 忧郁的大能猫
忧郁的大能猫
好奇的探索者,理性的思考者,踏实的行动者。
blog/A-IT/10-编程语言/c.c++/c++笔记/加快C++代码的编译速度方法
Table of Contents:
# 加快C++代码的编译速度方法
为什么C++它就编译的这么慢呢?
最重要的一个原因应该是C++基本的"头文件-源文件"的编译模型:
1. 每个源文件作为一个编译单元,可能会包含上百甚至上千个头文件,而在每一个编译单元,这些头文件都会被从硬盘读进来一遍,然后被解析一遍。对于Boost头文件这类动辄几千上万行的头文件来说,就会非常很慢。而且不同的编译单元会包含相同的头文件,而这些头文件就会被重复的编译多次。
2. 模板函数实例化,对于源代码中出现的每一处模板实例化,编译器都需要去做实例化的工作;而在链接时,链接器还需要移除重复的实例化代码。显然编译器遇到一个模板定义时,每次都去进行重复的实例化工作,进行重复的编译工作。
3. 每个编译单元都会产生一个obj文件,然后所以这些obj文件会被link到一起,并且这个过程很难并行。
优化方法
一、 硬件角度
1、使用高性能多核cpu进行并行编译
买个4核的,或者8核的cpu,gcc -j8,每次一build,就是8个文件并行着编。 要是你们老板不同意,让他读读这篇文章:Hardware is Cheap, Programmers are Expensive
2、更好的硬盘
编译速度慢很大一部分原因是磁盘操作,所以赶紧换ssd固态硬盘,千万别觉着没什么就一直拖着不换,换了之后你就再也回不去过去的状态了。
3、增加内存
内存一般不太会成为编译的瓶颈。但是多了肯定没啥坏处。但普通的公司的配置一般都不太够用。
4.使用linux下的tmpfs
有人说在Windows下用了RAMDisk把一个项目编译时间从4.5小时减少到了5分钟,也许这个数字是有点夸张了,不过粗想想,把文件放到内存上做编译应该是比在磁盘上快多了吧,尤其如果编译器需要生成很多临时文件的话。
这个做法的实现成本最低,在Linux中,直接mount一个tmpfs就可以了。而且对所编译的工程没有任何要求,也不用改动编译环境。
对于普通的c++工程,编译和链接的时候大概能比ssd硬盘提升个30%-50%。主要还是看编译工程是否是IO密集型的。
5、使用多台机器进行分布式编译
一台机子的性能始终是有限的,利用网络中空闲的cpu资源,以及专门用来编译的build server来帮助你编译才能从根本上解决我们编译速度的问题。
分布式编译工具如下:
* Incredibuild。
* distcc
分布式并行编译的例子:
这是一个比较极端的情况,如果你用了Incredibuild,对最终的编译速度还是不满意,怎么办?其实只要跳出思维的框架,编译速度还是可以有质的飞跃的 - 前提是你有足够多的机器:
假设你有solution A和solution B,B依赖于A,所以必须在A之后Build B。其中A,B Build各需要1个小时,那么总共要2个小时。可是B一定要在A之后build吗?跳出这个思维框架,你就有了下述方案:同时开始build A和B 。
A的build成功,这里虽然B的build失败了,但都只是失败在最后的link上。
重新link B中的project。这样,通过让A的build与B的编译并行,最后link一下B中的project,整个编译速度应该能够控制在1个小时15分钟之内。
distcc
一台机器的能力有限,可以联合多台电脑一起来编译。这在公司的日常开发中也是可行的,因为可能每个开发人员都有自己的开发编译环境,它们的编译器版本一般是一致的,公司的网络也通常具有较好的性能。这时就是distcc大显身手的时候了。
使用distcc,并不像想象中那样要求每台电脑都具有完全一致的环境,它只要求源代码可以用make -j并行编译,并且参与分布式编译的电脑系统中具有相同的编译器。因为它的原理只是把预处理好的源文件分发到多台计算机上,预处理、编译后的目标文件的链接和其它除编译以外的工作仍然是在发起编译的主控电脑上完成,所以只要求发起编译的那台机器具备一套完整的编译环境就可以了。
distcc安装后,可以启动一下它的服务:
/usr/bin/distccd --daemon --allow 10.64.0.0/16默认的3632端口允许来自同一个网络的distcc连接。
然后设置一下DISTCC_HOSTS环境变量,设置可以参与编译的机器列表。通常localhost也参与编译,但如果可以参与编译的机器很多,则可以把localhost从这个列表中去掉,这样本机就完全只是进行预处理、分发和链接了,编译都在别的机器上完成。因为机器很多时,localhost的处理负担很重,所以它就不再“兼职”编译了。
export DISTCC_HOSTS="localhost 10.64.25.1 10.64.25.2 10.64.25.3"然后与ccache类似把g++,gcc等常用的命令链接到/usr/bin/distcc上就可以了。
在make的时候,也必须用-j参数,一般是参数可以用所有参用编译的计算机CPU内核总数的两倍做为并行的任务数。
在编译过程中可以用distccmon-text来查看编译任务的分配情况。distcc也可以与ccache同时使用,通过设置一个环境变量就可以做到,非常方便。
二、工具角度
1. ccache
CCache是一个编译缓存工具,其原理是将cpp的编译结果保存在文件缓存中(以空间换时间的思路),以后编译时若对应文件无变动可直接从缓存中获取编译结果。需要注意的是,Make本身也有一定缓存功能,当目标文件已编译(且依赖无变化)时,若源文件时间戳无变化也不会再次编译;但CCache是按文件内容做的缓存,且同一机器的多个项目可以共享缓存,因此适用面更大。
安装
yum install ccache
查看ccache的信息
ccache -s
cache directory /root/.ccache
primary config /root/.ccache/ccache.conf
secondary config (readonly) /etc/ccache.conf
stats updated Tue Jun 22 16:45:59 2021
cache hit (direct) 322
cache hit (preprocessed) 48
cache miss 294
cache hit rate 55.72 % # 快不快就看这里了
called for link 25
cleanups performed 16
files in cache 293
cache size 1.6 GB
max cache size 5.0 GB设置ccache的大小
ccache -M 50G
使用
使用"ccache gcc"或"ccache g++"代替"gcc"或"g++" 你也可以配置makepkg使用ccache,只需在你的/etc/makepkg.conf中加入下面几行:
export CC="ccache gcc"
export CPP="ccache cpp"
export CXX="ccache g++"效果
第一次全部编译会稍慢点,第二次编译会提高近一倍,第三次编译还会进一步提高。主要看缓存的命中率。
2. 使用其他更快链接器而非默认的
gcc将源码编译为.o,然后linker将.o连接为.so或者可执行程序,linker可以使用ld.bfd、ld.gold或者lld。
gold was about 3x to 4x faster for all values I've tried when using -Wl,--threads -Wl,--thread-count=$(nproc) to enable multithreading
LLD was about 2x faster than gold!
-Wl选项告诉编译器将后面的参数传递给链接器。
查看ld链接器是否支持多线程
$ /usr/bin/ld.bfd --threads
/usr/bin/ld.bfd: unrecognized option '--threads'
$ /usr/bin/ld.gold --threads
/usr/bin/ld.gold: warning: ignoring --threads: /usr/bin/ld.gold was
compiled without thread support如何让链接器支持多线程
在源码编译的时候加上--enable-threads 即可
三、代码角度
删除冗余的头文件
一些代码经过上十年的开发与维护,经手的人无数,很有可能出现包含了没用的头文件,或重复包含的现象,去掉这些冗余的include是相当必要的。当然,这主要是针对cpp文件的,因为对于一个头文件,其中的某个include是否冗余很难界定,得看是否在最终的编译单元中用到了,而这样又可能出现在一个编译单元用到了,而在另外一个编译单元中没用到的情况。
在头文件中使用前置声明,而不是直接包含头文件。
不要以为你只是多加了一个头文件,由于头文件的"被包含"特性,这种效果可能会被无限放大。所以,要尽一切可能使头文件精简。
很多时候前置申明某个namespace中的类会比较痛苦,而直接include会方便很多,千万要抵制住这种诱惑;
类的成员,函数参数等也尽量用引用或指针,为前置声明创造条件。
使用Pimpl模式
Pimpl全称为Private Implementation。传统的C++的类的接口与实现是混淆在一起的,而Pimpl这种做法使得类的接口与实现得以完全分离。如此,只要类的公共接口保持不变,对类实现的修改始终只需编译该cpp;同时,该类提供给外界的头文件也会精简许多。
高度模块化
模块化就是低耦合,就是尽可能的减少相互依赖。
这里其实有两个层面的意思:
一是文件与文件之间,一个头文件的变化,尽量不要引起其他文件的重新编译;
二是工程与工程之间,对一个工程的修改,尽量不要引起太多其他工程的编译。
这就要求头文件,或者工程的内容一定要单一,不要什么东西都往里面塞,从而引起不必要的依赖。这也可以说是内聚性吧。
以头文件为例,不要把两个不相关的类,或者没什么联系的宏定义放到一个头文件里。内容要尽量单一,从而不会使包含他们的文件包含了不需要的内容。可以写个工具,把代码中最"hot"的那些头文件找出来,然后分成多个独立的小文件分别进行包含。
特别注意inline和template
这是C++中两种比较"先进"的机制,但是它们却又强制我们在头文件中包含实现,这对增加头文件的内容,从而减慢编译速度有着很大的贡献。使用之前,权衡一下。
替换Boost库
Boost是一个广泛使用的基础库,涵盖了大量常用函数,十分方便、好用,然而也存在一些不足之处。一个显著缺点是其实现采用了hpp的形式,即声明和实现均放在头文件中,这会造成预编译展开后十分巨大。
对一些功能来说,动不动就会引几百个头文件。
// 字符串操作是常用功能,仅仅引入该头文件展开大小就超过4M
#include <boost/algorithm/string.hpp>
// 与此相对的,引入多个STL的头文件,展开后仅仅只有1M
#include <vector>
#include <map>
// ...在我们项目中主要使用的Boost函数不超过二十个,部分可以在STL中找到替代,部分我们手动做了实现,使得项目从重度依赖Boost转变成绝大部分达到Boost-Free,大大降低了编译的负担。
Module编译
如果你的项目是用C++ 20进行开发的,那么恭喜你,Module编译也是一个优化编译速度的方案,C++20之前的版本会把每一个cpp当做一个编译单元处理,会存在引入的头文件被多次解析编译的问题。而Module的出现就是解决这一问题,Module不再需要头文件(只需要一个模块文件,不需要声明和实现两个文件),它会将你的(.ixx 或者 .cppm)模块实体直接编译,并自动生成一个二进制接口文件。import和include预处理不同,编译好的模块下次import的时候不会重复编译,可以大幅度提高编译器的效率。
外部模板
由于模板被使用时才会实例化这一特性,相同的实例可以出现在多个文件对象中。编译器要对每一处模板进行实例化,链接器还要移除重复的实例化代码。当在广泛使用模板的项目中,编译器会产生大量的冗余代码,这会极大地增加编译时间和链接时间。C++ 11新标准中可以通过外部模板来避免。
// util.h
template <typename T>
void max(T) { ... }// A.cpp
extern template void max<int>(int);
#include "util.h"
template void max<int>(int); // 显式地实例化
void test1()
{
max(1);
}在编译A.cpp的时候,实例化出一个 max<int>(int)版本的函数。
// B.cpp
#include "util.h"
extern template void max<int>(int); // 外部模板的声明
void test2()
{
max(2);
}在编译B.cpp的时候,就不再生成 max<int>(int)实例化代码,这样就节省了前面提到的实例化,编译以及链接的耗时了。
四、其他技巧
预编译头文件(PCH)
把一些常用但不常改动的头文件放在预编译头文件中。这样,至少在单个工程中你不需要在每个编译单元里一遍又一遍的load与解析同一个头文件了。
所谓的预编译头就是把一个工程中的那一部分代码,预先编译好放在一个文件里(通常是以.pch为扩展名的),这个文件就称为预编译头文件。这些预先编译好的代码可以是任何的C/C++代码--------甚至是inline的函数,但是必须是稳定的,在工程开发的过程中不会被经常改变。如果这些代码被修改,则需要重新编译生成预编译头文件。注意生成预编译头文件是很耗时间的。同时你得注意预编译头文件通常很大,通常有6-7M大。注意及时清理那些没有用的预编译头文件。
Unity Build
Unity Build做法很简单,把所有的cpp包含到一个cpp中(all.cpp) ,然后只编译all.cpp。这样我们就只有一个编译单元,这意味着不需要重复load与解析同一个头文件了,同时因为只产生一个obj文件,在链接的时候也不需要那么密集的磁盘操作了。
不要有太多的包含目录
编译器定位你include的头文件,是根据你提供的include directories进行搜索的。可以想象,如果你提供了100个包含目录,而某个头文件是在第100个目录下,定位它的过程是非常痛苦的。组织好你的包含目录,并尽量保持简洁。
具体项目的编译时间分析
编译展开分析
编译展开分析就是通过C++的预编译阶段保留的.ii文件,查看通过展开后的编译文件大小,具体可以通过在cmake中指定编译选型 “-save-temps” 保留编译中间文件,生成位置在build目录下。
set(CMAKE_CXX_FLAGS "-std=c++11 ${CMAKE_CXX_FLAGS} -ggdb -Og -fPIC -w -Wl,--export-dynamic -Wno-deprecated -fpermissive -save-temps")编译耗时的最直接原因就是编译文件展开之后比较大,影响到编译的耗时。通过这个方式能够找到各个文件编译耗时的共性
头文件依赖分析
头文件依赖分析是从引用头文件数量的角度来看代码是否合理的一种分析方式,可以实现了一个脚本,用来统计头文件的依赖关系,并且分析输出头文件依赖引用计数,用来辅助判断头文件依赖关系是否合理。
(1) 头文件引用总数结果统计
通过工具统计出编译源文件直接和间接依赖的头文件的总个数,用来从头文件引入数量上分析问题。
(2) 单个头文件依赖关系统计
通过工具分析头文件依赖关系,生成依赖关系拓扑图,能够直观的看到依赖不合理的地方。
这个可以写个makefile文件来生成所有的依赖关系,然后再写个脚本来分析所有依赖文件。
3.3 编译耗时结果分段统计
cmake通过指定环境变量能打印出编译和链接阶段的耗时情况,通过这个数据能直观的分析出耗时情况。
set_property(GLOBAL PROPERTY RULE_LAUNCH_COMPILE "${CMAKE_COMMAND} -E time")
set_property(GLOBAL PROPERTY RULE_LAUNCH_LINK "${CMAKE_COMMAND} -E time")分析工具建设
通过上面的工具分析能拿到几个编译数据:
① 头文件依赖关系及个数。
② 预编译展开大小及内容。
③ 各个文件编译耗时。
④ 整体链接耗时。
⑤ 可以计算出编译并行度(总编译时间/(各个文件编译时间+链接时间))。
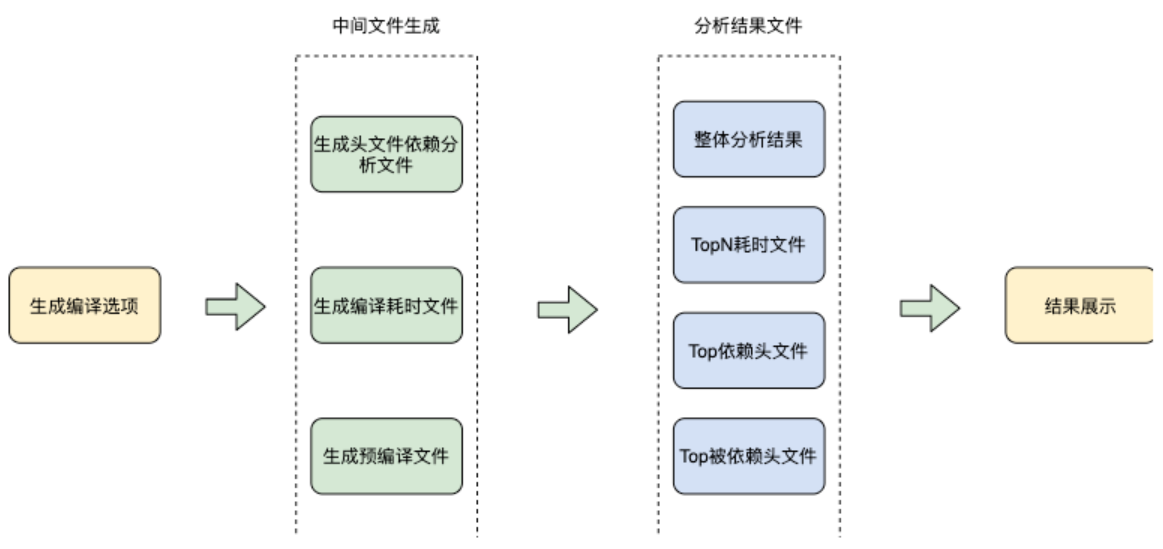
通过这几个数据的输入我们考虑可以做个自动化分析工具,找出优化点以及界面化展示。基于这个目的,我们建设了全流程自动化分析工具,能够自动分析耗时共性问题以及TopN耗时文件。分析工具处理流程如下图所示:
整体统计分析效果
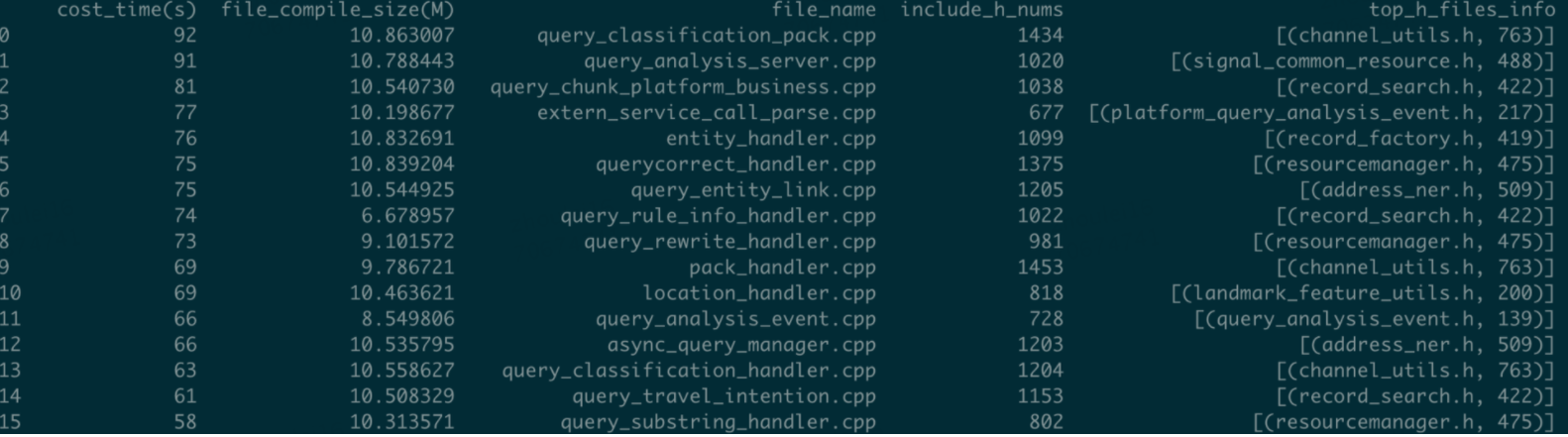
具体字段说明:
① cost_time 编译耗时,单位是秒。
② file_compile_size,编译中间文件大小,单位是M。
③ file_name,文件名称。
④ include_h_nums,引入头文件个数,单位是个。
⑤ top_h_files_info, 引入最多的TopN头文件。