 忧郁的大能猫
忧郁的大能猫
好奇的探索者,理性的思考者,踏实的行动者。
blog/A-IT/10-编程语言/c.c++/c++笔记/5.多态与虚函数
Table of Contents:
多态和虚函数快速入门教程
基类指针可以按照基类的方式来做事,也可以按照派生类的方式来做事,它有多种形态,或者说有多种表现方式,我们将这种现象称为多态(Polymorphism)
默认情况通过基类指针只能访问派生类的成员变量,但是不能访问派生类的成员函数。
为了消除这种尴尬,让基类指针能够访问派生类的成员函数,C++ 增加了虚函数(Virtual Function)
C++中虚函数的唯一用处就是构成多态
C++提供多态的目的是:可以通过基类指针对所有派生类(包括直接派生和间接派生)的成员变量和成员函数进行“全方位”的访问,尤其是成员函数。如果没有多态,我们只能访问成员变量。
例子:
People *p = new People("王志刚", 23);
p -> display();
p = new Teacher("赵宏佳", 45, 8200);
p -> display();实现的三个条件:
1.有继承、2.有virtual重写、3.有父类指针(或引用)指向子类对象。
virtual关键字告诉编译器这个函数要支持多态;不要根据指针类型判断如何调用;而是要根据运行时指针所指向的实际对象类型来判断如何调用
实现的基础:1.动态绑定 2.函数指针
借助引用也可以实现多态
不过引用不像指针灵活,指针可以随时改变指向,而引用只能指代固定的对象,在多态性方面缺乏表现力
多态的用途,目的
- 只需要一个指针变量 p 就可以调用所有派生类的虚函数,典型的例子是游戏循环中基类调用所有派生类的update方法
- 动态绑定能通过使旧的代码调用新的代码来提高重用,旧调新,向后扩展的作用,写框架一般都会用到
- 框架代码一般会用多态,让调用代码去继承某个类,让后框架代码调用用户的代码。
缺点
通过虚函数表指针VPTR调用重写函数是在程序运行时进行的,因此需要通过寻址操作才能确定真正应该调用的函数。而普通成员函数是在编译时就确定了调用的函数。在效率上,虚函数的效率要低很多。出于效率考虑,没有必要将所有成员函数都声明为虚函数
虚函数注意事项以及构成多态的条件
什么时候声明虚函数
1. 首先看成员函数所在的类是否会作为基类。
2. 然后看成员函数在类的继承后有无可能被更改功能,
3. 如果希望更改其功能的,一般应该将它声明为虚函数。
4. 如果成员函数在类被继承后功能不需修改,或派生类用不到该函数,则不要把它声明为虚函数。
虚析构函数的必要性
将基类的析构函数声明为虚函数后,派生类的析构函数也会自动成为虚函数。
如果一个类是最终的类,那就没必要再声明为虚函数了
构造函数为什么不能是虚函数?
C++ 中的构造函数用于在创建对象时进行初始化工作,在执行构造函数之前对象尚未创建完成,虚函数表尚不存在,也没有指向虚函数表的指针,所以此时无法查询虚函数表,也就不知道要调用哪一个构造函数。析构造函数为什么要是虚函数?
因为如果不是虚析构函数,那么会调用基类的析构函数,而不会调用派生类的析构函数,从而就会有内存泄漏的情况。为什么delete的时,会同时调用派生类和基类的析构函数呢?
虚析构函数会根据指针指向的类型调用派生类的析构函数,而在执行派生类的析构函数的过程中,又会调用基类的析构函数。派生类析构函数始终会调用基类的析构函数,并且这个过程是隐式完成的。
在派生类的析构函数中不用显式地调用基类的析构函数,因为每个类只有一个析构函数,编译器知道如何选择,无需程序员干涉。
纯虚函数和抽象类详解
virtual 返回值类型 函数名 (函数参数) = 0;包含大于等于一个纯虚函数的类称为抽象类(Abstract Class)。之所以说它抽象,是因为它无法实例化,也就是无法创建对象。原因很明显,纯虚函数没有函数体,不是完整的函数,无法调用。
抽象类通常是作为基类,让派生类去实现纯虚函数。派生类必须实现纯虚函数才能被实例化。
1)有一个纯虚函数就可以使类成为抽象基类,但是抽象基类中除了包含纯虚函数外,还可以包含其它的成员函数(虚函数或普通函数)和成员变量
2) 只有类中的虚函数才能被声明为纯虚函数,普通成员函数和顶层函数均不能声明为纯虚函数
虚函数表精讲教程,直戳多态的实现机制
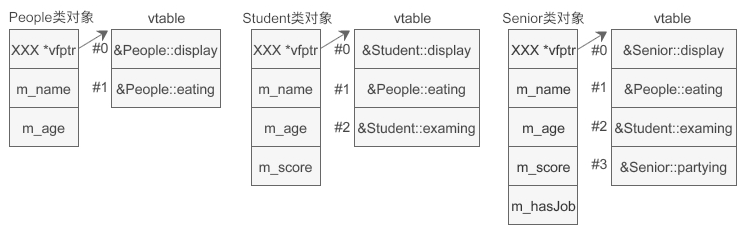
- 如果一个类包含了虚函数,那么在创建该类的对象时就会额外地增加一个数组,数组中的每一个元素都是虚函数的入口地址。不过数组和对象是分开存储的,为了将对象和数组关联起来,编译器还要在对象中安插一个指针,指向数组的起始位置。这里的数组就是虚函数表(Virtual function table),简写为
vtable - 在对象的开头位置有一个指针
vfptr,指向虚函数表,并且这个指针始终位于对象的开头位置。 - 仔细观察虚函数表,可以发现基类的虚函数在 vtable 中的索引(下标)是固定的,不会随着继承层次的增加而改变,派生类新增的虚函数放在 vtable 的最后。如果派生类有同名的虚函数遮蔽(覆盖)了基类的虚函数,那么将使用派生类的虚函数替换基类的虚函数(这就是多态的原因)。
typeid运算符:获取类型信息
typeid 运算符用来获取一个表达式的类型信息。类型信息对于编程语言非常重要,它描述了数据的各种属性:
* 对于基本类型(int、float 等C++内置类型)的数据,类型信息所包含的内容比较简单,主要是指数据的类型。
* 对于类类型的数据(也就是对象),类型信息是指对象所属的类、所包含的成员、所在的继承关系等。
类型信息是创建数据的模板,数据占用多大内存、能进行什么样的操作、该如何操作等,这些都由它的类型信息决定。
可以发现,不像 Java、C# 等动态性较强的语言,C++ 能获取到的类型信息非常有限,也没有统一的标准,各个编译器可能会有不同的实现细节。
通常情况下,type_info 类型提供以下信息:
1. name 函数: 返回一个指向包含类型名称的 C 字符串的指针。这个名称可能是编译器特定的,通常会包含类型的限定名。
2. 比较操作: type_info 对象可以用于比较两个类型是否相同。
typeid 返回 type_info 对象的引用,而表达式typeid(a) == typeid(b)的结果为 true,
一个类型不管使用了多少次,编译器都只为它创建一个对象,所有 typeid 都返回这个对象的引用。
何时创建type_info对象?
1. 为了减小编译后文件的体积,编译器不会为所有的类型创建 type_info 对象,只会为使用了 typeid 运算符的类型创建。
2. 不过有一种特殊情况,就是带虚函数的类(包括继承来的),不管有没有使用 typeid 运算符,编译器都会为带虚函数的类创建 type_info 对象
C++ 标准规定,type_info 类至少要有如下所示的 4 个 public 属性的成员函数,其他的扩展函数编译器开发者可以自由发挥,不做限制。
1) 原型:const char* name() const;
2) 原型:bool before (const type_info& rhs) const;
3) 原型:bool operator== (const type_info& rhs) const;
4) 原型:bool operator!= (const type_info& rhs) const;
RTTI机制(运行时类型识别机制)
RTTI(Run-Time Type Identification,RTTI)
一般情况下,在编译期间就能确定一个表达式的类型,但是当存在多态时,有些表达式的类型在编译期间就无法确定了,必须等到程序运行后根据实际的环境来确定。实现原理就是在虚函数表中添加了一个指向type_info的指针。相同类型的对象会指向同一个type_info对象。
比如:一个基类对象有两个赋值的分支
在编译期间确定的情况下,有一个对象的方法调用是直接就load相应的代码段了,如果是虚函数的话,需要在运行是确定其类型,然后通过虚函数指针找到虚函数表然后再找到对应的方法。
带有虚函数的对象模型:

编译器会在虚函数表 vftable 的开头插入一个指针,指向当前类对应的 type_info 对象。当程序在运行阶段获取类型信息时(调用typeid),可以通过对象指针 p 找到虚函数表指针 vfptr,再通过 vfptr 找到 type_info 对象的指针,进而取得类型信息。下面的代码演示了这种转换过程:**(p->vfptr - 1)
例子:
//基类
class People{
public:
virtual void func(){ }
};
//派生类
class Student: public People{ };
int main(){
People *p;
int n;
cin>>n;
if(n <= 100){
p = new People();
}else{
p = new Student();
}
//根据不同的类型进行不同的操作
if(typeid(*p) == typeid(People)){
cout<<"I am human."<<endl;
}else{
cout<<"I am a student."<<endl;
}
return 0;
}C++静态绑定和动态绑定,彻底理解多态(绑定的是地址)
C/C++ 用变量来存储数据,用函数来定义一段可以重复使用的代码,它们最终都要放到内存中才能供 CPU 使用。CPU 通过地址来取得内存中的代码和数据,程序在执行过程中会告知 CPU 要执行的代码以及要读写的数据的地址。
CPU 访问内存时需要的是地址,而不是变量名和函数名!变量名和函数名只是地址的一种助记符,当源文件被编译和链接成可执行程序后,它们都会被替换成地址。编译和链接过程的一项重要任务就是找到这些名称所对应的地址。
我们不妨将变量名和函数名统称为符号(Symbol),找到符号对应的地址的过程叫做符号绑定。
函数绑定
找到函数名对应的地址,然后将函数调用处用该地址替换,这称为函数绑定。
* 静态绑定(Static binding):一般情况下,在编译期间(包括链接期间)就能找到函数名对应的地址,完成函数的绑定,程序运行后直接使用这个地址即可。
* 动态绑定(dynamic binding):但是有时候在编译期间想尽所有办法都不能确定使用哪个函数,必须要等到程序运行后根据具体的环境或者用户操作才能决定。
C++ 是一门静态性的语言,会尽力在编译期间找到函数的地址,以提高程序的运行效率,但是有时候实在没办法,只能等到程序运行后再执行一段代码(很少的代码)才能找到函数的地址。
上节我们讲到,通过p -> display();语句调用 display() 函数时会转换为下面的表达式:
( *( *(p+0) + 0 ) )(p);
这里的 p 有可能指向 People 类的对象,也可能指向 Student 或 Senior 类的对象,编译器不能提前假设 p 指向哪个对象,也就不能确定调用哪个函数,所以编译器干脆不管了,p 爱指向哪个对象就指向哪个对象,等到程序运行后执行一下这个表达式自然就知道了。
这就是动态绑定的本质:编译器在编译期间不能确定指针指向哪个对象,只能等到程序运行后根据具体的情况再决定(虚函数表来决定调用那一个)
RTTI机制下的对象内存模型
在 C++ 中,除了 typeid 运算符,dynamic_cast 运算符和异常处理也依赖于 RTTI 机制,并且要能够通过派生类获取基类的信息,或者说要能够判断一个类是否是另一个类的基类,这样上节讲到的内存模型就不够用了,我们必须要在基类和派生类之间再增加一条绳索,把它们连接起来,形成一条通路,我们称此为继承链(Inheritance Chain)。
将基类和派生类连接起来很容易,只需要在基类对象中增加一个指向派生类对象的指针,然而考虑到多继承、降低内存使用等诸多方面的因素,真正的对象内存模型比上节讲到的要复杂很多,并且不同的编译器有不同的实现(C++ 标准并没有对对象内存模型的细节做出规定)。
typeid 经过固定次数的间接转换返回 type_info 对象,间接次数不会随着继承层次的增加而增加,对效率的影响很小,读者可以放心使用。而 dynamic_cast 运算符和异常处理不仅要经过数次间接转换,还要遍历继承链,如果继承层次较深,那么它们的性能堪忧,读者应当谨慎使用!
静态语言(Static Language)
编译期间确定类型的。在 C/C++ 中,变量、函数参数、函数返回值等在定义时都必须显式地指明类型,并且一旦指明类型后就不能再更改了,所以大部分表达式的类型都能够精确的推测出来,编译器在编译期间就能够搞定这些事情,这样的编程语言称为静态语言。除了 C/C++,典型的静态语言还有 Java、C#、Haskell、Scala 等。
静态语言在定义变量时通常需要显式地指明类型,并且在编译期间会拼尽全力来确定表达式的类型信息,只有在万不得已时才让程序等到运行后动态地获取类型信息(例如多态),这样做可以提高程序运行效率,降低内存消耗。动态语言(Dynamic Language)
运行期间确定类型的。动态语言在定义变量时往往不需要指明类型,并且变量的类型可以随时改变(赋给它不同类型的数据),编译器在编译期间也不容易确定表达式的类型信息,只能等到程序运行后**再动态地获取类型信息。典型的动态语言有 JavaScript、Python、PHP、Perl、Ruby 等。