data Dependency)关系。这对指令排序和缓存优化很重要。它能通过调整指令之间的顺序来提升执行效率。但指令排序不能打破指令间的依赖关系,否则程序的执行就不正确。
别名分析(Alias Analysis)。在 C、C++ 等可以使用指针的语言中,同一个内存地址可能会有多个别名,因为不同的指针都可能指向同一个地址。编译器需要知道不同变量是否是别名关系,以便决定能否做某些优化。
优化方法的重要性和顺序
有些优化,比如对循环的优化,对每门语言都很重要,因为循环优化的收益很大。
而有些优化,对于特定的语言更加重要。在课程后面分析像 Java、JavaScript 这样的面向对象的现代语言时,你会看到,内联优化和逃逸分析的收益就比较大。而对于某些频繁使用尾递归的函数式编程语言来说,尾递归的优化就必不可少,否则性能损失太大。
至于优化的顺序,有的优化适合在早期做(基于 HIR 和 MIR),有的优化适合在后期做(基于 LIR 和机器代码)。并且,你通过前面的例子也可以看到,一般做完某个优化以后,会给别的优化带来机会,所以经常会在执行某个优化算法的时候,调用了另一个优化算法,而同样的优化算法也可能会运行好几遍。
08 | 代码生成:如何实现机器相关的优化?
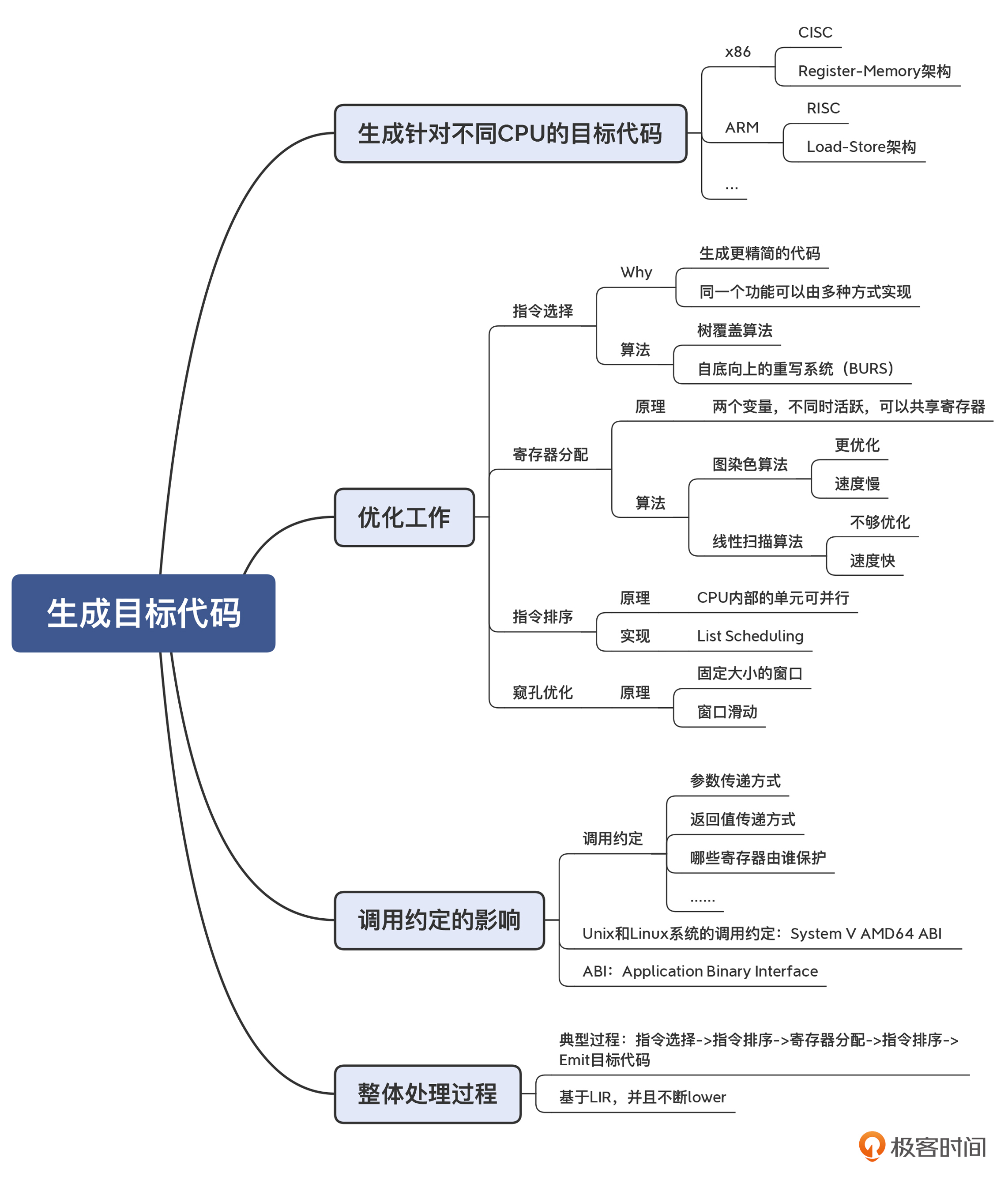
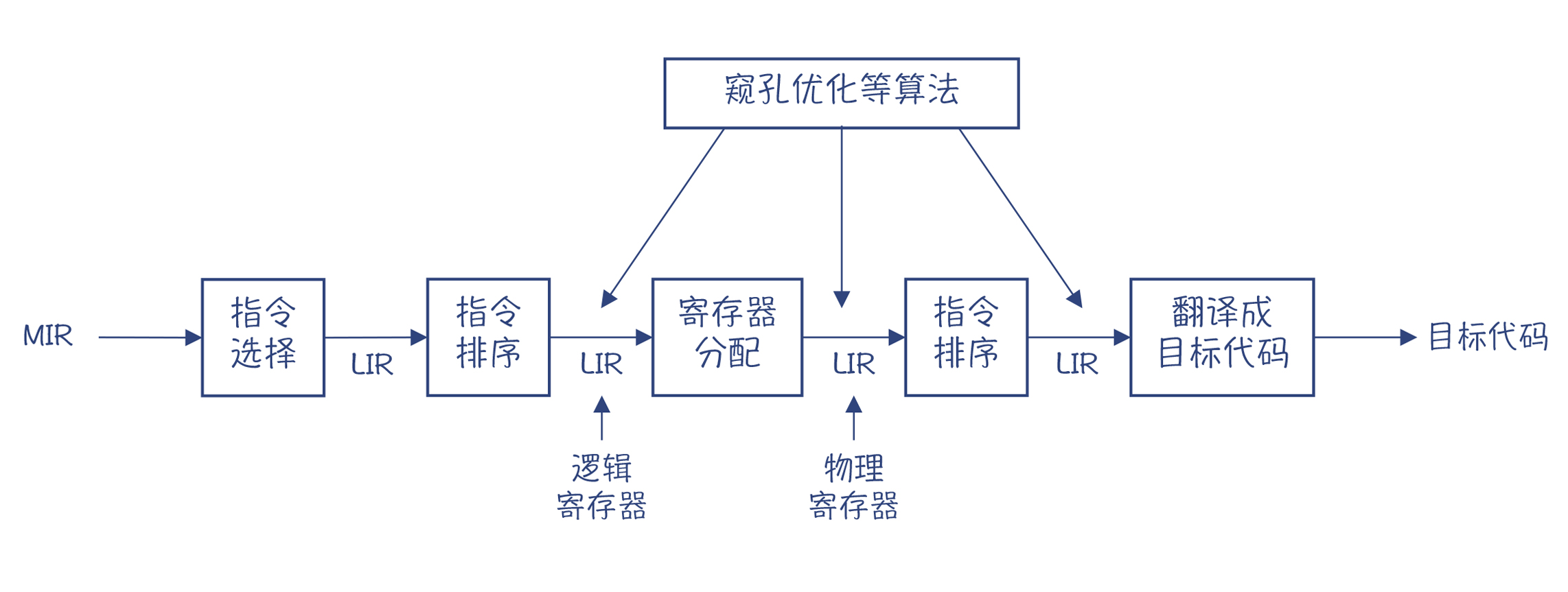
寄存器分配
寄存器分配的算法有很多种。一个使用比较广泛的算法是寄存器染色算法,它的特点是计算结果比较优化,但缺点是计算量比较大。
另一个常见的算法是线性扫描算法,它的优点是计算速度快,但缺点是有可能不够优化,适合需要编译速度比较快的场景,比如即时编译。
寄存器分配算法对性能的提升是非常显著的。接下来我要介绍的指令排序,对性能的提升同样非常显著。
指令排序
现代一些 CISC 的 CPU 在硬件层面支持乱序执行(Out-of-Order)。一批指令给到 CPU 后,它也会在内部打乱顺序去优化执行。而 RISC 芯片一般不支持乱序执行,所以像 ARM 这样的芯片,做指令排序就更加重要。
另外,在上一讲,我提到过对循环做优化的一种技术,叫做循环展开(Loop Unroll),它会把循环体中的代码重复多次,与之对应的是减少循环次数。这样一个基本块中就会有更多条指令,增加了通过指令排序做优化的机会。
调用约定的影响
知识扩展:ABI 是 Application Binary Interface 的缩写,也就是应用程序的二进制接口。通常,ABI 里面除了规定调用约定外,还要包括二进制文件的格式、进程初始化的方式等更多内容。
而在看 ARM 的汇编代码时,我们会发现,它超过了 4 个参数就要通过栈来传递。实际上,它遵循的是一种不同 ABI,叫做 EABI(嵌入式应用程序二进制接口)。在调用 Clang 做编译的时候,-target 参数“armv7a-none-eabi”的最后一部分,就是指定了 EABI。
在实现编译器的时候,你可以发明自己的调用约定,比如哪些寄存器用来放参数、哪些用来放返回值,等等。但是,如果你要使用别的语言编译好的目标文件,或者你想让自己的编译器生成的目标文件被别人使用,那你就要遵守某种特定的 ABI 标准。
09 | Java编译器(一):手写的编译器有什么优势?
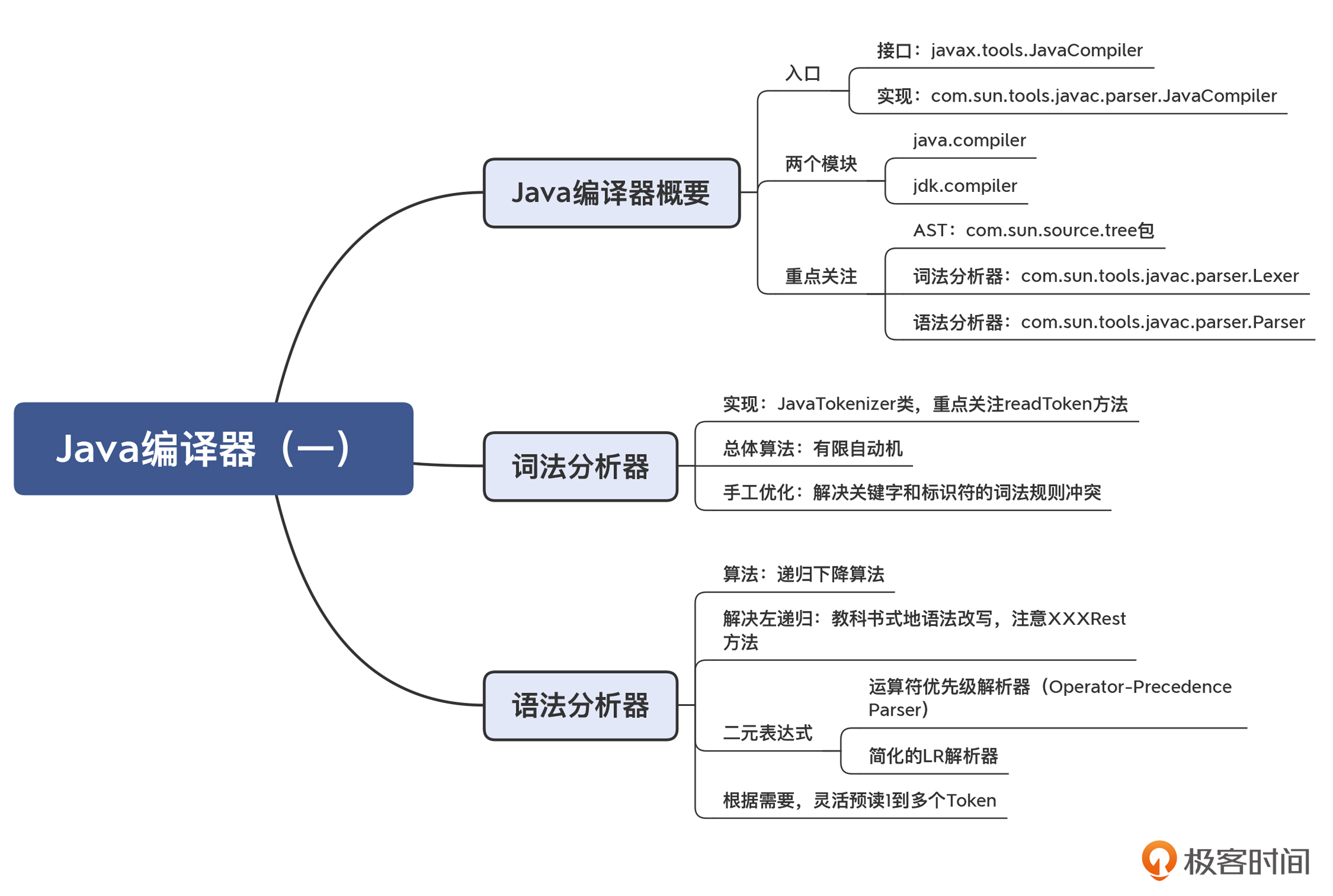
对于java这么一门成熟的、广泛普及的、又不断焕发新生机的语言来说,研究它的编译技术会带来两个好处:一方面,Java 编译器所采用的技术肯定是比较成熟的、靠谱的,你在实现自己的编译功能时,完全可以去参考和借鉴;另一方面,你可以借此深入了解 Java 的编译过程,借此去实现一些高级的功能,比方说,按需生成字节码,就像 Spring 这类工具一样。
Java 的编译器是用什么语言编写的?
Java 的词法分析器和语法分析器,是工具生成的,还是手工编写的?为什么会这样选择?
语法分析的算法分为自顶向下和自底向上的。那么 Java 的选择是什么呢?有什么道理吗?
如何自己动手修改 Java 编译器?
大多数 Java 工程师是通过 javac 命令来初次接触 Java 编译器的,那这个 javac 的可执行文件就是 Java 的编译器吗?并不是。javac 只是启动了一个 Java 虚拟机,执行了一个 Java 程序,跟我们平常用“java”命令运行一个程序是一样的。换句话说,Java 编译器本身也是用 Java 写的。
既然 Java 编译器是用 Java 实现的,那意味着你自己也可以写一个程序,来调用 Java 的编译器。比如,运行下面的示例代码,也同样可以编译 MyClass.java 文件,生成 MyClass.class 文件:
import javax.tools.JavaCompiler;
import javax.tools.ToolProvider;
public class CompileMyClass {
public static void main(String[] args) {
JavaCompiler compiler = ToolProvider.getSystemJavaCompiler();
int result = compiler.run(null, null, null, "MyClass.java");
System.out.println("Compile result code = " + result);
}
}其中,javax.tools.JavaCompiler 就是 Java 编译器的入口,属于 java.compiler 模块。这个模块包含了 Java 语言的模型、注解的处理工具,以及 Java 编译器的 API。
javax.tools.JavaCompiler 的实现是 com.sun.tools.javac.main.JavaCompiler。它在 jdk.compiler 模块中,这个模块里才是 Java 编译器的具体实现。
总结起来,Java 语言中与编译有关的功能放在了两个模块中:其中,java.compiler 模块主要是对外的接口,而 jdk.compiler 中有具体的实现。不过你要注意,像 com.sun.tools.javac.parser 包中的类,不是 Java 语言标准的组成部分,如果你直接使用这些类,可能导致代码在不同的 JDK 版本中不兼容。
10 | Java编译器(二):语法分析之后,还要做些什么?
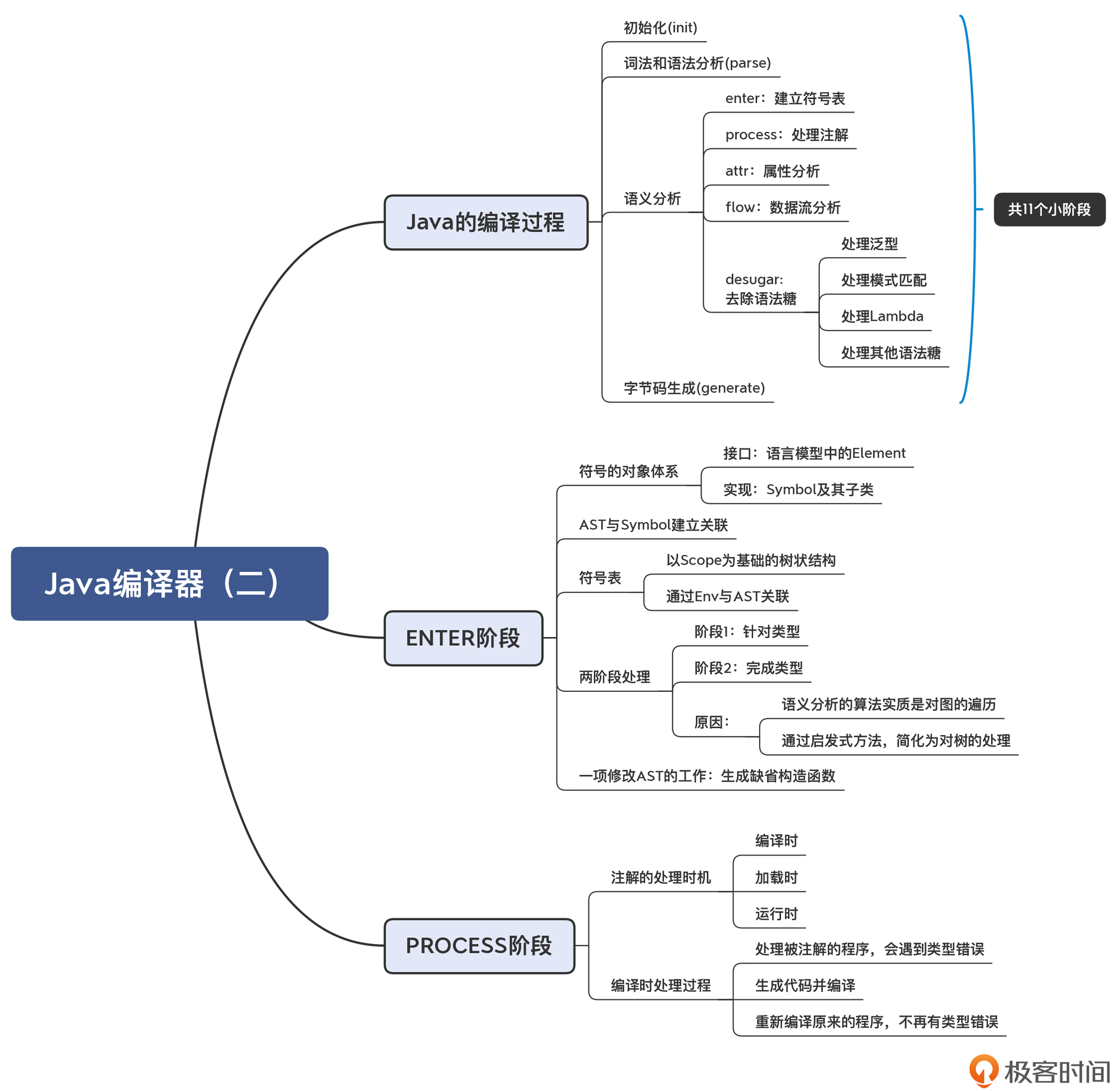
符号表是教科书上提到的一种数据结构,但它在 Java 编译器里是如何实现的?编译器如何建立符号表?
引用消解会涉及到作用域,那么作用域在 Java 编译器里又是怎么实现的?
在编译期是如何通过注解的方式生成新程序的?
11 | Java编译器(三):属性分析和数据流分析
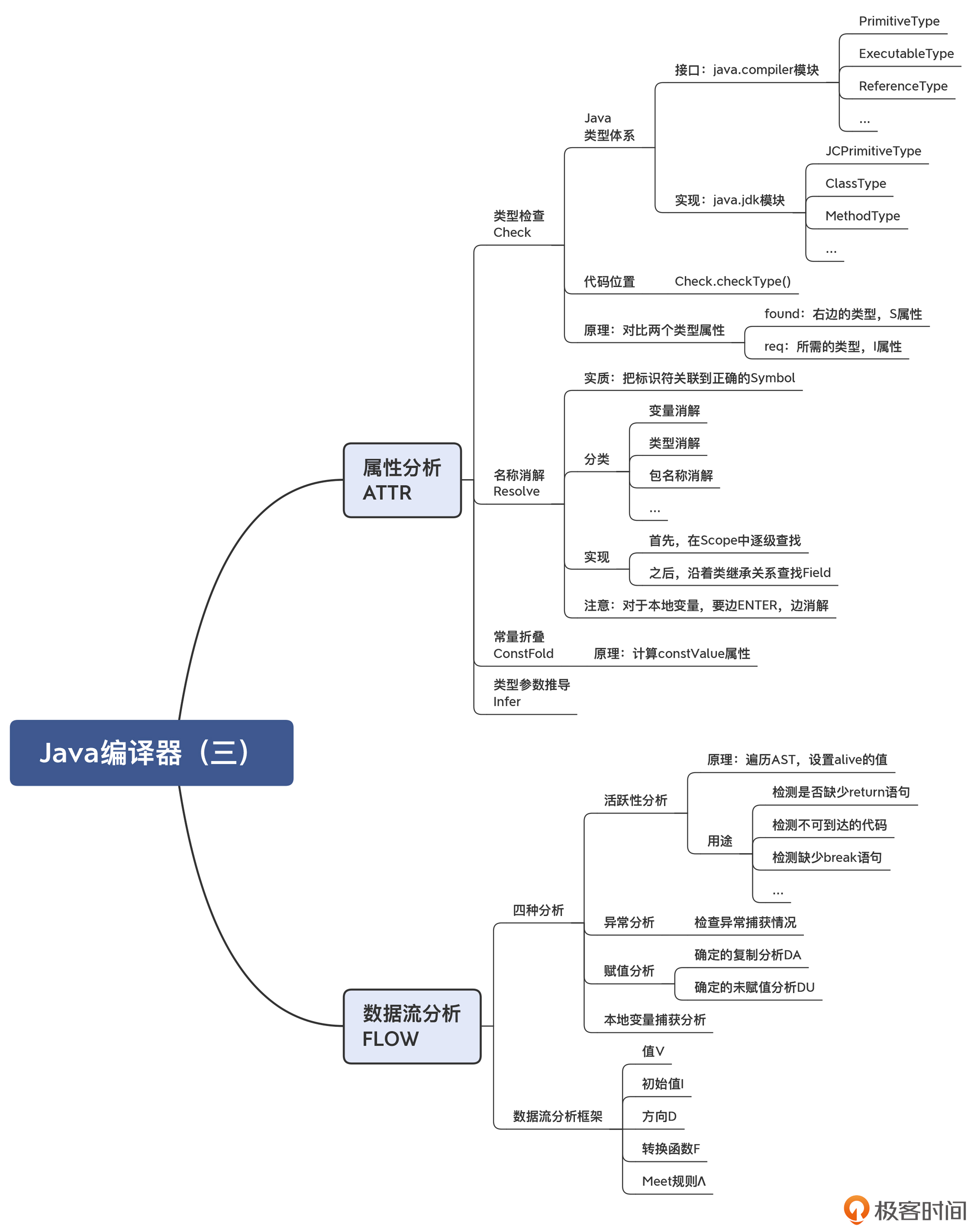
常数折叠
我们知道,优化工作通常是在编译器的后端去做的。但因为 javac 编译器只是个前端编译器,生成字节码就完成任务了。不过即使如此,也要保证字节码是比较优化的,减少解释执行的消耗。
触发上述常数折叠的代码,在 com.sun.tools.javac.comp.Attr 类的 visitBinary() 方法中,具体实现是在 com.sun.tools.javac.comp.ConstFold 类。它的计算逻辑是:针对每个 AST 节点的 type,可以通过 Type.constValue() 方法,看看它是否有常数值。如果二元表达式的两个子节点都有常数值,那么就可以做常数折叠,计算出的结果保存在父节点的 type 属性中。
你能看出,常数折叠实质上是针对 AST 节点的常数值属性来做属性计算的。
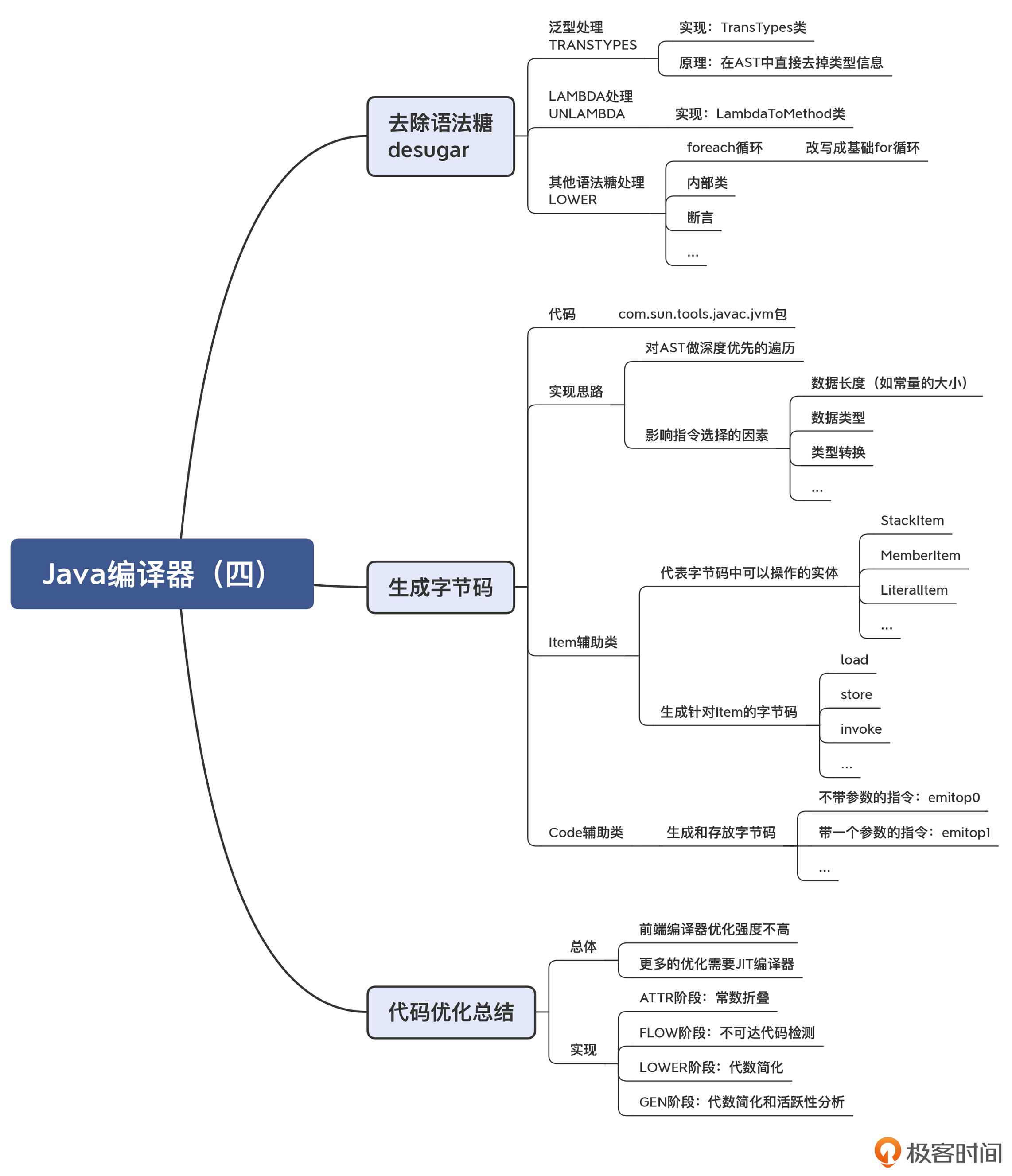
12 | Java编译器(四):去除语法糖和生成字节码
去除语法糖(Syntactic Sugar)
Java 里面提供了很多的语法糖,比如泛型、Lambda、自动装箱、自动拆箱、foreach 循环、变长参数、内部类、枚举类、断言(assert),等等。
你可以这么理解语法糖:它就是提高我们编程便利性的一些语法设计。既然是提高便利性,那就意味着语法糖能做到的事情,用基础语法也能做到,只不过基础语法可能更啰嗦一点儿而已。
不过,我们最终还是要把语法糖还原成基础语法结构。比如,foreach 循环会被还原成更加基础的 for 循环。
在 JDK14 中,去除语法糖涵盖了编译过程的四个小阶段。
- TRANSTYPES:泛型处理,具体实现在 TransTypes 类中。
- TRANSPATTERNS:处理模式匹配,具体实现在 TransPattern 类中。
- UNLAMBDA:把 LAMBDA 转换成普通方法,具体实现在 LambdaToMethod 类中。
- LOWER:其他所有的语法糖处理,如内部类、foreach 循环、断言等,具体实现在 Lower 类中。
以上去除语法糖的处理逻辑都是相似的,它们的本质都是对 AST 做修改和变换。
泛型的处理
Java 泛型的实现比较简单,LinkedList<String>和 LinkedList 对应的字节码其实是一样的。泛型信息<String>,只是用来在语义分析阶段做类型的检查。检查完之后,这些类型信息就会被去掉。所以,Java 的泛型处理,就是把 AST 中与泛型有关的节点简单地删掉(相关的代码在 TransTypes 类中)。
foreach 循环的处理
public static void main(String args[]) {
List<String> names = new ArrayList<String>();
...
//foreach循环
for (String name:names)
System.out.println(name);
//基础for循环
for ( Iterator i = names.iterator(); i.hasNext(); ) {
String name = (String)i.next();
System.out.println(name);
}
}对 foreach 循环的处理,是在 Lower 类的 visitForeachLoop 方法中。
其实,你在阅读编译技术相关的文献时,应该经常会看到 Lower 这个词。它的意思是,让代码从对人更友好的状态,变换到对机器更友好的状态。比如说,语法糖对编程人员更友好,而基础的语句则相对更加靠近机器实现的一端,所以去除语法糖的过程是 Lower。除了去除语法糖,凡是把代码向着机器代码方向所做的变换,都可以叫做 Lower。以后你再见到 Lower 的时候,是不是就非常清楚它的意思了呢。
通过对泛型和 foreach 循环的处理方式的探讨,现在你应该已经大致了解了去除语法糖的过程。总体来说,去除语法糖就是把 AST 做一些变换,让它变成更基础的语法要素,从而离生成字节码靠近了一步。
生成字节码(Bytecode Generation)
一般来说,我们会有一个错觉,认为生成字节码比较难。
实际情况并非如此,因为通过前面的建立符号表、属性计算、数据流分析、去除语法糖的过程,我们已经得到了一棵标注了各种属性的 AST,以及保存了各种符号信息的符号表。最难的编译处理工作,在这几个阶段都已经完成了。
在第 8 讲中,我就介绍过目标代码的生成。其中比较难的工作,是指令选择、寄存器分配和指令排序。而这些难点工作,在生成字节码的过程中,基本上是不存在的。在少量情况下,编译器可能会需要做一点指令选择的工作,但也都非常简单,你在后面可以看到。
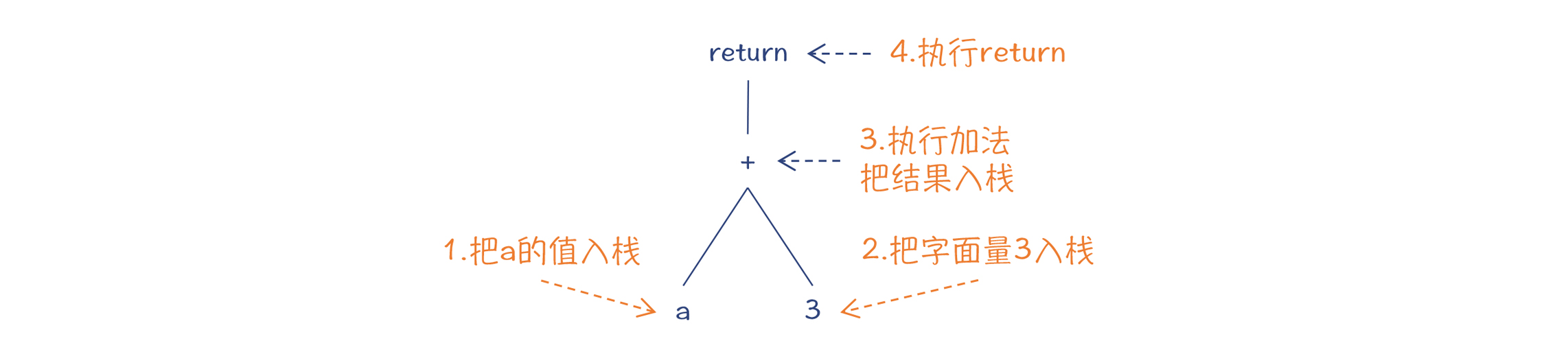
我们通过一个例子,来看看生成字节码的过程:
public class MyClass {
public int foo(int a){
return a + 3;
}
}
// 对应的字节码
public int foo(int);
Code:
0: iload_1 //把下标为1的本地变量(也就是参数a)入栈
1: iconst_3 //把常数3入栈
2: iadd //执行加法操作
3: ireturn //返回生成字节码,基本上就是对 AST 做深度优先的遍历,逻辑特别简单。我们在第 5 讲曾经介绍过栈机的运行原理,也提到过栈机的一个优点,就是生成目标代码的算法比较简单。
OK,到这里,我已经总结了影响指令生成的一些因素,包括字面量的长度、数据类型等。你能体会到,这些指令选择的逻辑都是很简单的,基于当前 AST 节点的属性,编译器就可以做成正确的翻译了,所以它们基本上属于“直译”。
现在你对生成字节码的基本原理搞清楚了以后,再来看 Java 编译器的具体实现,就容易多了。
生成字节码的程序入口在 com.sun.tools.javac.jvm.Gen 类中。这个类也是 AST 的一个 visitor。这个 visitor 把 AST 深度遍历一遍,字节码就生成完毕了。
在 com.sun.tools.javac.jvm 包中,有两个重要的辅助类。
第一个辅助类是 Item。包的内部定义了很多不同的 Item,代表了在字节码中可以操作的各种实体,比如本地变量(LocalItem)、字面量(ImmediateItem)、静态变量(StaticItem)、带索引的变量(IndexedItem,比如数组)、对象实例的变量和方法(MemberItem)、栈上的数据(StackItem)、赋值表达式(AssignItem),等等。
每种 Item 都支持一套标准的操作,能够帮助生成字节码。我们最常用的是 load()、store()、invoke()、coerce() 这四个。
- load():生成把这个 Item 加载到栈上的字节码。
- store():生成从栈顶保存到该 Item 的字节码。
- invoke() : 生成调用该 Item 代表的方法的字节码。
- coerce():强制类型转换。
第二个辅助类是 Code 类。它里面有各种emitXXX() 方法,会生成各种字节码的指令。
总结起来,字节码生成的总体框架如下面的类图所示:
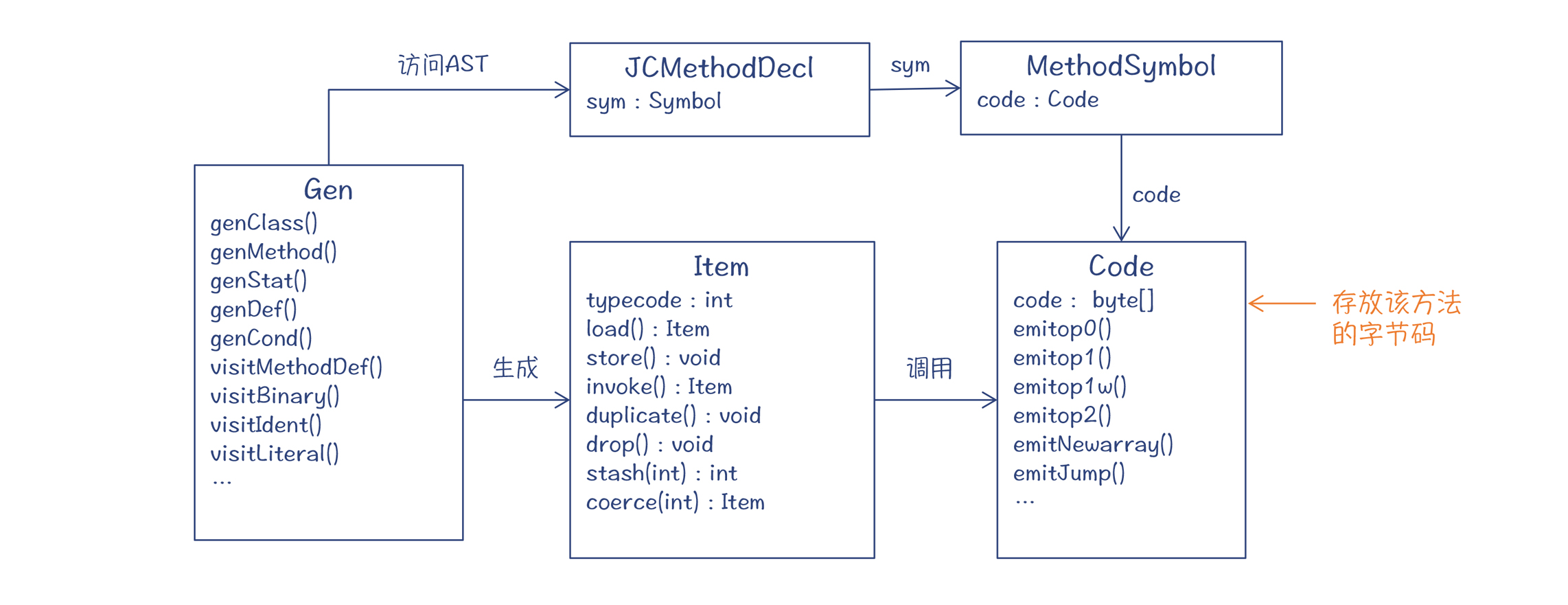
Gen 类以 visitor 模式访问 AST,生成字节码;最后生成的字节码保存在 Symbol 的 code 属性中。
在生成字节码的过程中,编译器会针对不同的 AST 节点,生成不同的 Item,并调用 Item 的 load()、store()、invoke() 等方法,这些方法会进一步调用 Code 对象的 emitXXX() 方法,生成实际的字节码。
代码优化
到这里,我们把去除语法糖和生成字节码两部分的内容都讲完了。但是,在 Java 编译器里,还有一类工作是分散在编译的各个阶段当中的,它们也很重要,这就是代码优化的工作。
1.ATTR 阶段:常数折叠
2.FLOW 阶段:不可达的代码
3.LOWER 阶段:代数简化, 比如:针对逻辑“或(OR)”和“与(AND)”运算
4.GEN 阶段:代数简化和活跃性分析
在生成字节码的时候,也会做一些代数简化。比如在 Gen.visitBinary() 方法中,有跟 Lower.visitBinary() 类似的逻辑。而整个生成代码的过程,也有类似 FLOW 阶段的活跃性分析的逻辑,对于不可达的代码,就不再生成字节码。
看上去 GEN 阶段的优化算法是冗余的,跟前面的阶段重复了。但是这其实有一个好处,也就是可以把生成字节码的部分作为一个单独的库使用,不用依赖前序阶段是否做了某些优化。
总结起来,Java 编译器在多个阶段都有一点代码优化工作,但总体来看,代码优化是很不足的。真正的高强度的优化,还是要去看 Java 的 JIT 编译器。这些侧重于做优化的编译器,有时就会被叫做“优化编译器(Optimizing Compiler)”。
13 | Java JIT编译器(一):动手修改Graal编译器
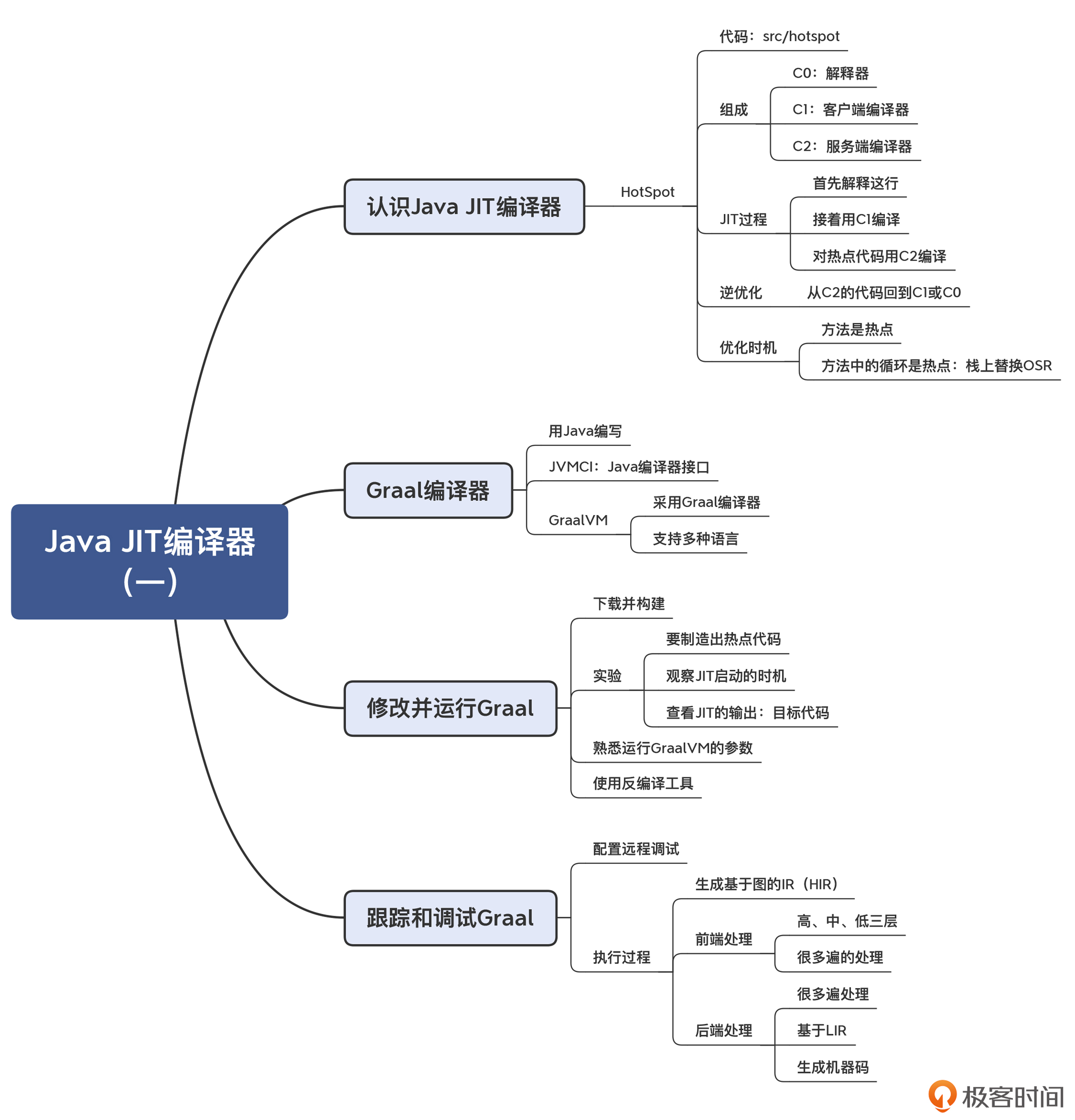
认识 Java 的 JIT 编译器
在 JDK 的源代码中,你能找到 src/hotspot 目录,这是 JVM 的运行时,它们都是用 C++ 编写的,其中就包括 JIT 编译器。标准 JDK 中的虚拟机呢,就叫做 HotSpot。
实际上,HotSpot 带了两个 JIT 编译器,一个叫做 C1,又叫做客户端编译器,它的编译速度快,但优化程度低。另一个叫做 C2,又叫做服务端编译器,它的编译速度比较慢,但优化程度更高。这两个编译器在实际的编译过程中,是被结合起来使用的。而字节码解释器,我们可以叫做是 C0,它的运行速度是最慢的。
在运行过程中,HotSpot 首先会用 C0 解释执行;接着,HotSpot 会用 C1 快速编译,生成机器码,从而让运行效率提升。而对于运行频率高的热点(HotSpot)代码,则用 C2 深化编译,得到运行效率更高的代码,这叫做分层编译(Tiered Compilation)。

由于 C2 会做一些激进优化,比如说,它会根据程序运行的统计信息,认为某些程序分支根本不会被执行,从而根本不为这个分支生成代码。不过,有时做出这种激进优化的假设其实并不成立,那这个时候就要做一个逆优化(Deoptimization),退回到使用 C1 的代码,或退回到用解释器执行。
触发即时编译,需要检测热点代码。一般是以方法为单位,虚拟机会看看该方法的运行频次是否很高,如果运行特别频繁,那么就会被认定为是热点代码,从而就会被触发即时编译。甚至如果一个方法里,有一个循环块是热点代码(比如循环 1.5 万次以上),这个时候也会触发编译器去做即时编译,在这个方法还没运行完毕的时候,就被替换成了机器码的版本。由于这个时候,该方法的栈帧还在栈上,所以我们把这个技术叫做栈上替换(On-stack Replacement,OSR)。栈上替换的技术难点,在于让本地变量等数据无缝地迁移,让运行过程可以正确地衔接。
Graal:用 Java 编写的 JIT 编译器
如果想深入地研究 Java 所采用的 JIT 编译技术,我们必须去看它的源码。可是,对于大多数 Java 程序员来说,如果去阅读 C++ 编写的编译器代码,肯定会有些不适应。
一个好消息是,Oracle 公司推出了一个完全用 Java 语言编写的 JIT 编译器:Graal,并且也有开放源代码的社区版,你可以下载安装并使用。
Oracle 公司还专门推出了一款 JVM,叫做 GraalVM。它除了用 Graal 作为即时编译器以外,还提供了一个很创新的功能:在一个虚拟机上支持多种语言,并且支持它们之间的互操作。你知道,传统的 JVM 上已经能够支持多种语言,比如 Scala、Clojure 等。而新的 GraalVM 会更进一步,它通过一个 Truffle 框架,可以支持 JavaScript、Ruby、R、Python 等需要解释执行的语言。
再进一步,它还通过一个 Sulong 框架支持 LLVM IR,从而支持那些能够生成 LLVM IR 的语言,如 C、C++、Rust 等。想想看,在 Java 的虚拟机上运行 C 语言,还是有点开脑洞的!
最后,GraalVM 还支持 AOT 编译,这就让 Java 可以编译成本地代码,让程序能更快地启动并投入高速运行。我听说最近的一些互联网公司,已经在用 Graal 做 AOT 编译,来生成本地镜像,提高应用的启动时间,从而能够更好地符合云原生技术的要求。
JIT 所做的工作,本质上就是把字节码的 Byte 数组翻译成机器码的 Byte 数组,在翻译过程中,编译器要参考一些元数据信息(符号表等),再加上运行时收集的一些信息(用于帮助做优化)。
参考链接
过两年 JVM 可能就要被 GraalVM 替代了-腾讯云开发者社区-腾讯云
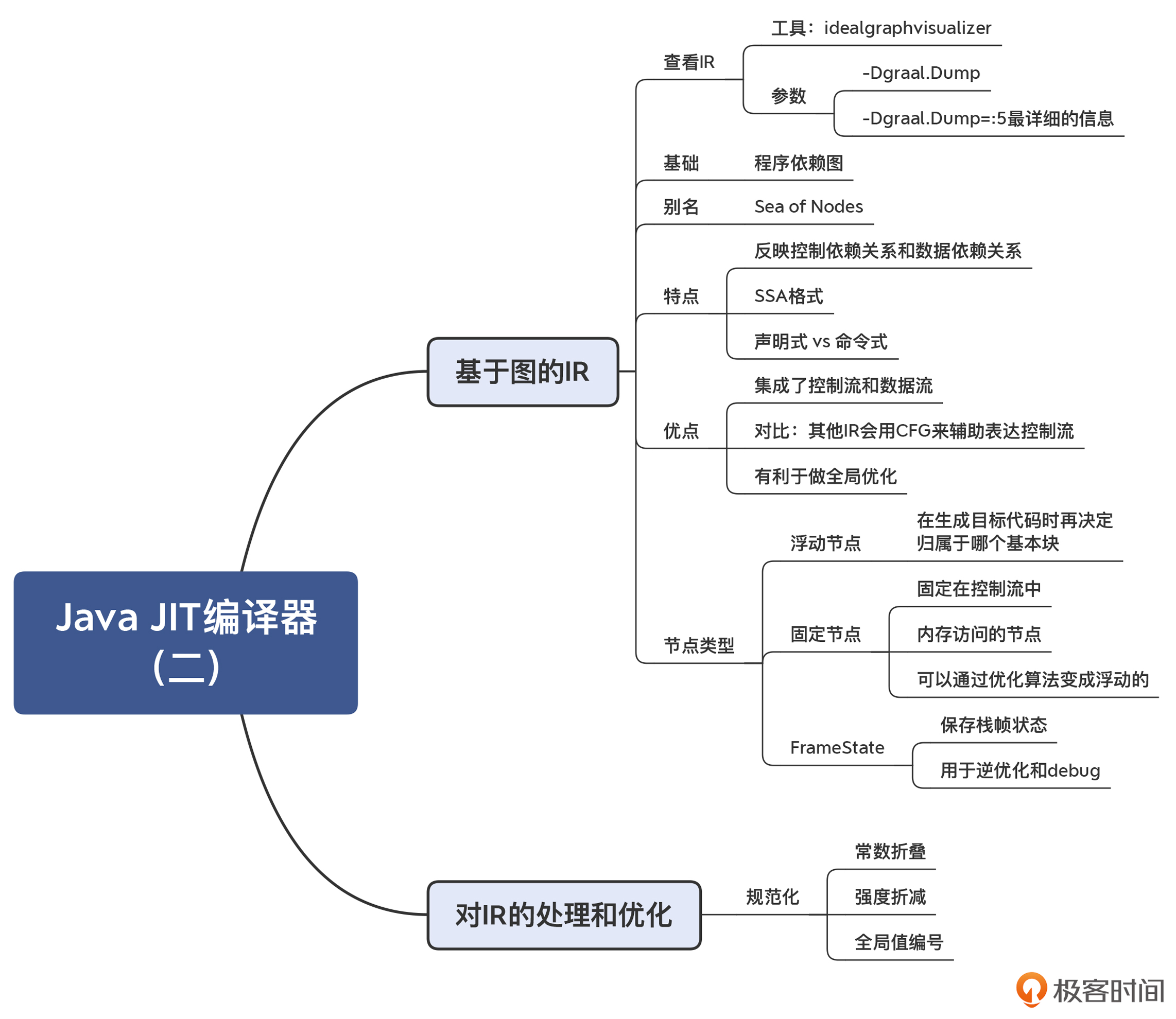
14 | Java JIT编译器(二):Sea of Nodes为何如此强大?
在上一讲中,我们发现 Graal 在执行过程中,创建了一个图的数据结构,这个数据结构就是 Graal 的 IR。之后的很多处理和优化算法,都是基于这个 IR 的。可以说,这个 IR 是 Graal 编译器的核心特性之一。
Graal IR 其实受到了“程序依赖图”的影响。我们在第 6 讲中提到过程序依赖图(PDG),它是用图来表示程序中的数据依赖和控制依赖。并且你也知道了,这种 IR 还有一个别名,叫做节点之海(Sea of Nodes)。因为当程序稍微复杂一点以后,图里的节点就会变得非常多,我们用肉眼很难看得清。基于 Sea of Nodes 的 IR 呢,算是后起之秀。在 HotSpot 的编译器中,就采用了这种 IR,而且现在 Java 的 Graal 编译器和 JavaScript 的 V8 编译器中的 IR 的设计,都是基于了 Sea of Nodes 结构,所以我们必须重视它。
Sea of Nodes 到底强在哪里?
我们都知道,数据结构的设计对于算法来说至关重要。IR 的数据结构,会影响到算法的编写方式。好的 IR 的设计,会让优化算法的编写和维护都更加容易。
而 Sea of Nodes 最大的优点,就是能够用一个数据结构同时反映控制流和数据流,并且尽量减少它们之间的互相依赖。
怎么理解这个优点呢?在传统的编译器里,控制流和数据流是分开的。控制流是用控制流图(Control-flow Graph,CFG)来表示的,比如 GNU 的编译器、LLVM,都是基于控制流图的。而 IR 本身,则侧重于表达数据流。
以 LLVM 为例,它采用了 SSA 格式的 IR,这种 IR 可以很好地体现值的定义和使用关系,从而很好地刻画了数据流。
而问题在于,采用这种比较传统的方式,控制流和数据流会耦合得比较紧,因为 IR 指令必须归属于某个基本块。
举个例子来说明一下吧。在下面的示例程序中,“int b = a*2;”这个语句,会被放到循环体的基本块中。
int foo(int a){
int sum = 0;
for(int i = 0; i< 10; i++){
int b = a*2; //这一句可以提到外面
sum += b;
}
}可是,从数据流的角度看,变量 b 只依赖于 a。所以这个语句没必要放在循环体内,而是可以提到外面。在传统的编译器中,这一步是要分析出循环无关的变量,然后再把这条语句提出去。而如果采用 Sea of Nodes 的数据结构,变量 b 一开始根本没有归属到特定的基本块,所以也就没有必要专门去做代码的移动了。
另外,我们之前讲本地优化和全局优化的时候,也提到过,它们的区别就是,在整个函数范围内,优化的范围是在基本块内还是会跨基本块。而 Sea of Nodes 没有过于受到基本块的束缚,因此也就更容易做全局优化了。
总结一下:控制流图表达的是控制的流转,而数据流图代表的是数据之间的依赖关系。二者双剑合璧,代表了源程序完整的语义。
浮动节点和固定节点
注意,在 Graal IR,数据流与控制流是相对独立的。你看看前面的 doif 示例程序,会发现x+y和x*y的计算,与 if 语句的控制流没有直接关系。所以,你其实可以把这两个语句挪到 if 语句外面去执行,也不影响程序运行的结果(要引入两个临时变量 z1 和 z2,分别代表 z 的两个取值)。
对于这些在执行时间上具有灵活性的节点,我们说它们是浮动的(Floating)。你在 AddNode 的继承层次中,可以看到一个父类:FloatingNode,这说明这个节点是浮动的。它可以在最后生成机器码(或 LIR)的环节,再去确定到底归属哪个基本块。
除了浮动节点以外,还有一些节点是固定在控制流中的,前后顺序不能乱,这些节点叫做固定节点。除了那些流程控制类的节点(如 IfNode)以外,还有一些节点是固定节点,比如内存访问的节点。当你访问一个对象的属性时,就需要访问内存。
课程小结
这一讲,我给你介绍了 Graal 的 IR:它整合了控制流图与数据流图,符合 SSA 格式,有利于优化算法的编写和维护。
我还带你了解了对 IR 的一个优化处理过程:规范化。规范化所需要的操作一般并不复杂,它都是对本节点进行修改和替换。在下一讲中,我会带你分析另外两个重要的算法,内联和逃逸分析。
另外,Graal 的 IR 格式是声明式的(Declarative),它通过描述一个节点及其之间的关系来反映源代码的语义。而我们之前见到的类似三地址代码那样的格式,是命令式的(Imperative),它的风格是通过命令直接告诉计算机,来做一个个的动作。
声明式和命令式是编程的两种风格,在 Graal 编译器里,我们可以看到声明式的 IR 会更加简洁,对概念的表达也更加清晰。我们在后面介绍 MySQL 编译器的实现机制当中,在讲 DSL 的时候,还会再回到这两个概念,到时你还会有更加深刻的认识。
15 | Java JIT编译器(三):探究内联和逃逸分析的算法原理
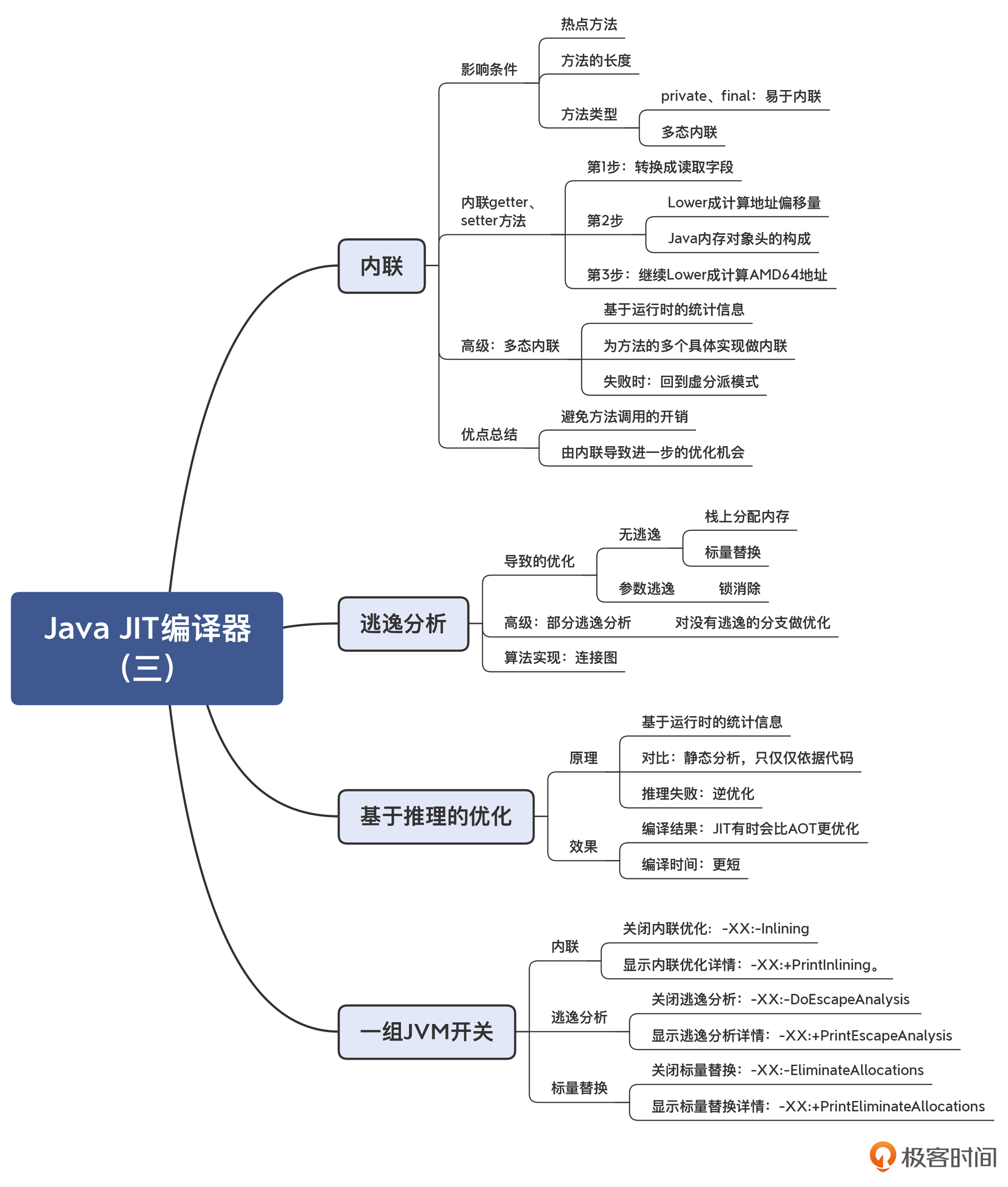
今天这一讲,我就带你来认识两个对 Java 来说很重要的优化算法。如果没有这两个优化算法,你的程序执行效率会大大下降。而如果你了解了这两个算法的机理,则有可能写出更方便编译器做优化的程序,从而让你在实际工作中受益。这两个算法,分别是内联和逃逸分析。
另外,我还会给你介绍一种 JIT 编译所特有的优化模式:基于推理的优化。这种优化模式会让某些程序比 AOT 编译的性能更高。这个知识点,可能会改变你对 JIT 和 AOT 的认知,因为通常来说,你可能会认为 AOT 生成的机器码速度更快
内联(Inlining)
内联优化是 Java JIT 编译器非常重要的一种优化策略。简单地说,内联就是把被调用的方法的方法体,在调用的地方展开。这样做最大的好处,就是省去了函数调用的开销。对于频繁调用的函数,内联优化能大大提高程序的性能。
执行内联优化是有一定条件的。第一,被内联的方法要是热点方法;第二,被内联的方法不能太大,否则编译后的目标代码量就会膨胀得比较厉害。
在 Java 程序里,你经常会发现很多短方法,特别是访问类成员变量的 getter 和 setter 方法。这些调用如果不做优化的话,性能损失是很厉害的。
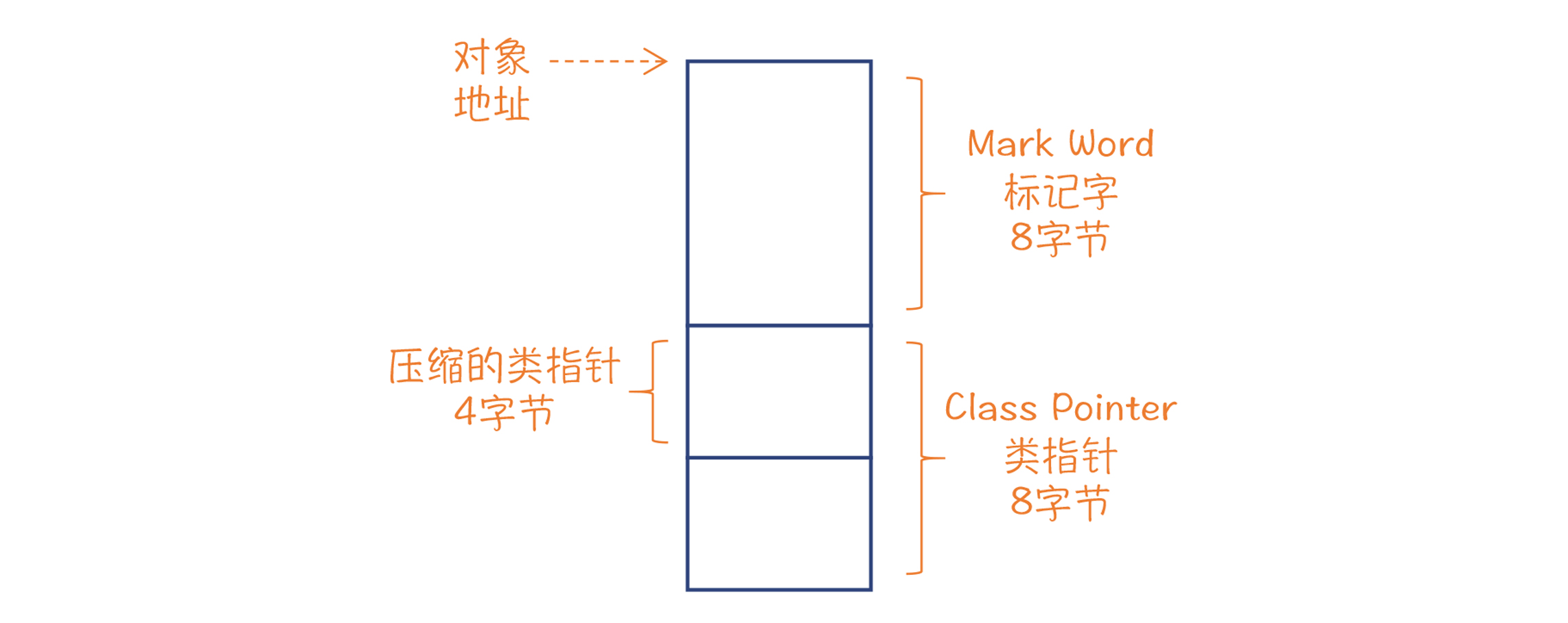
而要想正确地计算字段的偏移量,我们还需要了解 Java 对象的内存布局。
在 64 位平台下,每个 Java 对象头部都有 8 字节的标记字,里面有对象 ID 的哈希值、与内存收集有关的标记位、与锁有关的标记位;标记字后面是一个指向类定义的指针(知道定义了,也就知道如何进行偏移了),在 64 位平台下也是 8 位,不过如果堆不是很大,我们可以采用压缩指针,只占 4 个字节;在这后面才是 x 和 y 字段。因此,x 和 y 的偏移量分别是 12 和 16。
另外,方法的类型也会影响 inlining。如果方法是 final 的,或者是 private 的,那么它就不会被子类重载,所以可以大胆地内联。
但如果存在着多重继承的类体系,方法就有可能被重载,这就会导致多态。在运行时,JVM 会根据对象的类型来确定到底采用哪个子类的具体实现。这种运行时确定具体方法的过程,叫做虚分派(Virtual Dispatch)。
在存在多态的情况下,JIT 编译器做内联就会遇到困难了。因为它不知道把哪个版本的实现内联进来。不过编译器仍然没有放弃。这时候所采用的技术,就叫做“多态内联(Polymorphic inlining)”。
它的具体做法是,在运行时,编译器会统计在调用多态方法的时候,到底用了哪几个实现。然后针对这几个实现,同时实现几个分支的内联,并在一开头根据对象类型判断应该走哪个分支。这个方法的缺陷是生成的代码量会比较大,但它毕竟可以获得内联的好处。最后,如果实际运行中遇到的对象,与提前生成的几个分支都不匹配,那么编译器还可以继续用缺省的虚分派模式来做函数调用,保证程序不出错。
这个案例也表明了,JIT 编译器是如何充分利用运行时收集的信息来做优化的。对于 AOT 模式的编译来说,由于无法收集到这些信息,因此反倒无法做这种优化。
逃逸分析(Escape Analysis, EA)
逃逸分析能够让编译器判断出,一个对象是否能够在创建它的方法或线程之外访问。如果只能在创建它的方法内部访问,我们就说这个对象不是方法逃逸的;如果仅仅逃逸出了方法,但对这个对象的访问肯定都是在同一个线程中,那么我们就说这个对象不是线程逃逸的。
判断是否逃逸有什么用呢?用处很大。只要我们判断出了该对象没有逃逸出方法或线程,就可以采用更加优化的方法来管理该对象。
首先是栈上分配内存。
在 Java 语言里,对象的内存通常都是在堆中申请的。对象不再被访问以后,会由垃圾收集器回收。但对于这个例子来说,Person 对象的生命周期跟 escapeTest() 方法的生命周期是一样的。在退出方法后,就不再会有别的程序来访问该对象。
换句话说,这个对象跟一个 int 类型的本地变量没啥区别。那么也就意味着,我们其实可以在栈里给这个对象申请内存就行了。
你已经知道,在栈里申请内存会有很多好处:可以自动回收,不需要浪费 GC 的计算量去回收内存;可以避免由于大量生成小对象而造成的内存碎片;数据的局部性也更好,因为在堆上申请内存,它们的物理地址有可能是不相邻的,从而降低高速缓存的命中率;再有,在并发计算的场景下,在栈上分配内存的效率更高,因为栈是线程独享的,而在堆中申请内存可能需要多线程之间同步。所以,我们做这个优化是非常有价值的。
还可以做标量替换(Scalar Replacement)
这是什么意思呢?你会发现,示例程序仅仅用到了 Person 对象的 age 成员变量,而 weight 根本没有涉及。所以,我们在栈上申请内存的时候,根本没有必要为 weight 保留内存。同时,在一个 Java 对象的标准内存布局中,还要有一块固定的对象头的内存开销。在 64 位平台,对象头可能占据了 16 字节。这下倒好,示例程序本来只需要 4 个字节的一个整型,最后却要申请 24 个字节,是原需求的 6 倍,这也太浪费了。
通过标量替换的技术,我们可以根本不生成对象实例,而是把要用到的对象的成员变量,作为普通的本地变量(也就是标量)来管理。
这么做还有一个好处,就是编译器可以尽量把标量放到寄存器里去,连栈都不用,这样就避免了内存访问所带来的性能消耗。
上面讲的都是没有逃逸出方法的情况。这种情况被叫做 NoEscape。还有一种情况,是虽然逃逸出了方法,但没有逃逸出当前线程,也就是说不可能被其他线程所访问,这种逃逸叫做 ArgEscape,也就是它仅仅是通过方法的参数逃逸的。最后一种情况就是 GlobalEscape,也就是能够被其他线程所访问,因此没有办法优化。
对于 ArgEscape 的情况,虽然编译器不能做内存的栈上分配,但也可以做一定的优化,这就是锁消除或者同步消除。
我们知道,在并发场景下,锁对性能的影响非常之大。而很多线程安全的对象,比如一些集合对象,它们的内部都采用了锁来做线程的同步。如果我们可以确定这些对象没有逃逸出线程,那么就可以把这些同步逻辑优化掉,从而提高代码的性能。
另外,我们前面所做的分析都是静态分析,也就是基于对代码所做的分析。对于一个对象来说,只要存在任何一个控制流,使得它逃逸了,那么编译器就会无情地把它标注为是逃逸对象,也就不能做优化了。但是,还会出现一种情况,就是有可能这个分支的执行频率特别少,大部分情况下该对象都是不逃逸的。
所以,Java 的 JIT 编译器实际上又向前迈进了一步,实现了部分逃逸分析(Partial Escape Analysis)。它会根据运行时的统计信息,对不同的控制流分支做不同的处理。对于没有逃逸的分支,仍然去做优化。在这里,你能体会到,编译器为了一点点的性能提升,简直无所不用其极呀。
基于推理的优化(Speculative Optimization)
在讲内联和逃逸算法的时候,我们都发现,编译器会根据运行时的统计信息,通过推断来做一些优化,比如多态内联、部分逃逸分析。而这种优化模式,就叫做基于推理的优化。
我刚刚说过,一般情况下,编译器的优化工作是基于对代码所做的分析,也就是静态分析。而 JIT 编译还有一个优势,就是会根据运行时收集的统计信息来做优化。
总结起来,基于运行时的统计信息进行推理的优化,有时会比基于静态分析的 AOT 产生出性能更高的目标代码。所以,现代编译技术的实践,会强调“全生命周期”优化的概念。甚至即使是 AOT 产生的目标代码,仍然可以在运行期通过 JIT 做进一步优化。
16 | Java JIT编译器(四):Graal的后端是如何工作的?
在对 HIR 的处理过程中,前期(High Tier、Mid Tier)基本上都是与硬件无关。到了后期(Low Tier),你会看到 IR 中的一些节点逐步开始带有硬件的特征,比如上一讲中,计算 AMD64 地址的节点。而 LIR 就更加反映目标硬件的特征了,基本上可以跟机器码一对一地翻译。所以,从 HIR 生成 LIR 的过程,就要做指令选择。
在 HIR 的最后的处理阶段,程序会通过一个 Schedule 过程,把 HIR 节点排序,并放到控制流图中,为生成 LIR 和目标代码做准备。我之前说过,HIR 的一大好处,就是那些浮动节点,可以最大程度地免受控制流的约束。但在最后生成的目标代码中,我们还是要把每行指令归属到某个具体的基本块的。而且,基本块中的 HIR 节点是按照顺序排列的,在 ScheduleResult 中保存着这个顺序(blockToNodesMap 中顺序保存了每个 Block 中的节点)。
你要注意,这里所说的 Schedule,跟编译器后端的指令排序不是一回事儿。这里是把图变成线性的程序;而编译器后端的指令排序(也叫做 Schedule),则是为了实现指令级并行的优化。
当然,把 HIR 节点划分到不同的基本块,优化程度是不同的。比如,与循环无关的代码,放在循环内部和外部都是可以的,但显然放在循环外部更好一些。把 HIR 节点排序的 Schedule 算法,复杂度比较高,所以使用了很多启发式的规则。刚才提到的把循环无关代码放在循环外面,就是一种启发式的规则。
图 2 中的 ControlFlowGraph 类和 Block 类构成了控制流图,控制流图和最后阶段的 HIR 是互相引用的。这样,你就可以知道 HIR 中的每个节点属于哪个基本块,也可以知道每个基本块中包含的 HIR 节点。
做完 Schedule 以后,接着就会生成 LIR。与声明式的 HIR 不同,LIR 是命令式的,由一行行指令构成。
后端的其他功能
出于突出特色功能的目的,这一讲我着重讲了 LIR 的特点和指令选择算法。不过在考察编译器的后端的时候,我们通常还要注意一些其他功能,比如寄存器分配算法、指令排序,等等。我这里就把 Graal 在这些功能上的实现特点,给你简单地介绍一下,你如果有兴趣的话,可以根据我的提示去做深入了解:
- 寄存器分配:Graal 采用了线性扫描(Linear Scan)算法。这个算法的特点是速度比较快,但优化效果不如图染色算法。在 HotSpot 的 C2 中采用的是后者。
- 指令排序:Graal 没有为了实现指令级并行而去做指令排序。这里一个主要原因,是现在的很多 CPU 都已经支持乱序(out-of-order)执行,再做重排序的收益不大。
- 窥孔优化:Graal 在生成 LIR 的时候,会做一点窥孔优化(AMD64NodeLIRBuilder 类的peephole方法)。不过它的优化功能有限,只实现了针对除法和求余数计算的一点优化。
- 从 LIR 生成目标代码:由于 LIR 已经跟目标代码很接近了,所以这个翻译过程已经比较简单,没有太难的算法了,需要的只是了解和熟悉汇编代码和调用约定。
17 | Python编译器(一):如何用工具生成编译器?
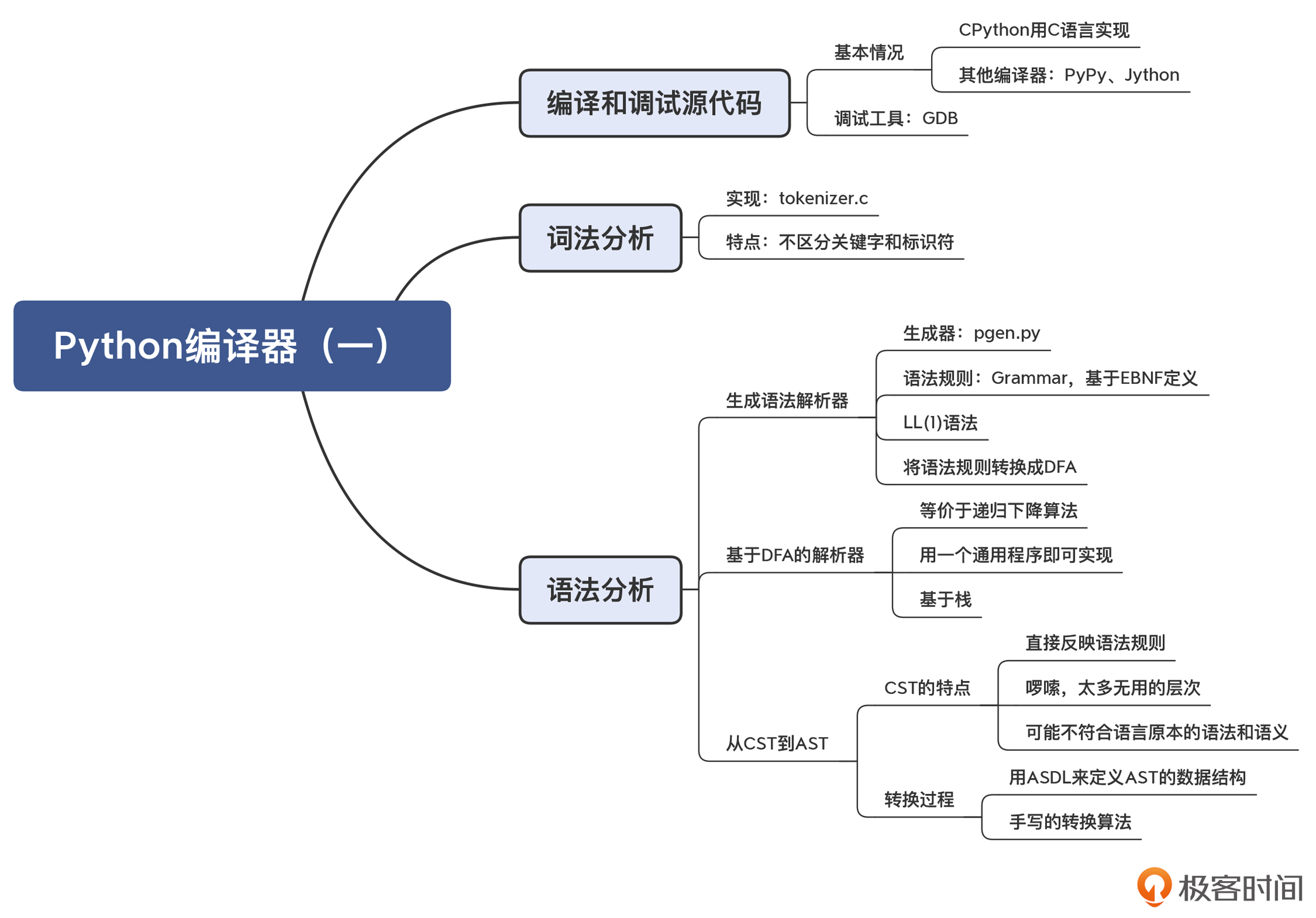
首先,你会发现 Python 编译器是用 C 语言编写的。这跟 Java、Go 的编译器不同,Java 和 Go 语言的编译器是支持自举的编译器,也就是这两门语言的编译器是用这两门语言自身实现的。
实际上,用 C 语言实现的 Python 编译器叫做 CPython,是 Python 的几个编译器之一。它的标准库也是由 C 语言和 Python 混合编写的。我们课程中所讨论的就是 CPython,它是 Python 语言的参考实现,也是 macOS 和 Linux 缺省安装的版本。
PyPy 是用 RPython(Restricted Python) 编写的,RPython 是 Python 的一个子集。在 PyPy 的开发过程中,RPython 被用作实现语言,而 PyPy 解释器的核心部分会被转换成 C 语言并编译成机器码。下面是 PyPy 运行的基本流程:
1. 编写 PyPy 解释器: PyPy 解释器的核心部分是用 RPython 编写的。RPython 是一个受限制的 Python 子集,它强制要求开发者在编写代码时使用静态类型。这是为了使得解释器的核心部分能够被 JIT 编译。PyPy比CPython快主要是用了JIT
2. RPython 转换: 使用 RPython 工具链,将 RPython 代码转换成 C 语言。这个过程会进行一些静态分析和类型推断,生成对应的 C 代码。
3. C 语言编译: 生成的 C 代码可以被传递给 C 编译器,如 GCC,进行编译成本地机器码。
4. 生成可执行文件: 编译得到的本地机器码可以被链接成一个可执行文件,这就是最终的 PyPy 解释器。
5. 运行 PyPy 解释器: 得到可执行文件后,用户可以通过运行这个文件来启动 PyPy 解释器。在运行时,PyPy 解释器会接受用户的 Python 代码作为输入,并通过 JIT 编译技术将其转换成本地机器码进行执行。
pypy这么强,快和省都占了,为什么没有大规模流行起来呢? 我个人认为,主要还是python的原因。
1. python生态中大量库采用c实现,特别是科学计算/AI相关的库,pypy在这块并没有优势。pypy快的主要在pure-python,也就是纯粹的python实现部分。
2. pypy适合长驻内存的高并发应用(web服务类)
3. python是一门胶水语言,并不追求性能极致,即使快4倍也不够快
Jython 是一个在 Java 平台上运行的 Python 解释器,它的运行原理与标准的 CPython 解释器有很大的不同。以下是 Jython 的主要运行原理:
1. Python 代码解析: 用户编写的 Python 代码首先会被 Jython 解释器进行解析。这个解析过程将 Python 代码转换成解释器可以理解的中间表示形式。
2. 中间表示到Java字节码: Jython 解释器将 Python 代码的中间表示形式翻译成 Java 字节码。Java 字节码是 Java 虚拟机(JVM)可执行的二进制指令。
3. Java虚拟机执行: 生成的 Java 字节码被传递给 Java 虚拟机执行。因为 Jython 是在 Java 平台上运行的,所以它利用了 Java 虚拟机的跨平台性,用户可以在任何支持 Java 的平台上运行 Jython。
4. Python标准库与Java互操作: Jython 提供了与 Java 的无缝互操作性。通过 Jython,你可以直接调用 Java 类库中的类和方法,并在 Python 代码中使用 Java 对象。这使得在 Java 平台上使用 Python 变得更加方便。
Python 编译器采用了一个通用的语法分析程序,以一个栈作为辅助的数据结构,来完成各个语法规则的解析工作。当前正在解析的语法规则对应的 DFA,位于栈顶。一旦当前的语法规则匹配完毕,那语法分析程序就可以把这个 DFA 弹出,退回到上一级的语法规则。
所以说,语法解析器生成工具,会基于不同的语法规则来生成不同的 DFA,但语法解析程序是不变的。这样,你随意修改语法规则,都能够成功解析。
解析树和 AST 的区别
解析树又可以叫做 CST(Concret Syntax Tree,具体语法树),与 AST(抽象语法树)是相对的:一个具体,一个抽象。
它俩的区别在于:CST 精确地反映了语法规则的推导过程,而 AST 则更准确地表达了程序的结构
总结起来,在编译器里,我们经常需要把源代码转变成 CST,然后再转换成 AST。生成 CST 是为了方便编译器的解析过程。而转换成 AST 后,会让树结构更加精简,并且在语义上更符合语言原本的定义。
那么,Python 是如何把 CST 转换成 AST 的呢?这个过程分为两步。
首先,Python 采用了一种叫做 ASDL 的语言,来定义了 AST 的结构。ASDL是“抽象语法定义语言(Abstract Syntax Definition Language)”的缩写,它可以用于描述编译器中的 IR 以及其他树状的数据结构。你可能不熟悉 ASDL,但可能了解 XML 和 JSON 的 Schema,你可以通过 Schema 来定义 XML 和 JSON 的合法的结构。另外还有 DTD、EBNF 等,它们的作用都是差不多的。
这个定义文件是 Parser/Python.asdl。CPython 编译器中包含了两个程序(Parser/asdl.py 和 Parser/asdl_c.py)来解析 ASDL 文件,并生成 AST 的数据结构。最后的结果在 Include/Python-ast.h 文件中。
到这里,你可能会有疑问:这个 ASDL 文件及解析程序不就是生成了 AST 的数据结构吗?为什么不手工设计这些数据结构呢?有必要采用一种专门的 DSL 来做这件事情吗?
确实如此。Java 语言的 AST,只是采用了手工设计的数据结构,也没有专门用一个 DSL 来生成。
但 Python 这样做确实有它的好处。上一讲我们说过,Python 的编译器有多种语言的实现,因此基于统一的 ASDL 文件,我们就可以精准地生成不同语言下的 AST 的数据结构。
在有了 AST 的数据结构以后,第二步,是把 CST 转换成 AST,这个工作是在 Python/ast.c 中实现的,入口函数是 PyAST_FromNode()。这个算法是手写的,并没有办法自动生成。
18 | Python编译器(二):从AST到字节码
像 Python 这样的动态语言,在语义分析阶段都要做什么事情呢,跟 Java 这样的静态类型语言有什么不同?
Python 的字节码有什么特点?生成字节码的过程跟 Java 有什么不同?
编译过程
Python 编译器把词法分析和语法分析叫做“解析(Parse)”,并且放在 Parser 目录下。而从 AST 到生成字节码的过程,才叫做“编译(Compile)”。当然,这里编译的含义是比较狭义的。你要注意,不仅是 Python 编译器,其他编译器也是这样来使用这两个词汇,包括我们已经研究过的 Java 编译器,你要熟悉这两个词汇的用法,以便阅读英文文献。
Python 的编译工作的主干代码是在 Python/compile.c 中,它主要完成 5 项工作。
第一步,检查future 语句。future 语句是 Python 的一个特性,让你可以提前使用未来版本的特性,提前适应语法和语义上的改变。这显然会影响到编译器如何工作。比如,对于“8/7”,用不同版本的语义去处理,得到的结果是不一样的。有的会得到整数“1”,有的会得到浮点数“1.14285…”,编译器内部实际上是调用了不同的除法函数。
第二步,建立符号表。
第三步,为基本块产生指令。
第四步,汇编过程:把所有基本块的代码组装在一起。
第五步,对字节码做窥孔优化。
语义分析:建立符号表和引用消解
通常来说,在语义分析阶段首先是建立符号表,然后在此基础上做引用消解和类型检查。而 Python 是动态类型的语言,类型检查应该是不需要了
首先,我们来看看 Python 的符号表是一个什么样的数据结构。在 Include/symtable.h 中定义了两个结构,分别是符号表和符号表的条目
在编译的过程中,针对每个模块(也就是一个 Python 文件)会生成一个符号表(symtable)。
Python 程序被划分成“块(block)”,块分为三种:模块、类和函数。每种块其实就是一个作用域,而在 Python 里面还叫做命名空间。每个块对应一个符号表条目(PySTEntryObject),每个符号表条目里存有该块里的所有符号(ste_symbols)。每个块还可以有多个子块(ste_children),构成树状结构。
课程小结
今天这一讲,我们继续深入探索 Python 的编译之旅。你需要记住以下几点:
- Python 通过一个建立符号表的过程来做相关的语义分析,包括做引用消解和其他语义检查。由于 Python 可以不声明变量就直接使用,所以编译器要能识别出正确的“定义 - 使用”关系。
- 生成字节码的工作实际上包含了生成 CFG、为每个基本块生成指令,以及把指令汇编成字节码,并生成 PyCodeObject 对象的过程。
- 窥孔优化器在字节码的基础上做了一些优化,研究这个程序,会让你对窥孔优化的认识变得具象起来。
19 | Python编译器(三):运行时机制
Python 对象设计的三个特点:
基于堆
Python 对象全部都是在堆里申请的,没有静态申请和在栈里申请的。这跟 C、C++ 和 Java 这样的静态类型的语言很不一样。
C 的结构体和 C++ 的对象都既可以在栈里,也可以在堆里;Java 也是一样,除了原生数据类型可以在栈里申请,未逃逸的 Java 对象的内存也可以在栈里管理,我们在讲Java 的 JIT 编译器的时候已经讲过了。基于引用计数的垃圾收集机制
每个 Python 对象会保存一个引用计数。也就是说,Python 的垃圾收集机制是基于引用计数的。
它的优点是可以实现增量收集,只要引用计数为零就回收,避免出现周期性的暂停;缺点是需要解决循环引用问题,并且要经常修改引用计数(比如在每次赋值和变量超出作用域的时候),开销有点大。唯一 ID
每个 Python 对象都有一个唯一 ID,它们在生存期内是不变的。用 id() 函数就可以获得对象的 ID。根据 Python 的文档,这个 ID 实际就是对象的内存地址。所以,实际上,你不需要在对象里用一个单独的字段来记录对象 ID。这同时也说明,Python 对象的地址在整个生命周期内是不会变的,这也符合基于引用计数的垃圾收集算法。对比一下,如果采用“停止和拷贝”的算法,对象在内存中会被移动,地址会发生变化。所以你能看出,ID 的算法与垃圾收集算法是环环相扣的。
课程小结
好了,我们来总结一下 Python 运行期的特征。你会发现,Python 的运行期设计的核心,就是 PyObject 对象,Python 对象所有的特性都是从 PyObject 的设计中延伸出来的,给人一种精巧的美感。
- Python 程序中的符号都是 Python 对象,栈机中存的也都是 Python 对象指针。
- 所有对象的头部信息是相同的,而后面的信息可扩展。这就让 Python 可以用 PyObject 指针来访问各种对象,这种设计技巧你需要掌握。
- 每个对象都有类型,类型描述信息在一个类型对象里。系统内有内置的类型对象,你也可以通过 C 语言或 Python 语言创建新的类型对象,从而支持新的类型。
- 类型对象里有一些字段保存了一些函数指针,用于完成数值计算、比较等功能。这是 Python 指定的接口协议,符合这些协议的程序可以被无缝集成到 Python 语言的框架中,比如支持加减乘除运算。
- 函数的运行、对象的创建,都源于 Python 的 Callable 协议,也就是在类型对象中制定 tp_call 函数。面向对象的特性,也是通过在类型对象里建立与基类的链接而实现的。
20 | JavaScript编译器(一):V8的解析和编译过程
V8 是谷歌公司在 2008 年推出的一款 JavaScript 编译器,它也可能是世界上使用最广泛的编译器。2008 年 V8 发布时,就已经比当时的竞争对手快 10 倍了;到目前,它的速度又已经提升了 10 倍以上。从中你可以看到,编译技术有多大的潜力可挖掘!
Node.js 就封装了一个 V8 引擎。
扩展:V8 这个词,原意是 8 缸的发动机,换算成排量,大约是 4.0 排量,属于相当强劲的发动机了。它的编译器,叫做 Ignition,是点火装置的意思。而它最新的 JIT 编译器,叫做 TurboFan,是涡轮风扇发动机的意思。
对 JavaScript 编译器来说,它最大的挑战就在于,当我们打开一个页面的时候,源代码的下载、解析(Parse)、编译(Compile)和执行,都要在很短的时间内完成,否则就会影响到用户的体验。
那么,V8 是如何做到既编译得快,又要运行得快的呢?
V8 是用 C++ 编写的。你可以重点关注这几个目录中的代码,它们是与编译有关的功能,而别的代码主要是运行时功能:
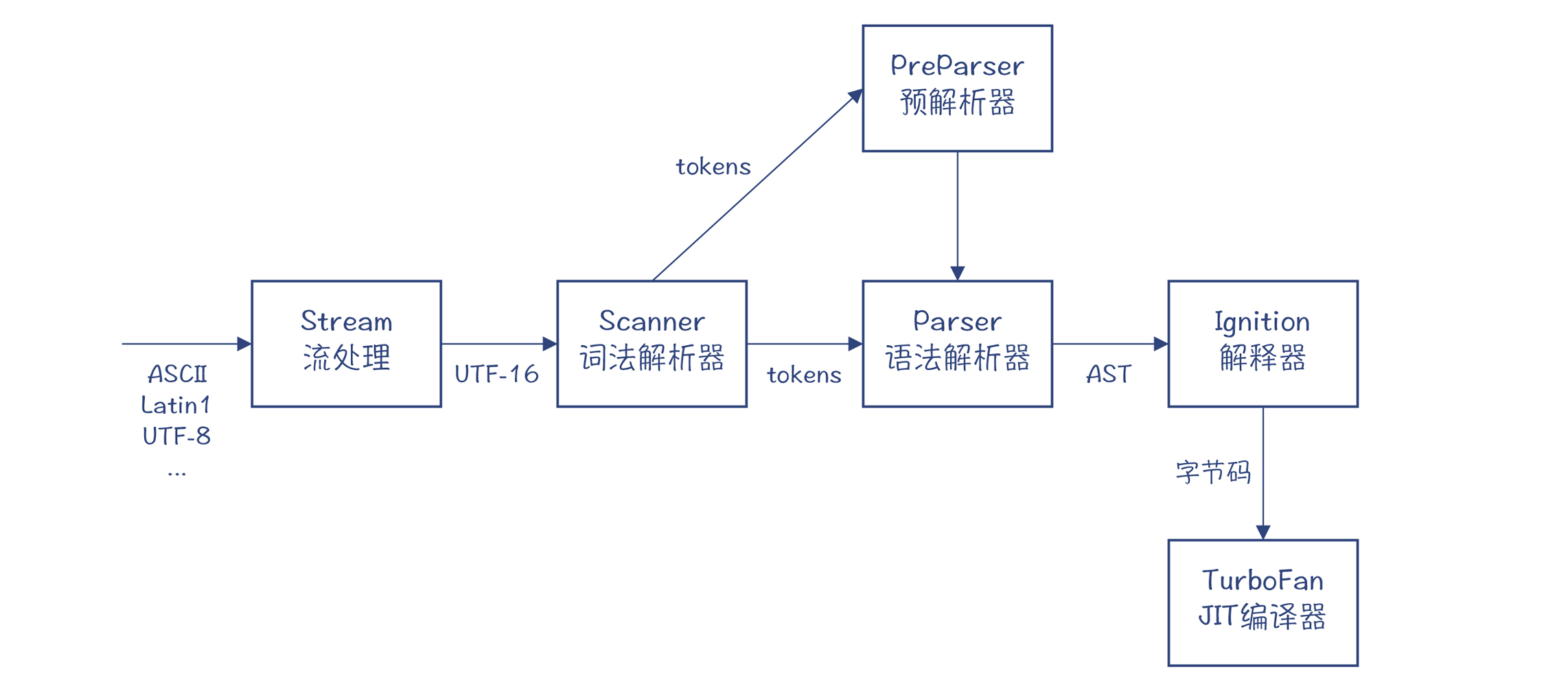
V8 的编译器的构成跟 Java 的编译器很像,它们都有从源代码编译到字节码的编译器,也都有解释器(叫 Ignition),也都有 JIT 编译器(叫 TurboFan)。你可以看下 V8 的编译过程的图例。在这个图中,你能注意到两个陌生的节点:流处理节点(Stream)和 预解析器(PreParser),这是 V8 编译过程中比较有特色的两个处理阶段。
超级快的解析过程(词法分析和语法分析)
首先,我们来了解一下 V8 解析源代码的过程。我在开头就已经说过,V8 解析源代码的速度必须要非常快才行。源代码边下载边解析完毕,在这个过程中,用户几乎感觉不到停顿。那它是如何实现的呢?
第一个原因,是 V8 的整个解析过程是流(Stream)化的,也就是一边从网络下载源代码,一边解析。在下载后,各种不同的编码还被统一转化为 UTF-16 编码单位,这样词法解析器就不需要处理多种编码了。
第二个原因,是识别标识符时所做的优化,这也让 V8 的解析速度更快了一点。你应该知道,标识符的第一个字符(ID_START)只允许用字母、下划线和 $ 来表示,而之后的字符(ID_CONTINUE)还可以包括数字。所以,当词法解析器遇到一个字符的时候,我们首先要判断它是否是合法的 ID_START。
那么,这样一个逻辑,通常你会怎么写?我一般想也不想,肯定是这样的写法:
if(ch >= 'A' && ch <= 'Z' || ch >='a' && ch<='z' || ch == '$' || ch == '_'){
return true;
}但你要注意这里的一个问题,if 语句中的判断条件需要做多少个运算?
最坏的情况下,要做 6 次比较运算和 3 次逻辑“或”运算。不过,V8 的作者们认为这太奢侈了。所以他们通过查表的方法,来识别每个 ASCII 字符是否是合法的标识符开头字符。
这相当于准备了一张大表,每个字符在里面对应一个位置,标明了该字符是否是合法的标识符开头字符。这是典型的牺牲空间来换效率的方法。虽然你在阅读代码的时候,会发现它调用了几层函数来实现这个功能,但这些函数其实是内联的,并且在编译优化以后,产生的指令要少很多,所以这个方法的性能更高。
第三个原因,是如何从标识符中挑出关键字。
与 Java 的编译器一样,JavaScript 的 Scanner,也是把标识符和关键字一起识别出来,然后再从中挑出关键字。所以,你可以认为这是一个最佳实践。那你应该也会想到,识别一个字符串是否是关键字的过程,使用的方法仍然是查表。查表用的技术是“完美哈希(perfect hashing)”,也就是每个关键字对应的哈希值都是不同的,不会发生碰撞。并且,计算哈希值只用了三个元素:前两个字符(ID_START、ID_CONTINUE),以及字符串的长度,不需要把每个字符都考虑进来,进一步降低了计算量。
除了词法分析,在语法分析方面,V8 也做了很多的优化来保证高性能。其中,最重要的是“懒解析”技术(lazy parsing)。
一个页面中包含的代码,并不会马上被程序用到。如果在一开头就把它们全部解析成 AST 并编译成字节码,就会产生很多开销:占用了太多 CPU 时间;过早地占用内存;编译后的代码缓存到硬盘上,导致磁盘 IO 的时间很长,等等。
所以,所有浏览器中的 JavaScript 编译器,都采用了懒解析技术。在 V8 里,首先由 预解析器,也就是 Preparser 粗略地解析一遍程序,在正式运行某个函数的时候,编译器才会按需解析这个函数。
V8 的 Parser 中,对于二元表达式的处理,采取的也是一种很常见的算法:操作符优先级解析器(Operator-precedence parser)。这跟 Java 的 Parser 也很像,它本质上是自底向上的一个 LR(1) 算法。所以我们可以得出结论,在手写语法解析器的时候,遇到二元表达式,采用操作符优先级的方法,算是最佳实践了!
编译成字节码
Ignition 是一个基于寄存器的解释器。它把函数的参数、变量等保存在寄存器里。不过,这里的寄存器并不是物理寄存器,而是指栈帧中的一个位置。
它在指令里会引用寄存器作为操作数,寄存器在进入函数时就被分配了存储位置,在函数运行时,栈帧的结构是不变的。而对比起来,栈机的指令从操作数栈里获取操作数,操作数栈随着函数的执行会动态伸缩。
Ignition 还引入了累加器这个物理寄存器作为缺省的操作数。这样既降低了指令的长度,又能够加快执行速度。
编译成机器码
V8 也有自己的 JIT 编译器,叫做 TurboFan。在学过 Java 的 JIT 编译器以后,你可以预期到,TurboFan 也会有一些跟 Java JIT 编译器类似的特性,比如它们都是把字节码编译生成机器码,都是针对热点代码才会启动即时编译的。
课程小结
今天这讲,我们从总体上考察了 V8 的编译过程,我希望你记住几个要点:
- 首先,是编译速度。由于 JavaScript 是在浏览器下载完页面后马上编译并执行,它对编译速度有更高的要求。因此,V8 使用了一边下载一边编译的技术:懒解析技术。并且,在解析阶段,V8 也比其他编译器更加关注处理速度,你可以从中学到通过查表减少计算量的技术。
- 其次,我们认识了一种新的解释器 Ignition,它是基于寄存器的解释器,或者叫寄存器机。Ignition 比起栈机来,更有性能优势。
- 最后,我们初步使用了一下 V8 的即时编译器 TurboFan。在下一讲中,我们会更细致地探讨 TurboFan 的特性。
21 | JavaScript编译器(二):V8的解释器和优化编译器
TurboFan 的优化编译技术
TurboFan 是一个优化编译器。不过它跟 Java 的优化编译器要完成的任务是不太相同的。因为 JavaScript 是动态类型的语言,所以如果它能够推断出准确的类型再来做优化,就会带来巨大的性能提升。
同时,TurboFan 也会像 Java 的 JIT 编译器那样,基于 IR 来运行各种优化算法,以及在后端做指令选择、寄存器分配等优化。所有的这些因素加起来,才使得 TurboFan 能达到很高的性能。
基于推理的优化(Speculative Optimazition)
对于基于推理的优化,我们其实并不陌生。在研究Java 的 JIT 编译器时,你就发现了 Graal 会针对解释器收集的一些信息,对于代码做一些推断,从而做一些激进的优化,比如说会跳过一些不必要的程序分支。
而 JavaScript 是动态类型的语言,所以对于 V8 来说,最重要的优化,就是能够在运行时正确地做出类型推断。举个例子来说,假设示例函数中的 add 函数,在解释器里多次执行的时候,接受的参数都是整型,那么 TurboFan 就处理整型加法运算的代码就行了。这也就是上一讲中我们生成的汇编代码。
function add(a,b){
return a+b;
}
for (i = 0; i<100000; i++){
if (i%1000==0)
console.log(i);
add(i, i+1);
}IR 和优化算法
在讲Java 的 JIT 编译器时我就提过,V8 做优化编译时采用的 IR,也是基于 Sea of Nodes 的。
你可以回忆一下 Sea of Nodes 的特点:合并了数据流图与控制流图;是 SSA 形式;没有把语句划分成基本块。
它的重要优点,就是优化算法可以自由调整语句的顺序,只要不破坏数据流图中的依赖关系。在 Sea of Nodes 中,没有变量(有时也叫做寄存器)的概念,只有一个个数据节点,所以对于死代码删除等优化方法来说,它也具备天然的优势。
课程小结
本讲,我围绕运行速度这个主题,给你讲解了 V8 在 TurboFan 和 Ignition 上所采用的优化技术。你需要记住以下几个要点:
- 第一,由于 JavaScript 是动态类型的语言,所以优化的要点,就是推断出函数参数的类型,并形成有针对性的优化代码。
- 第二,同 Graal 一样,V8 也使用了 Sea of Nodes 的 IR,而且对 V8 来说,内联和逃逸优化算法仍然非常重要。我在解析 Graal 编译器的时候已经给你介绍过了,所以这一讲并没有详细展开,你可以自己去回顾复习一下。
- 第三,V8 所采用的内联缓存技术,能够在运行期提高对象属性访问的性能。另外你要注意的是,在编写代码的时候,一定要避免对于相同的对象生成不同的隐藏类。
- 第四,Ignition 采用了 TurboFan 来编译内置函数,这种技术非常聪明,既省了工作量,又简化了系统的结构。实际上,在 Graal 编译器里也有类似的技术,它叫做 Snippet,也是用自身的中后端功能来编译内置函数。所以,你会再次发现,多个编译器之间所采用的编译技术,是可以互相印证的。
22 | Julia编译器(一):如何让动态语言性能很高?
Julia 语言却声称同时兼具了静态编译型和动态解释型语言的优点:一方面它的性能很高,可以跟 Java 和 C 语言媲美;而另一方面,它又是动态类型的,编写程序时不需要指定类型。
一般来说,我们很难能期望一门语言同时具有动态类型和静态类型语言的优点的,那么 Julia 又是如何实现这一切的呢?
原来它是充分利用了 LLVM 来实现即时编译的功能。因为 LLVM 是 Clang、Rust、Swift 等很多语言所采用的后端工具,所以我们可以借助 Julia 语言的编译器,来研究如何恰当地利用 LLVM。不过,Julia 使用 LLVM 的方法很有创造性,使得它可以同时具备这两类语言的优点。我将在这一讲中给你揭秘。
24 | Go语言编译器:把它当作教科书吧
我之所以要来带你研究 Go 语言的编译器,一方面是因为 Go 现在确实非常流行,很多云端服务都用 Go 开发,Docker 项目更是巩固了 Go 语言的地位;另一方面,我希望你能把它当成编译原理的教学参考书来使用。这是因为:
- Go 语言的编译器完全用 Go 语言本身来实现,它完全实现了从前端到后端的所有工作,而不像 Java 要分成多个编译器来实现不同的功能模块,不像 Python 缺少了后端,也不像 Julia 用了太多的语言。所以你研究它所采用的编译技术会更方便。
- Go 编译器里基本上使用的都是经典的算法:经典的递归下降算法、经典的 SSA 格式的 IR 和 CFG、经典的优化算法、经典的 Lower 和代码生成,因此你可以通过一个编译器就把这些算法都贯穿起来。
- 除了编译器,你还可以学习到一门语言的其他构成部分的实现思路,包括运行时(垃圾收集器、并发调度机制等)、标准库和工具链,甚至连链接器都是用 Go 语言自己实现的,从而对实现一门语言所需要做的工作有更完整的认识。
- 最后,Go 语言的实现继承了从 Unix 系统以来形成的一些良好的设计哲学,因为 Go 语言的核心设计者都是为 Unix 的发展,做出过重要贡献的极客。因此了解了 Go 语言编译器的实现机制,会提高你的软件设计品味。
25 | MySQL编译器(一):解析一条SQL语句的执行过程
26 | MySQL编译器(二):编译技术如何帮你提升数据库性能?
27 | 课前导读:学习现代语言设计的正确姿势
第三个模块,我会继续带你朝着提高编译原理实战能力的目标前进。这一次,我们从计算机语言设计的高度,来印证一下编译原理的核心知识点。
对于一门完整的语言来说,编译器只是其中的一部分。它通常还有两个重要的组成部分:一个是运行时,包括内存管理、并发机制、解释器等模块;还有一个是标准库,包含了一些标准的功能,如算术计算、字符串处理、文件读写,等等。
再进一步来看,我们在实现一门语言的时候,首先要做的,就是确定这门语言所要解决的问题是什么,也就是需求问题;其次,针对需要解决的问题,我们要选择合适的技术方案,而这些技术方案正是分别由编译器、运行时和标准库去实现的。
首先,我们来聊一聊实现一门计算机语言的关键因素:需求和设计。
那么总结起来,我们要想成功地实现一门语言,要把握两个要点:第一,要弄清楚该语言的需求,也就是它要去解决的问题;第二,要确定合适的技术方案,来更好地解决它要面对的问题。
“现代语言设计篇”都会讲哪些内容?
第一部分,是对各门语言的编译器的前端、中端和后端技术做一下对比和总结。
这样,通过梳理和总结,我们就可以找出各种编译器之间的异同点。对于其共同的部分,我们可以看作是一些最佳实践,你在自己的项目中可以大胆地采用;而有差异的部分,则往往是某种编译器为了实现该语言的设计目标而采用的技术策略,你可以去体会各门语言是如何做取舍的,这样也能变成你自己的经验储备。
第二部分,主要是对语言的运行时和标准库的实现技术做一个解析。
第一,是对语言的运行时和标准库的宏观探讨。我们一起来看看不同的语言的运行时和它的编译器之间是如何互相影响的。另外,我还会和你探讨语言的基础功能和标准库的实现策略,这是非常值得探讨的知识点,它让一门语言具备了真正的实用价值。
第二,是垃圾收集机制。本课程分析、涉及的几种语言,它们所采用的垃圾收集机制都各不相同。那么,为什么一门语言会选择这个机制,而另一种语言会选择另一种机制呢?带着这样的问题所做的分析,会让你把垃圾收集方面的原理落到实践中去。
第三,是并发模型。对并发的支持,对现代语言来说也越来越重要。在后面的课程中,我会带你了解线程、协程、Actor 三种并发模式,理解它们的优缺点,同时你也会了解到,如何在编译器和运行时中支持这些并发特性。
第三部分,是计算机语言设计上的 4 个高级话题。
第一,元编程技术。元编程技术是一种对语言做扩展的技术,相当于能够定制一门语言,从而更好地解决特定领域的问题。Java 语言的注解功能、Python 的对象体系的设计,都体现了元编程功能。而 Julia 语言,更是集成了 Lisp 语言在元编程方面的强大能力。因此我会带你了解一下这些元编程技术的具体实现机制和特点,便于你去采纳和做好取舍。
第二,泛型编程技术。泛型,或者说参数化类型,大大增强了现代语言的类型体系,使得很多计算逻辑的表达变得更简洁。最典型的应用就是容器类型,比如列表、树什么的,采用泛型技术实现的容器类型,能够方便地保存各种数据类型。像 Java、C++ 和 Julia 等语言都支持泛型机制,但它们各自实现的技术又有所不同。我会带你了解这些不同实现技术背后的原因,以及各自的特点。
第三,面向对象语言的实现机制。面向对象特性是当前很多主流语言都支持的特性。那么要在编译器和运行时上做哪些工作,来支持面向对象的特性呢?对象在内存里的表示都有哪些不同的方式?如何实现继承和多态的特性?为什么 Java 支持基础数据类型和对象类型,而有些语言中所有的数据都是对象?要在编译技术上做哪些工作来支持纯面向对象特性?这些问题,我会花一讲的时间来带你分析清楚,让你理解面向对象语言的底层机制。
第四,函数式编程语言的实现机制。函数式编程这个范式出现得很早,不少人可能不太了解或者不太关注它,但最近几年出现了复兴的趋势。像 Java 等面向对象语言,也开始加入对函数式编程机制的支持。在第三个模块中,我会带你分析函数式编程的关键特征,比如函数作为一等公民、不变性等,并会一起探讨函数式编程语言实现上的一些关键技术,比如函数类型的内部表示、针对函数式编程特有的优化算法等,让你真正理解函数式编程语言的底层机制。
28 | 前端总结:语言设计也有人机工程学
前端编译技术总结
通过前面课程中对 7 个编译器的解读分析,我们现在已经知道了,编译器的前端有一些共性的特征,包括:手写的词法分析器、自顶向下分析为主的语法分析器和差异化的语义分析功能。
手写的词法分析器
我们分析的这几个编译器,全部都采用了手写的词法分析器。主要原因有几个:
- 第一,手写的词法分析实现起来比较简单,再加上每种语言的词法规则实际上是大同小异的,所以实现起来也都差不多。
- 第二,手写词法分析器便于做一些优化。典型的优化是把关键字作为标识符的子集来识别,而不用为识别每个关键字创建自动机。V8 的词法分析器还在性能上做了调优,比如判断一个字符是否是合法的标识符字符,是采用了查表的方法,以空间换性能,提高了解析速度。
- 第三,手写词法分析器便于处理一些特殊的情况。在 MySQL 的词法分析器中,我们会发现,它需要根据当前字符集来确定某个字符串是否是合法的 Token。如果采用工具自动生成词法分析器,则不容易处理这种情况。
自顶向下分析为主的语法分析器
在前面解析的编译器当中,大部分都是手写的语法分析器,只有 Python 和 MySQL 这两个是用工具生成的。
从我们分析过的 7 种编译器里可以发现,自顶向下的算法体系占了绝对的主流,只有 MySQL 的语法分析器,采用的是自底向上的 LALR 算法。
差异化的语义分析功能
不同编译器的语义分析功能有其共性,那就是都要建立符号表、做引用消解。对于静态类型的语言来说,还一定要做类型检查。
支持友好的语言特性
自动类型推导
你在学习了语义分析中,基于属性计算做类型检查的机制以后,就会发现实现类型推导,其实是很容易的。只需要把等号右边的初始化部分的类型,赋值给左边的变量就行了。Null 安全性
那么,Null 安全性在编译器里应该怎样实现呢?
最简单的,你可以给所有的类型添加一个属性:Nullable。这样就能区分开 Int? 和 Int 类型,因为对于后者来说,Null 不是一个合法的取值。之后,你再运用正常的属性计算的方法,就可以实现 Null 安全性了。
一些友好的语法糖
分号推断
单例对象
纯数据的类
在 JDK 14 版本,就增加了一个实验特性,它可以支持 Record 类。比如,你要想定义一个 Person 对象,只需要这样一句话就行了:
public record Person(String firstName, String lastName, String gender, int age){}- 没有原始类型,一切都是对象
像 Java、Go、C++、JavaScript 等面向对象的语言,既要支持基础的数据类型,如整型、浮点型,又要支持对象类型,它们对这两类数据的使用方式是不一致的,因此也就增加了我们的编程负担。
而像 Scala、Kotlin 等语言,它们可以把任何数据类型都看作是对象。比如在 Kotlin 中,你可以直接调用一个整型或浮点型数字的方法
一些友好的词法规则
嵌套的多行注释
这样的话,你就可以把连续好几个函数或方法给一起注释掉。因为函数或方法的头部,一般都有多行的头注释。支持嵌套注释的话,我们就可以把这些头注释一起包含进去。标识符支持 Unicode
现代的大部分语言,都支持用 Unicode 来声明变量,甚至可以声明函数或类。这意味着什么呢?你可以用中文来声明变量和函数名称。而对于科学工作者来说,你也可以使用π、α、β、θ这些希腊字母,会更符合自己的专业习惯多行字符串字面量
对于字符串字面量来说,支持多行的书写方式,也会给我们的编程工作带来很多的便利。比如,假设你要把一个 JSON 字符串或者一个 XML 字符串赋给一个变量,用多行的书写方式会更加清晰
29 | 中端总结:不遗余力地进行代码优化
编译器的中端的主要作用,就是实现各种优化。并且在中端实现的优化,基本上都是机器无关的。而优化是在 IR 上进行的。
第一,是对 IR 的总结。我在第 6 讲中曾经讲过,IR 分为 HIR、MIR 和 LIR 三个层次,可以采用线性结构、图、树等多种数据结构。那么基于我们对实际编译器的研究,再一起来总结一下它们的 IR 的特点。
第二,是对优化算法的总结。在第 7 讲,我们把各种优化算法做了一个总体的梳理。现在就是时候,来总结一下编译器中的实际实现了。
对 IR 的总结
通过对前面几个真实编译器的分析,我们会发现 IR 方面的几个重要特征:SSA 已经成为主流;Sea of Nodes 展现出令人瞩目的优势;另外,一个编译器中的 IR,既要能表示抽象度比较高的操作,也要能表示抽象度比较低的、接近机器码的操作。
对优化算法的总结
SSA 成为主流
通过学习前面的课程,我们会发现,符合 SSA 格式的 IR 成为了主流。Java 和 JavaScript 的 Sea of Nodes,是符合 SSA 的;Golang 是符合 SSA 的;Julia 自己的 IR,虽然最早不是 SSA 格式的,但后来也改成了 SSA;而 Julia 所采用的 LLVM 工具,其 IR 也是 SSA 格式的。
SSA 意味着什么呢?源代码中的一个变量,会变成多个版本,每次赋值都形成一个新版本。在 SSA 中,它们都叫做一个值(Value),对变量的赋值就是对值的定义(def)。这个值定义出来之后,就可以在定义其他值的时候被使用(use),因此就形成了清晰的“使用 - 定义”链(use-def)。
这种清晰的 use-def 链会给优化算法提供很多的便利:
- 如果一个值定义了,但没有被使用,那就可以做死代码删除。
- 如果对某个值实现了常数折叠,那么顺着 def-use 链,我们就可以马上把该值替换成常数,从而实现常数传播。
- 如果两个值的定义是一样的,那么这两个值也一定是一样的,因此就可以去掉一个,从而实现公共子表达式消除;而如果不采取 SSA,实现 CSE(公共子表达式消除)需要做一个数据流分析,来确定表达式的变量值并没有发生变化。
Sea of Nodes 的特点总结
Sea of Nodes 的特点是把数据流图和控制流图合二为一,从而更容易实现全局优化。因为采用这种 IR,代码并没有一开始就被限制在一个个的基本块中。直到最后生成 LIR 的环节,才会把图节点 Schedule 到各个基本块。作为对比,采用基于 CFG 的 IR,优化算法需要让代码在基本块内部和基本块之间移动,处理起来会比较复杂。
采用 Sea of Nodes 作为 IR,在生成图的过程中,顺带就可以完成很多优化了,比如可以消除公共子表达式。
但是,Sea of Nodes 只有优点,没有缺点吗?也不是的。比如:
- 你在检查生成的 IR、阅读生成的代码的时候,都会更加困难。因为产生的节点非常多,会让你头晕眼花。所以,这些编译器都会特别开发一个图形化的工具,来帮助我们更容易看清楚 IR 图的脉络。
- 对图的访问,代价往往比较大。当然这也可以理解。因为你已经知道,对树的遍历是比较简单的,但对图的遍历算法就要复杂一些。
- 还有,当涉及效果流的时候,也就是存在内存读写等操作的时候,我们对控制流做修改会比较困难,因为内存访问的顺序不能被打乱,除非通过优化算法把固定节点转换成浮动节点。
总体来说,Sea of Nodes 的优点和缺点都来自图这种数据结构。一方面,图的结构简化了程序的表达;另一方面,要想对图做某些操作,也会更困难一些。
从高到低的多层次 IR
对于 IR 来说,我们需要总结的另一个特点,就是编译器需要从高到低的多个层次的 IR。在编译的过程中,高层次的 IR 会被不断地 Lower 到低层次的 IR,直到最后翻译成目标代码。通过这样层层 Lower 的过程,程序的语义就从高级语言,一步步变到了汇编语言,中间跨越了巨大的鸿沟:
- 高级语言中对一个数组元素的访问,到汇编语言会翻译成对内存地址的计算和内存访问;
- 高级语言中访问一个对象的成员变量,到汇编语言会以对象的起始地址为基础,计算成员变量相对于起始地址的偏移量,中间要计算对象头的内存开销;
- 高级语言中对于本地变量的访问,到汇编语言要转变成对寄存器或栈上内存的访问。
对优化算法的总结
编译器基于 IR,主要做了三种类型的处理。第一种处理,就是我们前面说的层层地做 Lower。第二种处理,就是对 IR 做分析,比如数据流分析。第三种处理,就是实现各种优化算法。编译器的优化往往是以分析为基础。比如,活跃性分析是死代码消除的基础。
前面我也说过,编译器在中端所做的优化,基本上都是机器无关的优化。那么在考察了 7 种编译器以后,我们来总结一下这些编译器做优化的特点。
第一,有些基本的优化,是每个编译器都会去实现的。
第二,对于解释执行的语言,其编译器能做的优化是有限的。
第三,对于动态类型的语言,优化编译的首要任务是做类型推断。
第四,JIT 编译器可以充分利用推理性的优化机制,这样既节省了编译时间,又有可能带来比 AOT 更好的优化效果。
第五,对于面向对象的语言,内联优化和逃逸分析非常重要。
第六,对于静态类型的语言,不同的编译器的优化程度也是不同的。
30 | 后端总结:充分发挥硬件的能力

31 | 运行时(一):从0到语言级的虚拟化
到底什么是运行时?任何语言都有运行时吗?运行时和编译器是什么关系?
什么是标准库?标准库和运行时库又是什么关系?库一般都包含什么功能?
什么是运行时(Runtime)?
我们在第 5 讲说过,每种语言都有一个特定的执行模型(Execution Model)。而这个执行模型就需要运行时系统(Runtime System)的支持。我们把这种可以支撑程序运行的运行时系统,简称为运行时。
那运行时都包含什么功能呢?通常,我们最关心的是三方面的功能:程序运行机制、内存管理机制、并发机制。
Java 的运行时
我们先看看 Java 语言的运行时系统,也就是 JVM。
第一,JVM 规定了一套程序的运行机制。JVM 支持基于字节码的解释执行机制,还包括了即时编译成机器码并执行的机制。Java 程序之间的互相调用,需要遵循一定的调用约定或二进制标准,包括如何传参数等等。这也是运行机制的一部分。
第二,JVM 对内存做了统一的管理。它把内存划分为程序计数器、虚拟机栈、堆、方法区、运行时常量池和本地方法栈等不同的区域。
第三,JVM 封装了操作系统的线程模型,为应用程序提供了并发处理的机制。
以上就是 JVM 为运行在其上的任何程序提供的支撑了。在提供这些支撑的同时,运行时系统也给程序运行带来了一些限制。
第一,JVM 实际上提供了一个基础的对象模型,JVM 上的各种语言必须遵守。所以,虽然 Clojure 是一个函数式编程语言,但它在底层却不得不使用 JVM 规定的对象模型。
第二,基于 JVM 的语言程序要去调用 C 语言等生成的机器码的库,会比较难。不过,对于同样基于 JVM 的语言,则很容易实现相互之间的调用,因为它们底层都是类和字节码。
第三,在内存管理上,程序不能直接访问内存地址,也不能手动释放内存。
第四,在并发方面,JVM 只提供了线程机制。
Python 的运行时
第一,Python 也提供了一套字节码,以及运行该字节码的解释器。这套字节码,也是跟 Python 的类型体系互相配合的。字节码中操作的那些标识符,都是 Python 的对象引用。
第二,在内存管理方面,Python 也提供了自己的机制,包括对栈和堆的管理。
第三,是并发机制。Python 把操作系统的线程进行了封装,让 Python 程序能支持基于线程的并发。同时,它也实现了协程机制
C、C++、Go 的运行时
C 语言最主要的运行时,实际上就是操作系统。C 语言和现代的各种操作系统可以说是伴生关系,就像 Java 和 JVM 是伴生关系一样。所以,如果我们要深入使用 C 语言,某种意义上就是要深入了解操作系统的运行机制。
在程序执行机制方面,C 语言编译完毕的程序是完全按照操作系统的运行机制来执行的。
在内存管理方面,C 语言使用了操作系统提供的线程栈,操作系统能够自动帮助程序管理内存。程序也可以从堆里申请内存,但必须自己负责释放,没有自动内存管理机制。
在并发机制方面,当然也是直接用操作系统提供的线程机制。因为操作系统没有提供协程和 Actor 机制,所以 C 语言也没有提供这种并发机制。
不过有一个程序 crt0.o,有时被称作是C 语言的运行时。它是一段汇编代码(crt0.s),由链接器自动插入到程序里面,主要功能是在调用 main 函数之前做一些初始化工作,比如设置 main 函数的参数(argc 和 argv)、环境变量的地址、调用 main 函数、设置一些中断向量用于处理程序异常等。所以,这个所谓的运行时所做的工作也特别简单。
不同系统的 crt0.s 会不太一样,因为 CPU 架构和 ABI 是不同的。下面是一个 crt0.s 的示例代码:
.text
.globl _start
_start: # _start是链接器需要用到的入口
xor %ebp, %ebp # 让ebp置为0,标记栈帧的底部
mov (%rsp), %edi # 从栈里获得argc的值
lea 8(%rsp), %rsi # 从栈里获得argv的地址
lea 16(%rsp,%rdi,8), %rdx # 从栈里获得envp的地址
xor %eax, %eax # 按照ABI的要求把eax置为0,并与icc兼容
call main # 调用main函数,%edi, %rsi, %rdx是传给main函数的三个参数
mov %eax, %edi # 把main函数的返回值提供给_exit作为第一个参数
xor %eax, %eax # 按照ABI的要求把eax置为0,并与icc兼容
call _exit # 终止程序可以说,C 语言的运行时是一个极端,提供了最少的功能。反过来呢,这也就是给了程序员最大的自由度
不过,Go 语言虽然也是编译成二进制的可执行文件,但它的运行时要复杂得多。比如,它有垃圾收集器;再比如,Go 语言最显著的特点是提供了自己的并发机制,也就是 goroutine。对 goroutine 的运行管理,也是 go 的运行时的一部分。
无独有偶,在 Android 平台上,你可以把 Java 程序以 AOT 的方式编译成可执行文件。但这个可执行文件其实仍然包含了一个运行时,比如垃圾收集功能,所以与 C 语言编译形成的可执行文件,也是不一样的。
总结起来,运行时系统提供了程序的运行机制、内存管理机制、并行机制等功能。运行时和编译器的关系就是,编译器要跟这些运行时做配合,生成符合运行时要求的目标代码。
库和标准库
根据库的使用场景和与编译器的关系,这些库可以分为标准库、运行时库和内置函数三类。
第一,标准库,供用户的程序调用。我们在写一段 C 语言程序的时候,总要在源代码一开头的部分 include 几个库进来,比如 stdio.h、stdlib.h 等等。C++ 的 STL 库和标准库让程序员拥有比 C 语言里面更多的工具,比如各种标准的容器类。Java 刚面世的时候,就在 JDK 里打包了很多标准库。正是因为这些丰富又好用的库,使得 Java 能够被迅速接受。当然了,这些库也成了 JDK 标准的组成部分。而 Python 语言声称是“自带电池”的,也就是说有很多库的支持,可以迅速上手做很多事情。
第二类,运行时库,它们不是由用户直接调用的,而是运行时的组成部分。比如,Python 实现整数运算的功能很强大,支持任意长度整数的加减乘除。这些功能是由一些库函数实现的,并由 Python 的解释器来调用,实现 Python 程序中的加减乘除操作。
第三类,是一些叫做 Built-in 或者 Intrincics 的内置函数,它们是用来辅助生成机器码的。它们往往由汇编代码实现,也有的是用编译器的 LIR 实现的,在编译的时候直接内联进去。这些函数有时开发者也可以调用,比如在 C 语言中,可以像调用普通函数一样,调用 CPU 厂家提供的与 SIMD 指令有关的 Intrincics。但这些函数会直接生成汇编码,不像 C 语言编写的程序那样需要经过优化和代码生成的过程。
标准库的特殊性
第一,有的库可以用本语言来实现,而有的库必须要用其他语言来实现,因为用本语言实现有困难。这就要求库的编写者要具备更高的技能,能够掌握更加底层的语言。
比如,Java 有少量库(比如网络通讯模块)就需要用 C 语言来编写,而 Python、PHP、Node.js 等语言的大量库都是用 C 语言编写的。甚至,标准库中的某些底层功能会采用汇编语言来写。
第二,标准库的接口不可以经常变化,甚至是要保持一直不变。因此,标准库的设计一定要慎重,这就要求设计者有更高的规划和设计能力。因为几乎每个程序都会用到标准库的功能,库的接口如果变化的话,就会影响到所有已经写好的程序。
第三,标准库往往集中体现了一门语言的核心特点。同样的功能,面向对象编程语言、函数式编程语言、基于 Actor 的语言,会采用各自的方式来实现。库的编写者要写出教科书级的代码,充分发挥这门语言的优势。这样的话,编程人员使用这些标准库的过程,实际上就是潜移默化地学习这门语言的编程思想的过程。