 忧郁的大能猫
忧郁的大能猫
好奇的探索者,理性的思考者,踏实的行动者。
blog/A-IT/50-应用方向/web后端/Kafka核心技术与实战
Table of Contents:
- 开篇词 | 为什么要学习Kafka?
- 01 | 消息引擎系统ABC
- 02 | 一篇文章带你快速搞定Kafka术语
- 03 | Kafka只是消息引擎系统吗?
- 04 | 我应该选择哪种Kafka?
- 05 | 聊聊Kafka的版本号
- 06 | Kafka线上集群部署方案怎么做?
- 07 | 最最最重要的集群参数配置(上)
- 08 | 最最最重要的集群参数配置(下)
- 09 | 生产者消息分区机制原理剖析
- 10 | 生产者压缩算法面面观
- 11 | 无消息丢失配置怎么实现?
- 12 | 客户端都有哪些不常见但是很高级的功能?
- 13 | Java生产者是如何管理TCP连接的?
- 14 | 幂等生产者和事务生产者是一回事吗?
- 15 | 消费者组到底是什么?
- 16 | 揭开神秘的“位移主题”面纱
- 17 | 消费者组重平衡能避免吗?
开篇词 | 为什么要学习Kafka?
01 | 消息引擎系统ABC
Apache Kafka 是一款开源的消息引擎系统。
根据维基百科的定义,消息引擎系统是一组规范。企业利用这组规范在不同系统之间传递语义准确的消息,实现松耦合的异步式数据传递。
如果觉得难于理解,那么可以试试我下面这个民间版:
系统 A 发送消息给消息引擎系统,系统 B 从消息引擎系统中读取 A 发送的消息。
最基础的消息引擎就是做这点事的!不论是上面哪个版本,它们都提到了两个重要的事实:
* 消息引擎传输的对象是消息;
* 如何传输消息属于消息引擎设计机制的一部分。
Kafka 使用的是纯二进制的字节序列。当然消息还是结构化的,只是在使用之前都要将其转换成二进制的字节序列。
消息设计出来之后还不够,消息引擎系统还要设定具体的传输协议,即我用什么方法把消息传输出去。常见的有两种方法:
* 点对点模型:也叫消息队列模型。
* 发布 / 订阅模型:和点对点模型不同的是,这个模型可能存在多个发布者向相同的主题发送消息,而订阅者也可能存在多个,它们都能接收到相同主题的消息。生活中的报纸订阅就是一种典型的发布 / 订阅模型。
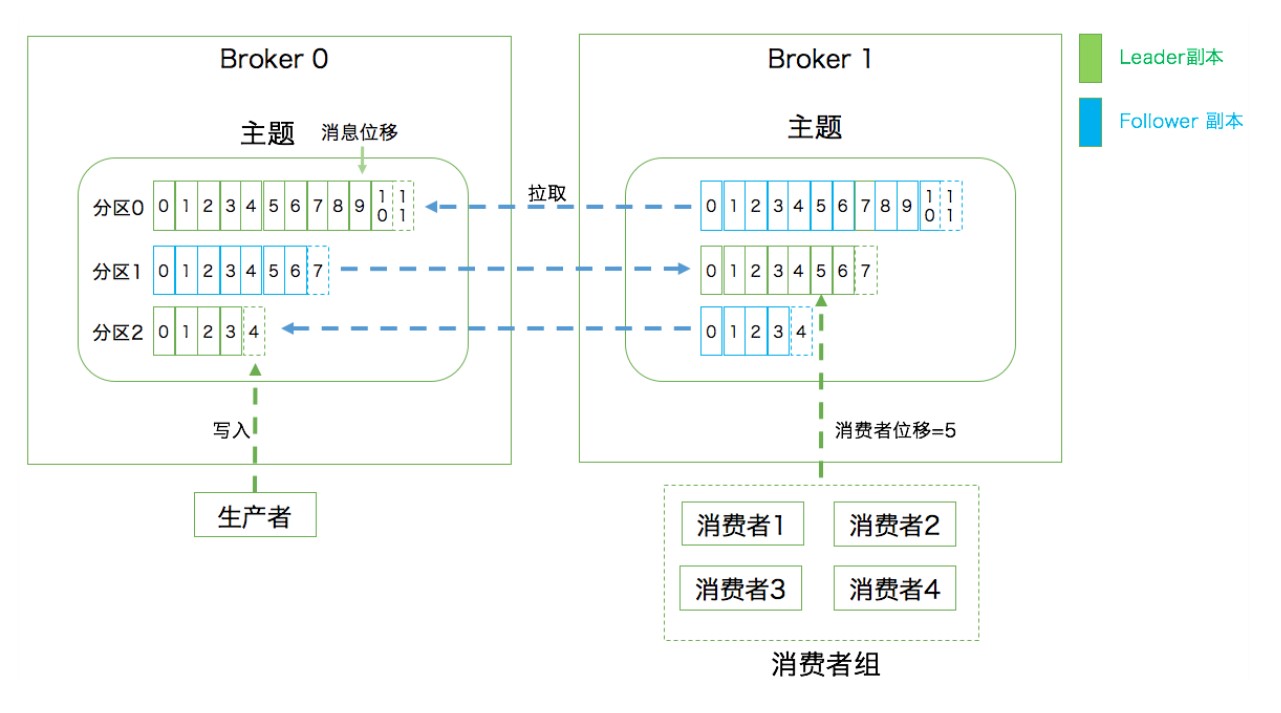
02 | 一篇文章带你快速搞定Kafka术语
向主题发布消息的客户端应用程序称为生产者(Producer),生产者程序通常持续不断地向一个或多个主题发送消息,而订阅这些主题消息的客户端应用程序就被称为消费者(Consumer)。和生产者类似,消费者也能够同时订阅多个主题的消息。我们把生产者和消费者统称为客户端(Clients)。你可以同时运行多个生产者和消费者实例,这些实例会不断地向 Kafka 集群中的多个主题生产和消费消息。
有客户端自然也就有服务器端。Kafka 的服务器端由被称为 Broker 的服务进程构成,即一个 Kafka 集群由多个 Broker 组成,Broker 负责接收和处理客户端发送过来的请求,以及对消息进行持久化。虽然多个 Broker 进程能够运行在同一台机器上,但更常见的做法是将不同的 Broker 分散运行在不同的机器上,这样如果集群中某一台机器宕机,即使在它上面运行的所有 Broker 进程都挂掉了,其他机器上的 Broker 也依然能够对外提供服务。这其实就是 Kafka 提供高可用的手段之一。
本节的名词术语:
* 消息:Record。Kafka 是消息引擎嘛,这里的消息就是指 Kafka 处理的主要对象。
* 主题:Topic。主题是承载消息的逻辑容器,在实际使用中多用来区分具体的业务。
* 分区:Partition。一个有序不变的消息序列。每个主题下可以有多个分区。
* 消息位移:Offset。表示分区中每条消息的位置信息,是一个单调递增且不变的值。
* 副本:Replica。Kafka 中同一条消息能够被拷贝到多个地方以提供数据冗余,这些地方就是所谓的副本。副本还分为领导者副本和追随者副本,各自有不同的角色划分。副本是在分区层级下的,即每个分区可配置多个副本实现高可用。
* 生产者:Producer。向主题发布新消息的应用程序。
* 消费者:Consumer。从主题订阅新消息的应用程序。
* 消费者位移:Consumer Offset。表征消费者消费进度,每个消费者都有自己的消费者位移。
* 消费者组:Consumer Group。多个消费者实例共同组成的一个组,同时消费多个分区以实现高吞吐。
* 重平衡:Rebalance。消费者组内某个消费者实例挂掉后,其他消费者实例自动重新分配订阅主题分区的过程。Rebalance 是 Kafka 消费者端实现高可用的重要手段。
03 | Kafka只是消息引擎系统吗?
Apache Kafka 是消息引擎系统,也是一个分布式流处理平台(Distributed Streaming Platform)。
Kafka 是 LinkedIn 公司内部孵化的项目。LinkedIn 最开始有强烈的数据强实时处理方面的需求,其内部的诸多子系统要执行多种类型的数据处理与分析,主要包括业务系统和应用程序性能监控,以及用户行为数据处理等。
Apache Kafka 从一个优秀的消息引擎系统起家,逐渐演变成现在分布式的流处理平台。
04 | 我应该选择哪种Kafka?
Kafka 不再是一个单纯的消息引擎系统,而是能够实现精确一次(Exactly-once)处理语义的实时流处理平台。
- Apache Kafka,也称社区版 Kafka。优势在于迭代速度快,社区响应度高,使用它可以让你有更高的把控度;缺陷在于仅提供基础核心组件,缺失一些高级的特性。
- Confluent Kafka,Confluent 公司提供的 Kafka。优势在于集成了很多高级特性且由 Kafka 原班人马打造,质量上有保证;缺陷在于相关文档资料不全,普及率较低,没有太多可供参考的范例。
- CDH/HDP Kafka,大数据云公司提供的 Kafka,内嵌 Apache Kafka。优势在于操作简单,节省运维成本;缺陷在于把控度低,演进速度较慢。
特点比较
1. Apache Kafka
如果你仅仅需要一个消息引擎系统亦或是简单的流处理应用场景,同时需要对系统有较大把控度,那么我推荐你使用 Apache Kafka。
2. Confluent Kafka
如果你需要用到 Kafka 的一些高级特性,那么推荐你使用 Confluent Kafka。
3. CDH/HDP Kafka
如果你需要快速地搭建消息引擎系统,或者你需要搭建的是多框架构成的数据平台且 Kafka 只是其中一个组件,那么我推荐你使用这些大数据云公司提供的 Kafka。
05 | 聊聊Kafka的版本号
每个 Kafka 版本都有它恰当的使用场景和独特的优缺点,切记不要一味追求最新版本。事实上我周围的很多工程师都秉承这样的观念:不要成为最新版本的“小白鼠”。
06 | Kafka线上集群部署方案怎么做?

07 | 最最最重要的集群参数配置(上)
08 | 最最最重要的集群参数配置(下)
09 | 生产者消息分区机制原理剖析
分区策略
所谓分区策略是决定生产者将消息发送到哪个分区的算法。Kafka 为我们提供了默认的分区策略,同时它也支持你自定义分区策略。
* 轮询策略
* 随机策略
* 按消息键保序策略
今天我们讨论了 Kafka 生产者消息分区的机制以及常见的几种分区策略。切记分区是实现负载均衡以及高吞吐量的关键,故在生产者这一端就要仔细盘算合适的分区策略,避免造成消息数据的“倾斜”,使得某些分区成为性能瓶颈,这样极易引发下游数据消费的性能下降。
10 | 生产者压缩算法面面观
最佳实践
首先来说压缩。何时启用压缩是比较合适的时机呢?
你现在已经知道 Producer 端完成的压缩,那么启用压缩的一个条件就是 Producer 程序运行机器上的 CPU 资源要很充足。如果 Producer 运行机器本身 CPU 已经消耗殆尽了,那么启用消息压缩无疑是雪上加霜,只会适得其反。
除了 CPU 资源充足这一条件,如果你的环境中带宽资源有限,那么我也建议你开启压缩。事实上我见过的很多 Kafka 生产环境都遭遇过带宽被打满的情况。这年头,带宽可是比 CPU 和内存还要珍贵的稀缺资源,毕竟万兆网络还不是普通公司的标配,因此千兆网络中 Kafka 集群带宽资源耗尽这件事情就特别容易出现。如果你的客户端机器 CPU 资源有很多富余,我强烈建议你开启 zstd 压缩,这样能极大地节省网络资源消耗。
小结:我们主要讨论了 Kafka 压缩的各个方面,包括 Kafka 是如何对消息进行压缩的、何时进行压缩及解压缩,还对比了目前 Kafka 支持的几个压缩算法,最后我给出了工程化的最佳实践。
11 | 无消息丢失配置怎么实现?
最佳实践
1. 不要使用 producer.send(msg),而要使用 producer.send(msg, callback)。记住,一定要使用带有回调通知的 send 方法。
2. 设置 acks = all。acks 是 Producer 的一个参数,代表了你对“已提交”消息的定义。如果设置成 all,则表明所有副本 Broker 都要接收到消息,该消息才算是“已提交”。这是最高等级的“已提交”定义。
3. 设置 retries 为一个较大的值。这里的 retries 同样是 Producer 的参数,对应前面提到的 Producer 自动重试。当出现网络的瞬时抖动时,消息发送可能会失败,此时配置了 retries > 0 的 Producer 能够自动重试消息发送,避免消息丢失。
4. 设置 unclean.leader.election.enable = false。这是 Broker 端的参数,它控制的是哪些 Broker 有资格竞选分区的 Leader。如果一个 Broker 落后原先的 Leader 太多,那么它一旦成为新的 Leader,必然会造成消息的丢失。故一般都要将该参数设置成 false,即不允许这种情况的发生。
5. 设置 replication.factor >= 3。这也是 Broker 端的参数。其实这里想表述的是,最好将消息多保存几份,毕竟目前防止消息丢失的主要机制就是冗余。
6. 设置 min.insync.replicas > 1。这依然是 Broker 端参数,控制的是消息至少要被写入到多少个副本才算是“已提交”。设置成大于 1 可以提升消息持久性。在实际环境中千万不要使用默认值 1。
7. 确保 replication.factor > min.insync.replicas。如果两者相等,那么只要有一个副本挂机,整个分区就无法正常工作了。我们不仅要改善消息的持久性,防止数据丢失,还要在不降低可用性的基础上完成。推荐设置成 replication.factor = min.insync.replicas + 1。
8. 确保消息消费完成再提交。Consumer 端有个参数 enable.auto.commit,最好把它设置成 false,并采用手动提交位移的方式。就像前面说的,这对于单 Consumer 多线程处理的场景而言是至关重要的。
12 | 客户端都有哪些不常见但是很高级的功能?
小结
今天我们花了一些时间讨论 Kafka 提供的冷门功能:拦截器。如之前所说,拦截器的出场率极低,以至于我从未看到过国内大厂实际应用 Kafka 拦截器的报道。但冷门不代表没用。事实上,我们可以利用拦截器满足实际的需求,比如端到端系统性能检测、消息审计等。
13 | Java生产者是如何管理TCP连接的?
Kafka 生产者程序概览
第 1 步:构造生产者对象所需的参数对象。
第 2 步:利用第 1 步的参数对象,创建 KafkaProducer 对象实例。
第 3 步:使用 KafkaProducer 的 send 方法发送消息。
第 4 步:调用 KafkaProducer 的 close 方法关闭生产者并释放各种系统资源。
14 | 幂等生产者和事务生产者是一回事吗?
小结
幂等性 Producer 和事务型 Producer 都是 Kafka 社区力图为 Kafka 实现精确一次处理语义所提供的工具,只是它们的作用范围是不同的。幂等性 Producer 只能保证单分区、单会话上的消息幂等性;而事务能够保证跨分区、跨会话间的幂等性。从交付语义上来看,自然是事务型 Producer 能做的更多。
不过,切记天下没有免费的午餐。比起幂等性 Producer,事务型 Producer 的性能要更差,在实际使用过程中,我们需要仔细评估引入事务的开销,切不可无脑地启用事务。
15 | 消费者组到底是什么?
Rebalance 本质上是一种协议,规定了一个 Consumer Group 下的所有 Consumer 如何达成一致,来分配订阅 Topic 的每个分区