 忧郁的大能猫
忧郁的大能猫
好奇的探索者,理性的思考者,踏实的行动者。
blog/A-IT/10-编程语言/rust/Rust编程第一课
Table of Contents:
- 开篇词|让Rust成为你的下一门主力语言
- 01|内存:值放堆上还是放栈上,这是一个问题
- 02|串讲:编程开发中,那些你需要掌握的基本概念
- 加餐| Rust真的值得我们花时间学习么?
- 03|初窥门径:从你的第一个Rust程序开始!
- 04|get hands dirty:来写个实用的CLI小工具
- 05|get hands dirty:做一个图片服务器有多难?
- 06|get hands dirty:SQL查询工具怎么一鱼多吃?
- 07|所有权:值的生杀大权到底在谁手上?
- 08|所有权:值的借用是如何工作的?
- 09|所有权:一个值可以有多个所有者么?
- 10|生命周期:你创建的值究竟能活多久?
- 11|内存管理:从创建到消亡,值都经历了什么?
- 12|类型系统:Rust的类型系统有什么特点?
- 13|类型系统:如何使用trait来定义接口?
- 14|类型系统:有哪些必须掌握的Trait?
- 15|数据结构:这些浓眉大眼的结构竟然都是智能指针?
- 16|数据结构:
Vec<T>、&[T]、Box<[T]>,你真的了解集合容器么? - 17|数据结构:软件系统核心部件哈希表,内存如何布局?
- 18|错误处理:为什么Rust的错误处理与众不同?
- 19|闭包:FnOnce、FnMut 和 Fn,为什么有这么多类型?
- 20|4 Steps :如何更好地阅读Rust源码?
开篇词|让Rust成为你的下一门主力语言
首先,你使用起来就会感受到,Rust 是一门非常重视开发者用户体验的语言
其次,众所周知的优异性能和强大的表现力,让 Rust 在很多场合都能够施展拳脚。
学习 Rust 的难点
而 Rust 中最大的思维转换就是变量的所有权和生命周期,这是几乎所有编程语言都未曾涉及的领域。
作为一门有着自己独特思想的语言,Rust 采百家之长,
从 C++ 学习并强化了 move 语义和 RAII,
从 Cyclone 借鉴和发展了生命周期,
从 Haskell 吸收了函数式编程和类型系统等。
01|内存:值放堆上还是放栈上,这是一个问题
代码中最基本的概念是变量和值,而存放它们的地方是内存,所以我们就从内存开始。
在编译时,一切无法确定大小或者大小可以改变的数据,都无法安全地放在栈上,最好放在堆上
当我们需要动态大小的内存时,只能使用堆,比如可变长度的数组、列表、哈希表、字典,它们都分配在堆上。
除了动态大小的内存需要被分配到堆上外,动态生命周期的内存也需要分配到堆上。
小结
对于存入栈上的值,它的大小在编译期就需要确定。栈上存储的变量生命周期在当前调用栈的作用域内,无法跨调用栈引用。
堆可以存入大小未知或者动态伸缩的数据类型。堆上存储的变量,其生命周期从分配后开始,一直到释放时才结束,因此堆上的变量允许在多个调用栈之间引用。
一句话对比总结就是:栈上存放的数据是静态的,静态大小,静态生命周期;堆上存放的数据是动态的,动态大小,动态生命周期
02|串讲:编程开发中,那些你需要掌握的基本概念
数据(值和类型、指针和引用)
值无法离开类型单独讨论,类型一般分为原生类型和组合类型。指针和引用都指向值的内存地址,只不过二者在解引用时的行为不一样。引用只能解引用到原来的数据类型,而指针没有这个限制,然而,不受约束的指针解引用,会带来内存安全方面的问题。
代码(函数、方法、闭包、接口和虚表)
函数是代码中重复行为的抽象,方法是对象内部定义的函数,而闭包是一种特殊的函数,它会捕获函数体内使用到的上下文中的自由变量,作为闭包成员的一部分。
而接口将调用者和实现者隔离开,大大促进了代码的复用和扩展。面向接口编程可以让系统变得灵活,当使用接口去引用具体的类型时,我们就需要虚表来辅助运行时代码的执行。有了虚表,我们可以很方便地进行动态分派,它是运行时多态的基础。
运行方式(并发并行、同步异步和 Promise / async / await )
在代码的运行方式中,并发是并行的基础,是同时与多个任务打交道的能力;并行是并发的体现,是同时处理多个任务的手段。同步阻塞后续操作,异步允许后续操作。被广泛用于异步操作的 Promise 代表未来某个时刻会得到的结果,async/await 是 Promise 的封装,一般用状态机来实现。
编程范式(泛型编程)
泛型编程通过参数化让数据结构像函数一样延迟绑定,提升其通用性,类型的参数可以用接口约束,使类型满足一定的行为,同时,在使用泛型结构时,我们的代码也需要更高的抽象度。
加餐| Rust真的值得我们花时间学习么?
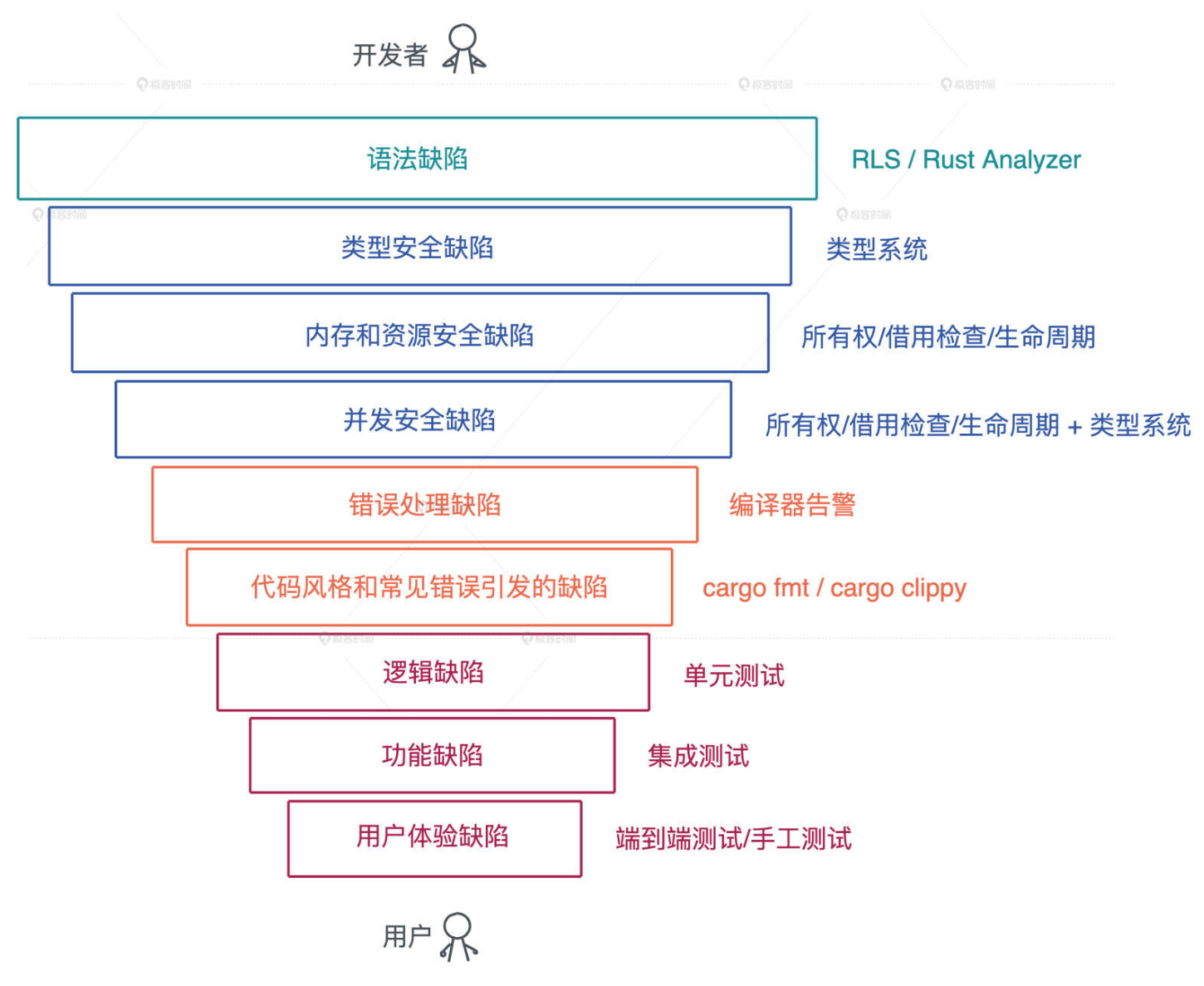
代码缺陷
从软件开发的角度来看,一个软件系统想要提供具有良好用户体验的功能,最基本的要求就是控制缺陷。
为了控制缺陷,在软件工程中,我们定义了各种各样的流程,从代码的格式,到 linting,到 code review,再到单元测试、集成测试、手工测试。
所有这些手段就像一个个漏斗,不断筛查代码,把缺陷一层层过滤掉,让软件在交付到用户时尽善尽美
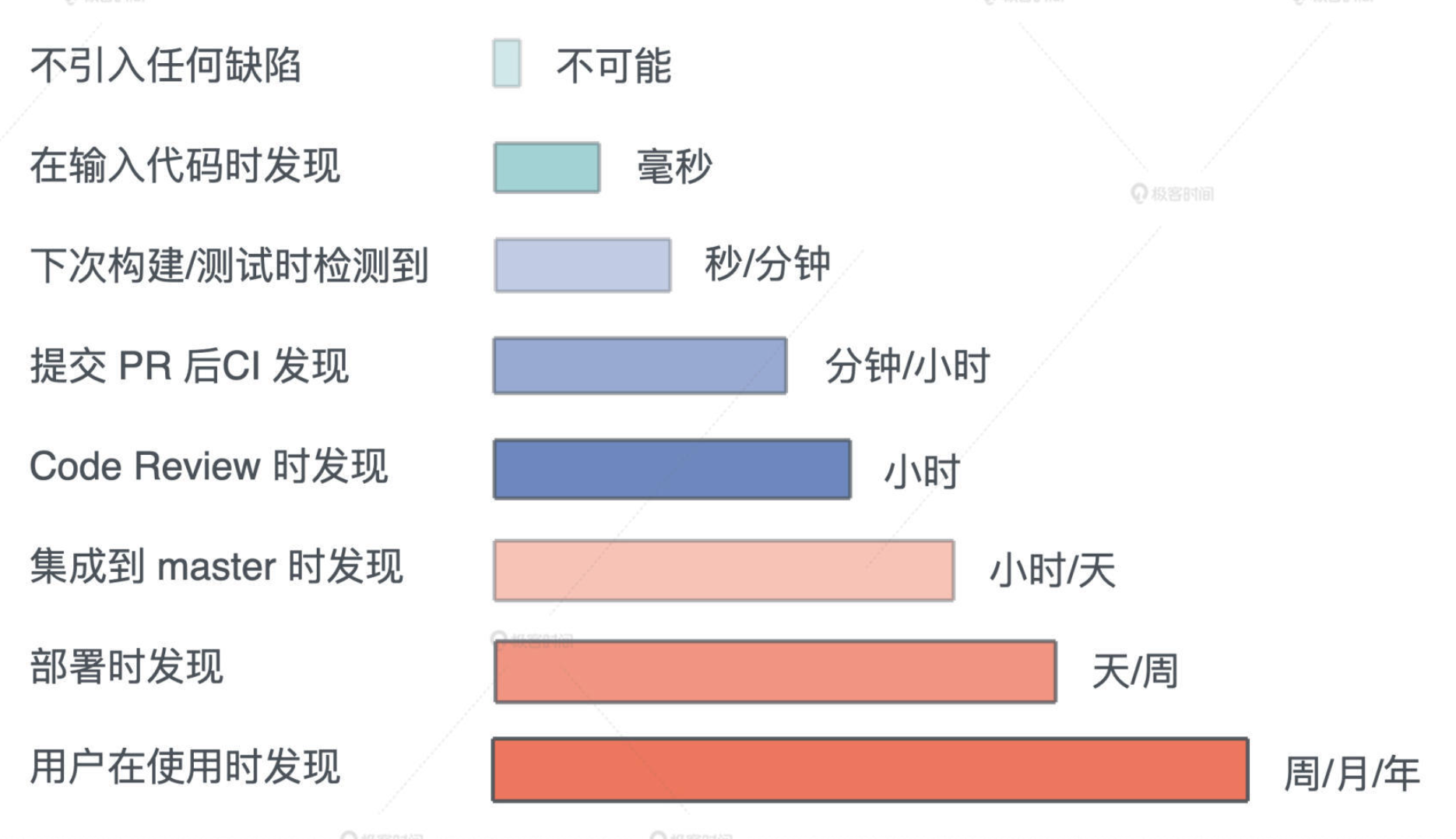
引入缺陷的代价
03|初窥门径:从你的第一个Rust程序开始!
vscode插件
* rust-analyzer:它会实时编译和分析你的 Rust 代码,提示代码中的错误,并对类型进行标注。你也可以使用官方的 rust 插件取代。
* rust syntax:为代码提供语法高亮。
* crates:帮助你分析当前项目的依赖是否是最新的版本。
* better toml:Rust 使用 toml 做项目的配置管理。better toml 可以帮你语法高亮,并展示 toml 文件中的错误。
* rust test lens:可以帮你快速运行某个 Rust 测试。
* Tabnine:基于 AI 的自动补全,可以帮助你更快地撰写代码。
04|get hands dirty:来写个实用的CLI小工具
05|get hands dirty:做一个图片服务器有多难?
06|get hands dirty:SQL查询工具怎么一鱼多吃?
07|所有权:值的生杀大权到底在谁手上?
所有权和生命周期是 Rust 和其它编程语言的主要区别,也是 Rust 其它知识点的基础。
所有权的基本规则:
* 一个值只能被一个变量所拥有,这个变量被称为所有者(Each value in Rust has a variable that’s called its owner)。
* 一个值同一时刻只能有一个所有者(There can only be one owner at a time),也就是说不能有两个变量拥有相同的值。所以对应刚才说的变量赋值、参数传递、函数返回等行为,旧的所有者会把值的所有权转移给新的所有者,以便保证单一所有者的约束。这个就是Move 语义。
* 当所有者离开作用域,其拥有的值被丢弃(When the owner goes out of scope, the value will be dropped),内存得到释放。
例外规则:
* 如果你不希望值的所有权被转移,在 Move 语义外,Rust 提供了 Copy 语义。如果一个数据结构实现了 Copy trait,那么它就会使用 Copy 语义。这样,在你赋值或者传参时,值会自动按位拷贝(浅拷贝)。
* 如果你不希望值的所有权被转移,又无法使用 Copy 语义,那你可以“借用”数据,我们下一讲会详细讨论“借用”。
copy的规则:
* 原生类型,包括函数、不可变引用和裸指针实现了 Copy;
* 数组和元组,如果其内部的数据结构实现了 Copy,那么它们也实现了 Copy;
* 可变引用没有实现 Copy;
* 非固定大小的数据结构,没有实现 Copy。
08|所有权:值的借用是如何工作的?
在 Rust 中,“借用”和“引用”是一个概念,只不过在其他语言中引用的意义和 Rust 不同,所以 Rust 提出了新概念“借用”,便于区分。
- 默认情况下,Rust 的借用都是只读的
- 借用不能超过(outlive)值的生存期,否则编译不过
- 在一个作用域内,仅允许一个活跃的可变引用。所谓活跃,就是真正被使用来修改数据的可变引用,如果只是定义了,却没有使用或者当作只读引用使用,不算活跃。
- 在一个作用域内,活跃的可变引用(写)和只读引用(读)是互斥的,不能同时存在。
09|所有权:一个值可以有多个所有者么?
搞明白了 Rc,我们就进一步理解 Rust 是如何进行所有权的静态检查和动态检查了:
静态检查,靠编译器保证代码符合所有权规则;
动态检查,通过 Box::leak 让堆内存拥有不受限的生命周期,然后在运行过程中,通过对引用计数的检查,保证这样的堆内存最终会得到释放。
如果想绕过“一个值只有一个所有者”的限制,我们可以使用 Rc / Arc 这样带引用计数的智能指针。其中,Rc 效率很高,但只能使用在单线程环境下;Arc 使用了原子结构,效率略低,但可以安全使用在多线程环境下。
然而,Rc / Arc 是不可变的,如果想要修改内部的数据,需要引入内部可变性,在单线程环境下,可以在 Rc 内部使用 RefCell;在多线程环境下,可以使用 Arc 嵌套 Mutex 或者 RwLock 的方法。
10|生命周期:你创建的值究竟能活多久?
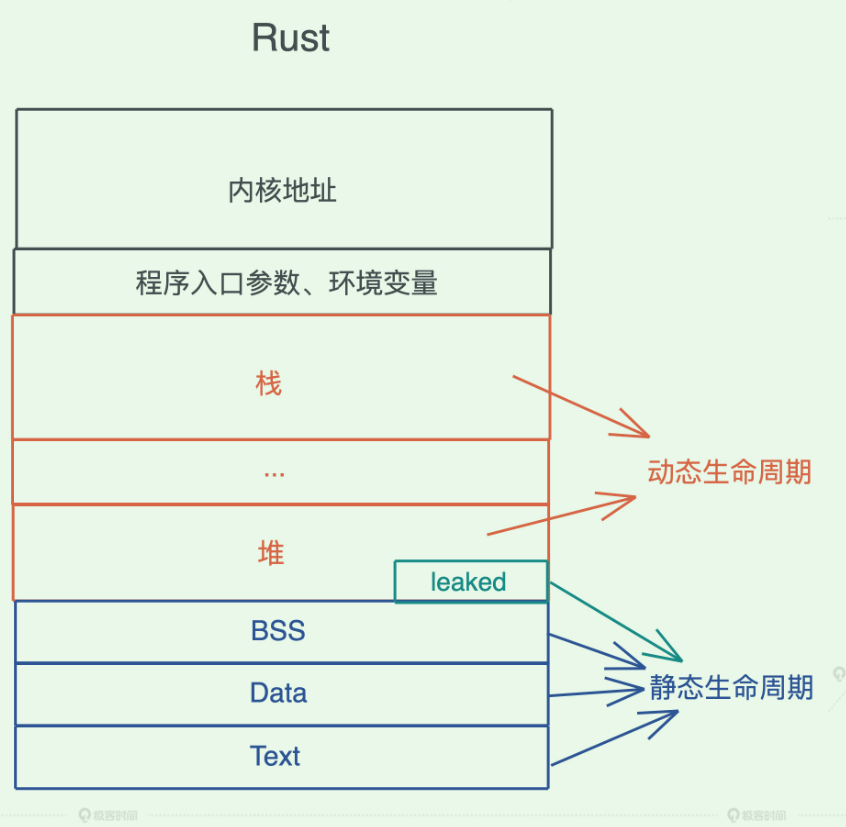
在任何语言里,栈上的值都有自己的生命周期,它和帧的生命周期一致,而 Rust,进一步明确这个概念,并且为堆上的内存也引入了生命周期。
在其它语言中,堆内存的生命周期是不确定的,或者是未定义的。因此,要么开发者手工维护,要么语言在运行时做额外的检查。而在 Rust 中,除非显式地做 Box::leak() / Box::into_raw() / ManualDrop 等动作,一般来说,堆内存的生命周期,会默认和其栈内存的生命周期绑定在一起。
如果一个值的生命周期贯穿整个进程的生命周期,那么我们就称这种生命周期为静态生命周期。
一般来说,全局变量、静态变量、字符串字面量(string literal)等,都拥有静态生命周期。我们上文中提到的堆内存,如果使用了 Box::leak 后,也具有静态生命周期。
函数指针的生命周期也是静态的,因为函数在 Text 段中,只要进程活着,其内存一直存在。
如果一个值是在某个作用域中定义的,也就是说它被创建在栈上或者堆上,那么其生命周期是动态的。
当这个值的作用域结束时,值的生命周期也随之结束。对于动态生命周期,我们约定用 'a 、'b 或者 'hello 这样的小写字符或者字符串来表述。' 后面具体是什么名字不重要,它代表某一段动态的生命周期
生命周期的主要目标是避免悬垂引用(dangling references)
编译器如何识别生命周期
生命周期参数,描述的是参数和参数之间、参数和返回值之间的关系,并不改变原有的生命周期。
编译器自动标注
* 所有引用类型的参数都有独立的生命周期 'a 、'b 等。
* 如果只有一个引用型输入,它的生命周期会赋给所有输出。
* 如果有多个引用类型的参数,其中一个是 self,那么它的生命周期会赋给所有输出。
11|内存管理:从创建到消亡,值都经历了什么?
Rust 的创造者们,重新审视了堆内存的生命周期,发现大部分堆内存的需求在于动态大小,小部分需求是更长的生命周期。所以它默认将堆内存的生命周期和使用它的栈内存的生命周期绑在一起,并留了个小口子 leaked 机制,让堆内存在需要的时候,可以有超出帧存活期的生命周期
struct
对于struct的内存对齐问题,Rust 编译器替我们自动完成了这个优化,这就是为什么 Rust 会自动重排你定义的结构体,来达到最高效率。
enum
在 Rust 下它是一个标签联合体(tagged union),它的大小是标签的大小,加上最大类型的长度。
option占用的内存,引用类型的第一个域是个指针,而指针是不可能等于 0 的,但是我们可以复用这个指针:当其为 0 时,表示 None,否则是 Some,减少了内存占用
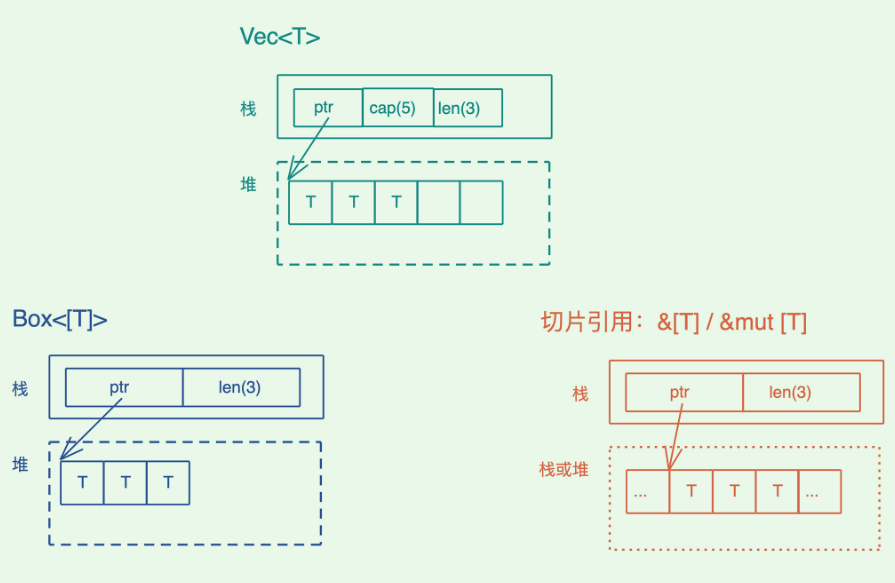
vec<T> 和 String
String 和 Vec<u8> 占用相同的大小,都是 24 个字节。其实,如果你打开 String 结构的源码,可以看到,它内部就是一个 Vec<u8>。
胖指针,结构为:[pointer,capacity,length]
12|类型系统:Rust的类型系统有什么特点?
类型,是对值的区分,它包含了值在内存中的长度、对齐以及值可以进行的操作等信息
类型系统其实就是,对类型进行定义、检查和处理的系统。
按定义后类型是否可以隐式转换,可以分为强类型和弱类型。Rust 不同类型间不能自动转换,所以是强类型语言,而 C / C++ / JavaScript 会自动转换,是弱类型语言。
按类型检查的时机,在编译时检查还是运行时检查,可以分为静态类型系统和动态类型系统。
在类型系统中,多态是一个非常重要的思想,它是指在使用相同的接口时,不同类型的对象,会采用不同的实现。
13|类型系统:如何使用trait来定义接口?
14|类型系统:有哪些必须掌握的Trait?
15|数据结构:这些浓眉大眼的结构竟然都是智能指针?
在 Rust 中,凡是需要做资源回收的数据结构,且实现了 Deref/DerefMut/Drop,都是智能指针。
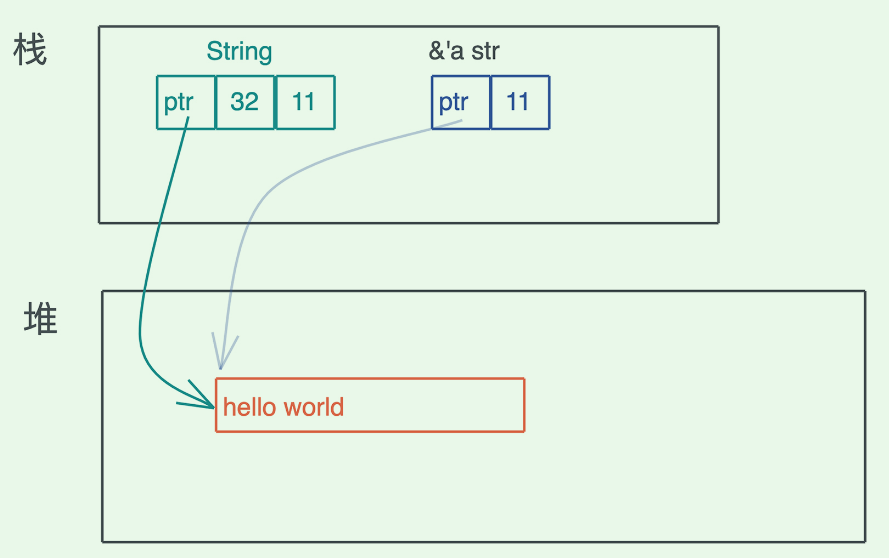
String 对堆上的值有所有权,而 &str 是没有所有权的,这是 Rust 中智能指针和普通胖指针的区别。
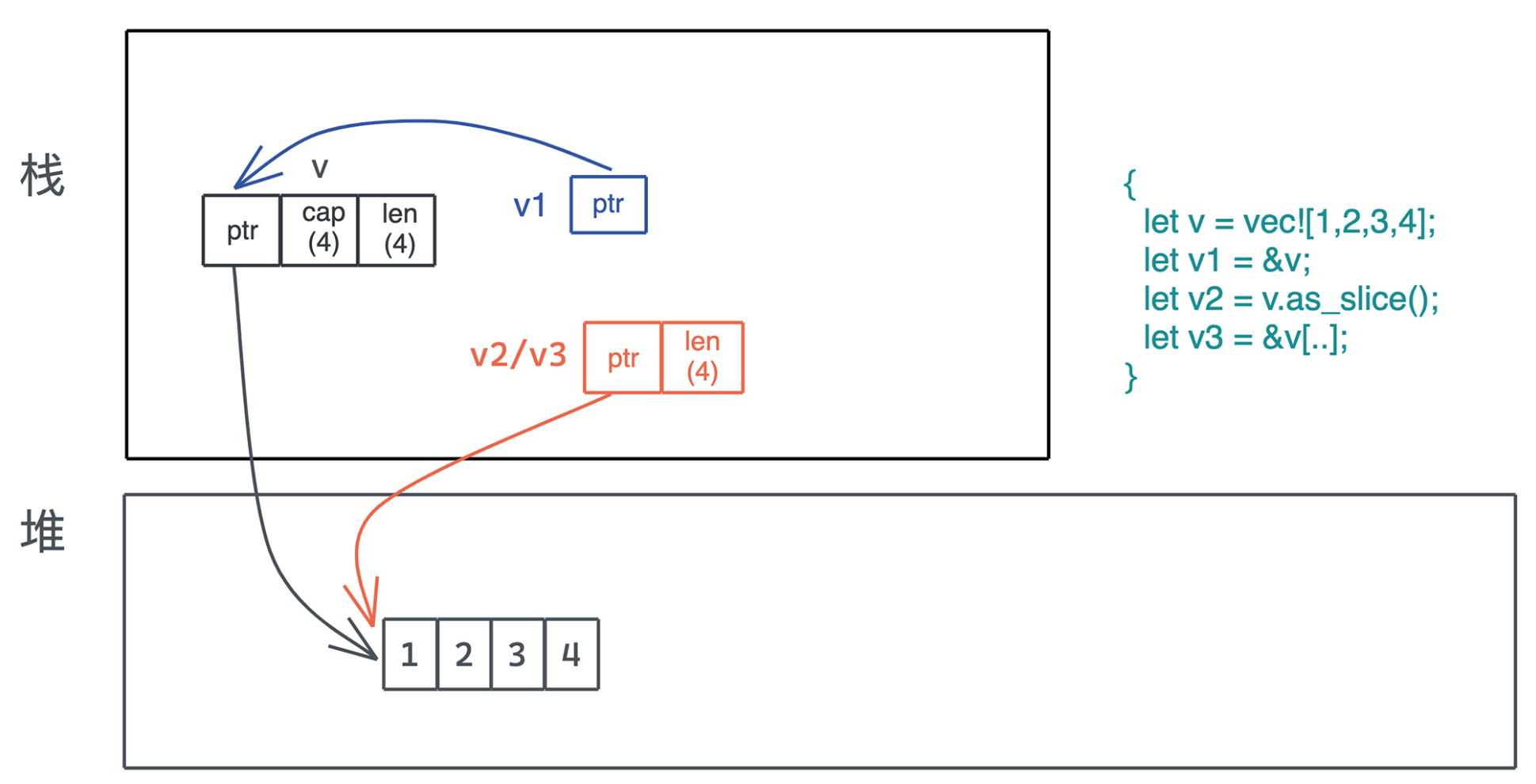
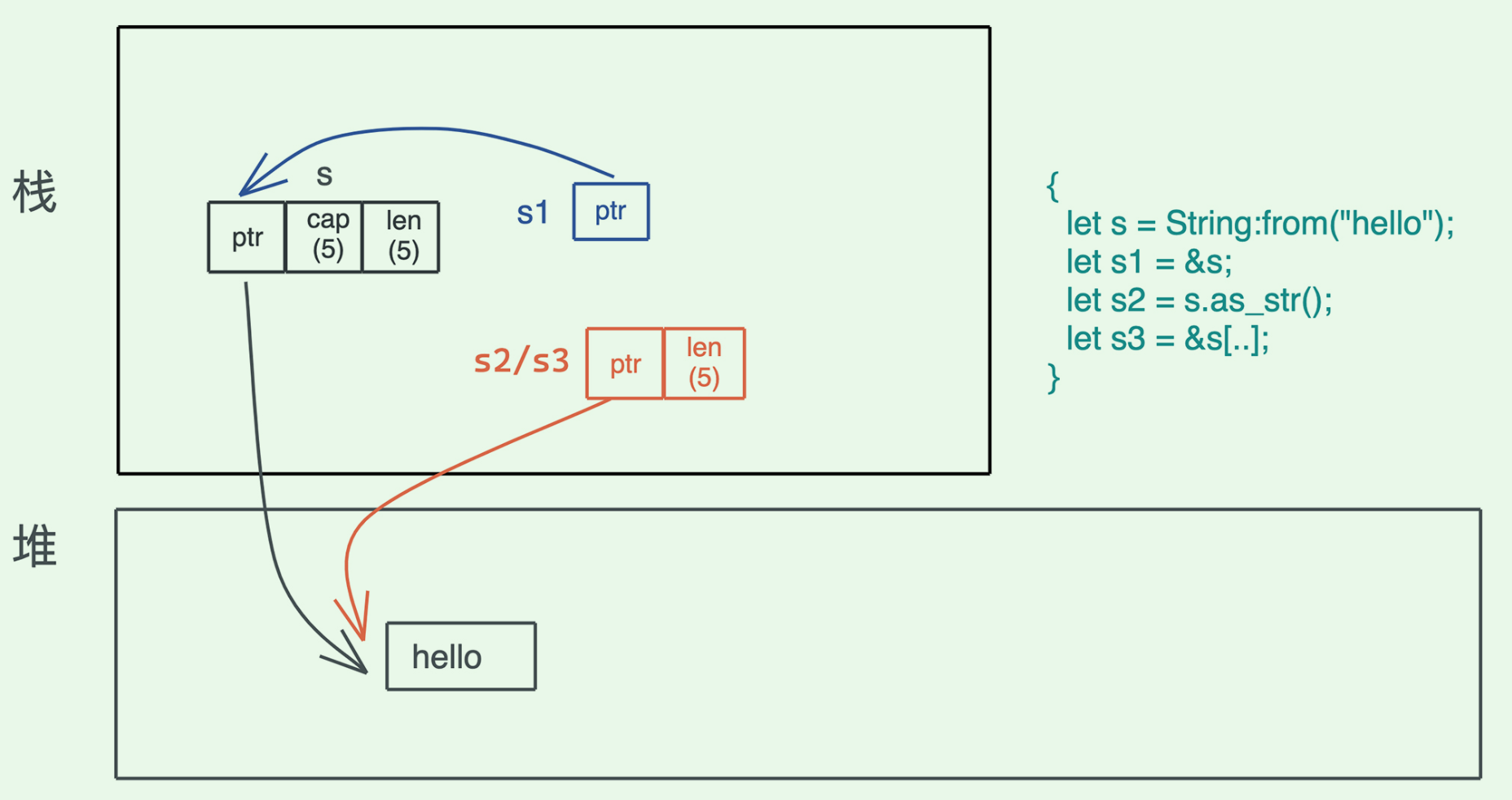
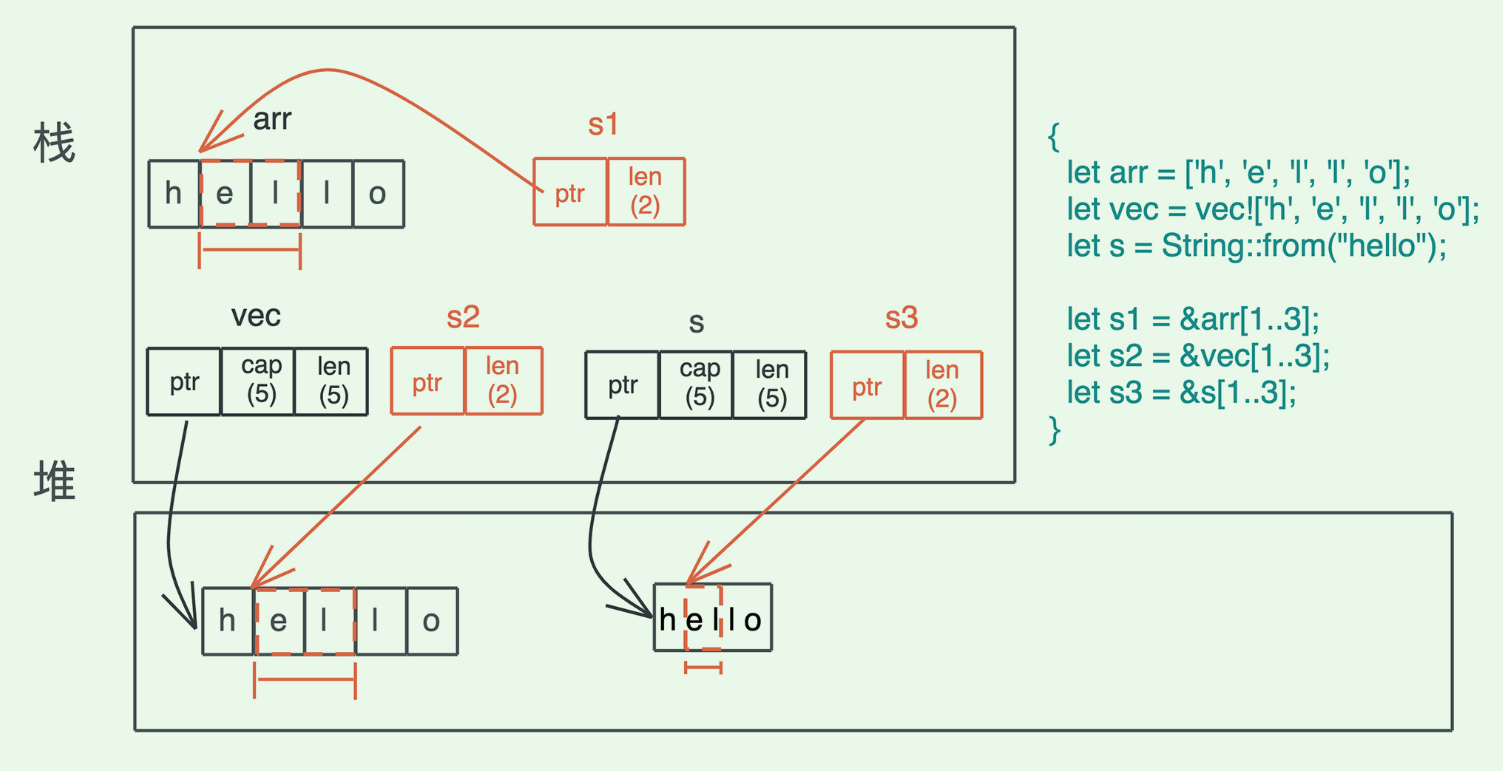
16|数据结构:Vec<T>、&[T]、Box<[T]> ,你真的了解集合容器么?
提到容器,很可能你首先会想到的就是数组、列表这些可以遍历的容器,但其实只要把某种特定的数据封装在某个数据结构中,这个数据结构就是一个容器。比如 Option<T>,它是一个包裹了 T 存在或不存在的容器
切片究竟是什么?
在 Rust 里,切片是描述一组属于同一类型、长度不确定的、在内存中连续存放的数据结构,用 [T] 来表述。因为长度不确定,所以切片是个 DST(Dynamically Sized Type)
切片之于具体的数据结构,就像数据库中的视图之于表.你可以把它看成一种工具,让我们可以统一访问行为相同、结构类似但有些许差异的类型。
&[T]:表示一个只读的切片引用。
&mut [T]:表示一个可写的切片引用。
Box<[T]>:一个在堆上分配的切片。
切片和迭代器 Iterator
迭代器可以说是切片的孪生兄弟。切片是集合数据的视图,而迭代器定义了对集合数据的各种各样的访问操作。
17|数据结构:软件系统核心部件哈希表,内存如何布局?
18|错误处理:为什么Rust的错误处理与众不同?
对我们开发者来说,错误处理包含这么几部分:
当错误发生时,用合适的错误类型捕获这个错误。
错误捕获后,可以立刻处理,也可以延迟到不得不处理的地方再处理,这就涉及到错误的传播(propagate)。
最后,根据不同的错误类型,给用户返回合适的、帮助他们理解问题所在的错误消息。
错误处理的主流方法
错误码
如c语言
缺点:
会混淆函数逻辑的返回值和错误码
多返回值
在函数最后返回一个错误对象
缺点:
在调用者调用时,错误就必须得到处理或者显式的传播。造成代码会有很多if err then return err
非强制性的,若开发者不自觉则会忽略
异常
可以把异常看成一种关注点分离(Separation of Concerns):错误的产生和错误的处理完全被分隔开,调用者不必关心错误,而被调者也不强求调用者关心错误。
缺点:
1.可能会出现异常安全(exception safety)问题
2.开发者会滥用异常。只要有错误,不论是否严重、是否可恢复,都一股脑抛个异常。到了需要的地方,捕获一下了之
使用类型系统