 忧郁的大能猫
忧郁的大能猫
好奇的探索者,理性的思考者,踏实的行动者。
blog/A-IT/20-linux/linux服务器的性能能分析
Table of Contents:
当运行应用程序出现问题时,要从应用程序本身、操作系统、服务器硬件和网络环境等方面综合排查,深度剖析问题出现在哪个部分,才能有针对性地解决。
分析操作系统级性能可以分为以下两步:
1. 需要知道服务器硬件的规格,以了解可以承受的极限是多少。
2. 需要知道各种资源的使用率,以了解性能的瓶颈。
一:影响Linux服务器性能的主要因素
1.cpu
总的来说核数越多、主频越高性能就越高,当然需要的money就越高
这里有几个概念:
1、一台物理机的物理CPU的个数
2、一个CPU上的核数
3、一个核上面支持的线程数
有下面的计算公式:
总核数 = 物理CPU个数 x 每颗物理CPU的核数
总逻辑CPU数 = 物理CPU个数 x 每颗物理CPU的核数 x 超线程数
查看cpu信息
- lscpu
- cat /proc/cpuinfo
# 查看CPU信息(型号)
cat /proc/cpuinfo | grep name | cut -f2 -d: | uniq -c
# 查看物理CPU个数
cat /proc/cpuinfo| grep "physical id"| sort| uniq| wc -l
# 查看每个物理CPU中core的个数(即核数)
cat /proc/cpuinfo| grep "cpu cores"| uniq
# 查看逻辑CPU的个数
cat /proc/cpuinfo| grep "processor"| wc -lCPU架构
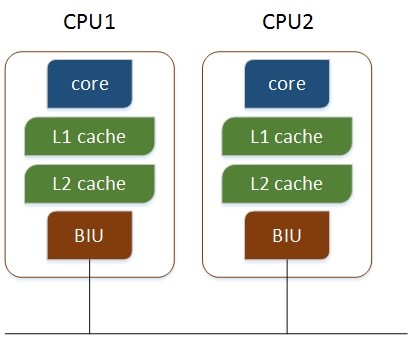
多个物理CPU,各个CPU通过总线进行通信,效率比较低,如下
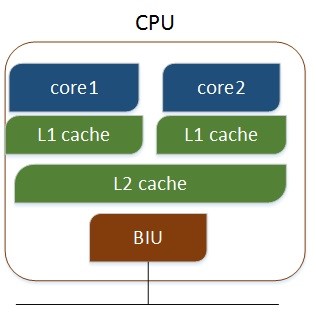
多核CPU,不同的核通过L2 cache进行通信,存储和外设通过总线与CPU通信,如下:
多核超线程,每个核有两个逻辑的处理单元,两个线程共同分享一个核的资源,如下:
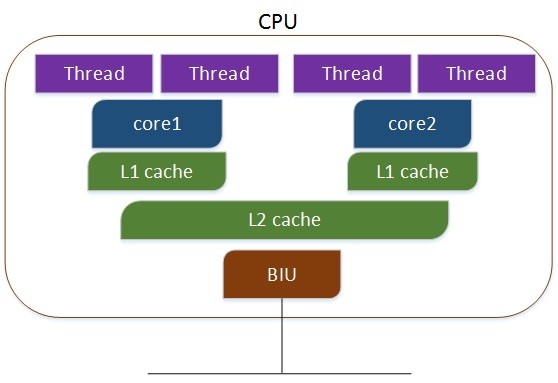
目前大部分CPU在同一时间只能运行一个线程,超线程的处理器可以在同一时间处理多个线程,因此可以利用超线程特性提高系统性能。在linux系统下只有运行SMP(Symmetrical Multi-Processing,对称多处理)内核才能支持超线程。
另外linux内核会将多核的处理器当做多个单独的CPU来识别,例如,两个4核的CPU会被当成8个单个CPU,从性能角度讲,两个4核的CPU整体性能要比8个单核CPU低25%-30%。
2.内存
内存当然是越大性能越高。内存太小,系统进程将被阻塞,应用也将变得缓慢,甚至失去响应。
Linux 系统采用了物理内存和虚拟内存的概念,虚拟内存虽然可以缓解物理内存的不足,但是占用过多的虚拟内存,应用程序的性能将明显下降。
还有考虑系统是32位还是64位,32位系统的最大寻址空间为2的32次方bytes,计算后即4,294,967,296bytes,约4GB,32位系统的寻址空间封顶即为4GB。
查看内存信息
cat /proc/meminfo
free -m3.磁盘io
磁盘的 I/O 能力会直接影响应用程序的性能。比如说,在一个需要频繁读写的应用中,如果磁盘 I/O 性能得不到满足,就会导致应用的停滞。
提升硬盘性能的法宝当然是用ssd硬盘。普通硬盘的读写速度概大是100多M/S左右,而固态硬盘的读写速度则是500多M/S。这里的读取速度是指连续读取速度,实际计算的时候,由于普通硬盘还有寻道时间等开销,所以实际上ssd的读取速度要更高,高出一个数量级应该没啥问题。
查看磁盘信息
fdisk -l # 查看所有分区
df -hl # 查看各分区使用情况
du -h --max-depth=1 # 查看当前目录下的目录大小
du -sh <目录名> # 查看目录总的大小4.网络带宽
Linux下的各种应用,一般都是基于网络的,因此网络带宽也是影响性能的一个重要因素,低速的、不稳定的网络将导致网络应用程序的访问阻塞;而稳定、高速的带宽,可以保证应用程序在网络上畅通无阻地运行。
带宽当然也是越高越好。需要注意的是带宽单位Mbps=Mbit/s即兆比特每秒,跟咱们说的兆是不一样的,1Byte=8bit 需要在这个单位上除以8。即1MB/s=8Mbps
二:系统性能评估标准
- cpu
好 user% + sys% = 70%
坏 user% + sys% = 85%
糟糕 user% + sys% = 90% - 内存
好 swap in(si) = 0 swap out(so) = 0
糟糕 more swap in & swap out - 硬盘
好 iowait% < 20%
坏 iowait% < 35%
糟糕 iowait% < 50%
其中:
%user:表示CPU处在用户模式下的时间百分比。
%sys:表示CPU处在系统模式下的时间百分比。
%iowait:表示CPU等待输入输出完成时间的百分比。
swap in:即si,表示虚拟内存的页导入,即从SWAP DISK交换到RAM
swap out:即so,表示虚拟内存的页导出,即从RAM交换到SWAP DISK。三:系统性能分析工具
| 工具 | 简单介绍 |
|---|---|
| uptime | 查看系统已经运行时长和负载 |
| top | 查看进程活动状态以及一些系统状况 |
| ps | 进程查看工具 |
| vmstat | 查看系统状态、硬件和系统信息等,但查看 CPU 时只能看总体情况 |
| mpstat | Multiprocessor Statistics,可以查看 CPU 各个核的情况 |
| iostat | 查看 CPU 负载,硬盘状况 |
| iotop | 类似 top,监控个进程的 IO 状况 |
| netstat | 查看网络状况 |
| iptraf | IP traffic monitor,实时网络状况监测 |
| tcpdump | 抓取网络数据包,详细分析 |
| netperf | 测试网络带宽的工具 |
| sar | 综合工具,查看系统状况 |
| dstat | 综合工具,综合了 vmstat, iostat, ifstat, netstat 等多个信息 |
| nmon | 综合的工具,CPU、内存、硬盘、带宽等都能看 |
常用组合方式
* 用vmstat、sar、iostat检测是否是CPU瓶颈
* 用free、vmstat检测是否是内存瓶颈
* 用iostat检测是否是磁盘I/O瓶颈
* 用netstat检测是否是网络带宽瓶颈
1.系统整体性能评估
[root@web1 ~]# uptime16:38:00 up 118 days, 3:01, 5 users, load average: 1.22, 1.02, 0.91
这里需要注意的是:load average这个输出值,这三个值的大小一般不能大于系统CPU的个数,例如,本输出中系统有8个CPU,如果load average的三个值长期大于8时,说明CPU很繁忙,负载很高,可能会影响系统性能,但是偶尔大于8时,倒不用担心,一般不会影响系统性能。相反,如果load average的输出值小于CPU的个数,则表示CPU还有空闲的时间片,比如本例中的输出,CPU是非常空闲的。
top工具中顶部也会有load average
2.cpu性能评估
a.评价标准
- CPU 利用率
如果 CPU 有 100% 利用率,那么应该到达这样一个平衡:65%-70% User Time,30%-35% System Time,0%-5% Idle Time; - 上下文切换
上下文切换应该和CPU利用率联系起来看,如果能保持上面的CPU利用率平衡,大量的上下文切换是可以接受的; - 可运行队列
每个可运行队列不应该有超过1-3个线程(每处理器),比如:两个处理器的可运行队列里不应该超过6个线程。
b.vmstat
vmstat是Virtual Meomory Statistics(虚拟内存统计)的缩写, 是实时系统监控工具。
vmstat的语法如下:
vmstat [delay [count]]
# delay 相邻的两次采样的间隔时间
# count 采样的次数,count只能和delay一起使用举个现实中的例子来实际分析一下:
$ vmstat 1
procs -----------memory---------- ---swap-- -----io---- --system-- -----cpu------
r b swpd free buff cache si so bi bo in cs us sy id wa st
14 0 140 2904316 341912 3952308 0 0 0 460 1106 9593 36 64 1 0 0
17 0 140 2903492 341912 3951780 0 0 0 0 1037 9614 35 65 1 0 0
20 0 140 2902016 341912 3952000 0 0 0 0 1046 9739 35 64 1 0 0
17 0 140 2903904 341912 3951888 0 0 0 76 1044 9879 37 63 0 0 0
16 0 140 2904580 341912 3952108 0 0 0 0 1055 9808 34 65 1 0 0从上面的数据可以看出几点:
1.context switch(cs)比 interrupts(in)要高得多,说明内核不得不来回切换进程;
2.进一步观察发现 system time(sy)很高而 user time(us)很低,而且加上高频度的上下文切换(cs),说明正在运行的应用程序调用了大量的系统调用(system call);
3.run queue(r)在14个线程以上,按照这个测试机器的硬件配置(四核),应该保持在12个以内。
参数介绍:
* r(run queue),可运行队列的线程数,这些线程都是可运行状态,这个值如果长期大于系统CPU的个x3,说明CPU不足,需要增加CPU。
* b(blocked),被 blocked 的进程数,正在等待 IO 请求;
* in(interrupts),被处理过的中断数
* cs(context switch),系统上正在做上下文切换的数目
* us(user time),us的值比较高时,说明用户进程消耗的cpu时间多,但是如果长期大于50%,就需要考虑优化程序或算法。
* sy(system time),内核和中断占用 CPU 的百分比,Sy的值较高时,说明内核消耗的CPU资源很多。
* wa,所有可运行的线程被blocked以后都在等待IO,这时候CPU空闲的百分比
* id(idle),CPU完全空闲的百分比
根据经验,us+sy的参考值为80%,如果us+sy大于 80%说明可能存在CPU资源不足。
c.利用sar命令监控系统CPU
sar功能很强大,可以对系统的每个方面进行单独的统计,但是使用sar命令会增加系统开销,不过这些开销是可以评估的,对系统的统计结果不会有很大影响。
下面是sar命令对某个系统的CPU统计输出:
[root@webserver ~]# sar -u 3 5 #u显示系统所有cpu在采样时间内的负载状态
Linux 2.6.9-42.ELsmp (webserver) 11/28/2008 _i686_ (8 CPU)
11:41:24 AM CPU %user %nice %system %iowait %steal %idle
11:41:27 AM all 0.88 0.00 0.29 0.00 0.00 98.83
11:41:30 AM all 0.13 0.00 0.17 0.21 0.00 99.50
11:41:33 AM all 0.04 0.00 0.04 0.00 0.00 99.92
11:41:36 AM all 90.08 0.00 0.13 0.16 0.00 9.63
11:41:39 AM all 0.38 0.00 0.17 0.04 0.00 99.41
Average: all 0.34 0.00 0.16 0.05 0.00 99.45参数介绍:
* %user列显示了用户进程消耗的CPU 时间百分比。
* %nice列显示了运行正常进程所消耗的CPU 时间百分比。
* %system列显示了系统进程消耗的CPU时间百分比。
* %iowait列显示了IO等待所占用的CPU时间百分比
* %steal列显示了在内存相对紧张的环境下pagein强制对不同的页面进行的steal操作 。
* %idle列显示了CPU处在空闲状态的时间百分比。
d.top
top - 17:46:05 up 204 days, 1:59, 1 user, load average: 0.05, 0.05, 0.06
Tasks: 88 total, 1 running, 87 sleeping, 0 stopped, 0 zombie
%Cpu(s): 0.7 us, 1.0 sy, 0.0 ni, 98.3 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
KiB Mem : 1016516 total, 65600 free, 603196 used, 347720 buff/cache
KiB Swap: 0 total, 0 free, 0 used. 230472 avail Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
25808 root 20 0 609104 10836 1624 S 0.7 1.1 37:14.44 barad_agent
9 root 20 0 0 0 0 S 0.3 0.0 21:31.96 rcu_sched
5983 root 20 0 145572 9416 2948 S 0.3 0.9 0:18.80 YDService
25807 root 20 0 158148 8828 1520 S 0.3 0.9 6:43.79 barad_agent
1 root 20 0 41108 2752 1564 S 0.0 0.3 13:18.14 systemd我们重点关注这么几个字段:
load average:三个数字分别表示最近 1 分钟,5 分钟和 15 分钟的负责,数值越大负载越重。一般要求不超过核数,比如对于单核情况要 < 1。如果机器长期处于高于核数的情况,说明机器 CPU 消耗严重了。
%Cpu(s):表示当前 CPU 的使用情况,如果要查看所有核(逻辑核)的使用情况,可以按下数字 “1” 查看。
这里有几个参数,表示如下:
- us 用户空间占用 CPU 时间比例
- sy 系统占用 CPU 时间比例
- ni 用户空间改变过优先级的进程占用 CPU 时间比例
- id CPU 空闲时间比
- wa IO等待时间比(IO等待高时,可能是磁盘性能有问题了)
- hi 硬件中断
- si 软件中断
- st steal time
每个进程的使用情况:这里可以罗列每个进程的使用情况,包括内存和 CPU 的,如果要看某个具体的进程,可以使用 top -p pid 查看。
和 top 一样的还有一个改进版的工具:htop,功能和 top 一样的,只不过比 top 表现更炫酷,使用更方便。
e.利用ps
如何查看某个程序、进程占用了多少 CPU 资源呢?
ps aux
可能很多人会忽略这个命令,觉得这不是查看进程状态信息的吗,其实非也,这个命令配合它的参数能显示很多功能。比如 ps aux。如果配合 watch,可以达到跟 top 一样的效果,如:watch -n 1 "ps aux"(-n 1 表示每隔 1s 更新一次)
2.内存性能评估
a.利用free指令监控内存
free是监控linux内存使用状况最常用的指令,看下面的一个输出:
[root@webserver ~]# free -m #查看以M为单位的内存使用情况
total used free shared buffers cached
Mem: 8111 7185 926 0 243 6299
-/+ buffers/cache: 643 7468
Swap: 8189 0 8189b.利用vmstat命令监控内存
[root@node1 ~]# vmstat 2 3
procs -----------memory---------- ---swap-- -----io---- --system-- -----cpu------
r b swpd free buff cache si so bi bo in cs us sy id wa st
0 0 0 162240 8304 67032 0 0 13 21 1007 23 0 1 98 0 0
0 0 0 162240 8304 67032 0 0 1 0 1010 20 0 1 100 0 0
0 0 0 162240 8304 67032 0 0 1 1 1009 18 0 1 99 0 0memory
swpd列表示切换到内存交换区的内存数量(以k为单位)。如果swpd的值不为0,或者比较大,只要si、so的值长期为0,这种情况下一般不用担心,不会影响系统性能。
free列表示当前空闲的物理内存数量(以k为单位)
buff列表示buffers cache的内存数量,一般对块设备的读写才需要缓冲。
cache列表示page cached的内存数量,一般作为文件系统cached,频繁访问的文件都会被cached,如果cache值较大,说明cached的文件数较多,如果此时IO中bi比较小,说明文件系统效率比较好。
swap
si列表示由磁盘调入内存,也就是内存进入内存交换区的数量。
so列表示由内存调入磁盘,也就是内存交换区进入内存的数量。
一般情况下,si、so的值都为0,如果si、so的值长期不为0,则表示系统内存不足。需要增加系统内存。
3.磁盘I/O性能评估
a.利用iostat评估磁盘性能
centos中用yum install sysstat下载
iostat
Linux 3.10.0-957.el7.x86_64 (localhost) 05/12/2021 _x86_64_ (4 CPU)
avg-cpu: %user %nice %system %iowait %steal %idle
0.24 0.00 0.15 0.02 0.00 99.59
Device: tps kB_read/s kB_wrtn/s kB_read kB_wrtn
sdb 0.28 1.99 0.27 920337 124336
sda 0.67 2.15 11.58 989660 5341307b.利用sar评估磁盘性能
通过“sar –d”组合,可以对系统的磁盘IO做一个基本的统计,请看下面的一个输出:
[root@iZm5ef0xuq9rbysf6lwjouZ ~]# sar -d 2 3
Linux 3.10.0-957.21.3.el7.x86_64 (iZm5ef0xuq9rbysf6lwjouZ) 05/12/2021 _x86_64_ (8 CPU)
05:13:06 PM DEV tps rd_sec/s wr_sec/s avgrq-sz avgqu-sz await svctm %util
05:13:08 PM dev253-0 1.00 0.00 32.00 32.00 0.00 2.00 1.50 0.15
05:13:08 PM DEV tps rd_sec/s wr_sec/s avgrq-sz avgqu-sz await svctm %util
05:13:10 PM dev253-0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
05:13:10 PM DEV tps rd_sec/s wr_sec/s avgrq-sz avgqu-sz await svctm %util
05:13:12 PM dev253-0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
Average: DEV tps rd_sec/s wr_sec/s avgrq-sz avgqu-sz await svctm %util
Average: dev253-0 0.33 0.00 10.67 32.00 0.00 2.00 1.50 0.05
需要关注的几个参数含义:
* await表示平均每次设备I/O操作的等待时间(以毫秒为单位)。
* svctm表示平均每次设备I/O操作的服务时间(以毫秒为单位)。
* %util表示一秒中有百分之几的时间用于I/O操作。
对以磁盘IO性能,一般有如下评判标准:
正常情况下svctm应该是小于await值的,而svctm的大小和磁盘性能有关,CPU、内存的负荷也会对svctm值造成影响,过多的请求也会间接的导致svctm值的增加。
await值的大小一般取决与svctm的值和I/O队列长度以及I/O请求模式,如果svctm的值与await很接近,表示几乎没有I/O等待,磁盘性能很好,如果await的值远高于svctm的值,则表示I/O队列等待太长,系统上运行的应用程序将变慢,此时可以通过更换更快的硬盘来解决问题。
%util项的值也是衡量磁盘I/O的一个重要指标,如果%util接近100%,表示磁盘产生的I/O请求太多,I/O系统已经满负荷的在工作,该磁盘可能存在瓶颈。长期下去,势必影响系统的性能,可以通过优化程序或者通过更换更高、更快的磁盘来解决此问题。
c.iotop查看进程占用io的情况
iotop是一款开源、免费的用来监控磁盘I/O使用状况的类似top命令的工具,iotop可以监控进程的I/O信息。它是Python语言编写的,与iostat工具比较,iostat是系统级别的IO监控,而iotop是进程级别IO监控。
直接执行iotop就可以看到效果了:
Total DISK read: 0.00 B/s | Total DISK write: 0.00 B/s
TID PRIO USER DISK READ DISK WRITE SWAPIN IO> command
1 be/4 root 0.00 B/s 0.00 B/s 0.00 % 0.00 % init [3]
2 be/4 root 0.00 B/s 0.00 B/s 0.00 % 0.00 % [kthreadd]
3 rt/4 root 0.00 B/s 0.00 B/s 0.00 % 0.00 % [migration/0]
4 be/4 root 0.00 B/s 0.00 B/s 0.00 % 0.00 % [ksoftirqd/0]
5 rt/4 root 0.00 B/s 0.00 B/s 0.00 % 0.00 % [watchdog/0]
6 rt/4 root 0.00 B/s 0.00 B/s 0.00 % 0.00 % [migration/1]
7 be/4 root 0.00 B/s 0.00 B/s 0.00 % 0.00 % [ksoftirqd/1]
8 rt/4 root 0.00 B/s 0.00 B/s 0.00 % 0.00 % [watchdog/1]
9 be/4 root 0.00 B/s 0.00 B/s 0.00 % 0.00 % [events/0]
10 be/4 root 0.00 B/s 0.00 B/s 0.00 % 0.00 % [events/1]
11 be/4 root 0.00 B/s 0.00 B/s 0.00 % 0.00 % [khelper]
2572 be/4 root 0.00 B/s 0.00 B/s 0.00 % 0.00 % [bluetooth]4.网络性能评估
- 通过ping命令检测网络的连通性
- 通过netstat –i组合检测网络接口状况
- 通过netstat –r组合检测系统的路由表信息
- 通过sar –n组合显示系统的网络运行状态 sar -n DEV 5 3
a.常用分析
- 查看tcp链接数
netstat -an|awk '/^tcp/{++S[$NF]}END{for (a in S)print a,S[a]}'- 查看连接数最多的ip
netstat -pant |grep ":80"|awk '{print $5}' | awk -F: '{print $1}'|sort|uniq -c|sort -nr- 提取日志 分别是访问URL和URL访问来源 排序
cat access.log|awk '{print $1}'|sort|uniq -c|sort -nr|head -n10
awk '{print $7}' access.log | sort | uniq -c |sort -nr | head -n10 > test.txtb.shell分析nginx日志
178.255.215.86 - - [04/Jul/2013:00:00:31 +0800] "GET /tag/316/PostgreSQL HTTP/1.1" 200 4779 "-" "Mozilla/5.0 (compatible; Exabot/3.0 (BiggerBetter); +http://www.exabot.com/go/robot)" "-"- 178.255.215.86 - - [04/Jul/2013:00:00:34 +0800] "GET /tag/317/edit HTTP/1.1" 303 5 "-" "Mozilla/5.0 (compatible; Exabot/3.0 (BiggerBetter); +http://www.exabot.com/go/robot)" "-"- 103.29.134.200 - - [04/Jul/2013:00:00:34 +0800] "GET /code-snippet/2022/edit HTTP/1.0" 303 0 "-" "Mozilla/5.0 (Windows NT 6.1; rv:17.0) Gecko/17.0 Firefox/17.0" "-"- 103.29.134.200 - - [04/Jul/2013:00:00:35 +0800] "GET /user/login?url=http%3A//outofmemory.cn/code-snippet/2022/edit HTTP/1.0" 200 4748 "-" "Mozilla/5.0 (Windows NT 6.1; rv:17.0) Gecko/17.0 Firefox/17.0" "-"-以下脚本都是基于上面日志格式的,如果你的日志格式不同需要调整awk后面的参数。
* 分析日志中的UserAgent(最多的20个UserAgent)
cat access_20130704.log | awk -F "\"" '{print $(NF-3)}' | sort | uniq -c | sort -nr | head -20- 分析日志中那些IP访问最多
cat access_20130704.log | awk '{print $1}' | sort | uniq -c | sort -nr | head -20- 分析日志中那些Url请求访问次数最多
cat access_20130704.log | awk -F "\"" '{print $(NF-5)}' | sort | uniq -c | sort -nr | head -20