 忧郁的大能猫
忧郁的大能猫
好奇的探索者,理性的思考者,踏实的行动者。
blog/A-IT/50-应用方向/机器学习/PyTorch生成对抗网络编程(Make-Your-First-GAN-With-PyTorch)
Table of Contents:
一、PyTorch和神经网络
1.1 PyTorch入门
学习要点:
● Colab服务允许我们在谷歌的服务器上运行Python代码。Colab使用Python笔记本,我们只需要一个Web浏览器即可使用。
● PyTorch是一个领先的Python机器学习架构。它与numpy类似,允许我们使用数字数组。同时,它也提供了丰富的工具集和函数,使机器学习更容易上手。
● 在PyTorch中,数据的基本单位是张量(tensor)。张量可以是多维数组、简单的二维矩阵、一维列表,也可以是单值。
● PyTorch的主要特性是能够自动计算函数的梯度(gradient)。梯度的计算是训练神经网络的关键。为此,PyTorch需要构建一张计算图(computation graph),图中包含多个张量以及它们之间的关系。在代码中,该过程在我们以一个张量定义另一个张量时自动完成。
张量
一个PyTorch张量可以包含以下内容。
● 除原始数值之外的附加信息,比如梯度值。
● 关于它所依赖的其他张量的信息,以及这种依赖的数学表达式。
import torch
x = torch.tensor(3.5, requires_grad=True)
y = (x-1) * (x-2) * (x-3) # y中包含了关于x的数学表达式
y.backward() # 计算出反向的梯度
x.grad计算图
# (x) --> (y) --> (z)
x = torch.tensor(3.5, requires_grad=True)
y = x*x
z = 2*y + 3
z.backward() # 反向传播
print(x.grad) # 梯度dz/dx在张量x中被存储为x.grad值得注意的是,张量x内部的梯度值与z的变化有关。这是因为我们要求PyTorch使用 z.backward()从z反向计算。因此,x.grad是dz/dx,而不是dy/dx
多个节点的情况:
(a) --> (x)
\ / \
. (z)
/ \ /
(b) --> (y)
x = 2a + 3b
y = 5a^2 + 3b^3
z = 2x + 3y计算图如下:
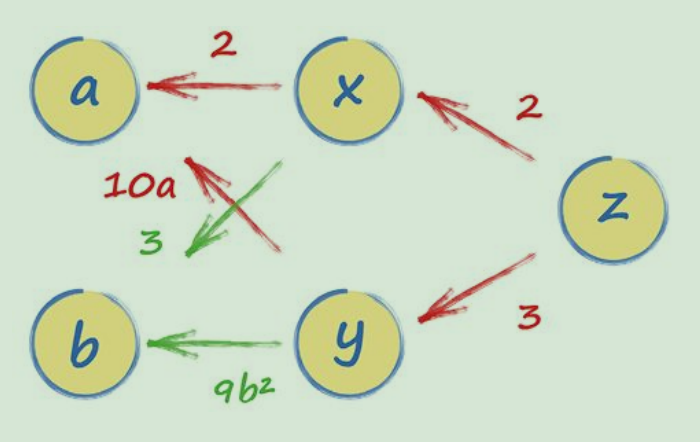
可以轻易地通过z到a的路径计算出梯度dz/da。实际上,从z到a有两条路径,一条通过x,另一条通过y,我们只需要把两条路径的表达式相加即可。这么做是合理的,因为从a到z的两条路径都影响了z的值,这也与我们用微积分的链式法则计算出的dz/da的结果一致。
# set up simple graph relating x, y and z
a = torch.tensor(2.0, requires_grad=True)
b = torch.tensor(1.0, requires_grad=True)
x = 2*a + 3*b
y = 5*a*a + 3*b*b*b
z = 2*x + 3*y
z.backward()
a.grad1.2 初试PyTorch神经网络
学习要点:
● 在使用新的数据或者构建新的流程前,应尽量先通过预览了解数据。这样做可以确保数据被正常载入和变换。
● PyTorch可以替我们完成机器学习中的许多工作。为了充分利用PyTorch,我们需要重复使用它的一些功能。比如,神经网络类需要从PyTorch的nn.Module父类继承。
● 通过可视化观察损失值, 了解训练进程是很推荐的。
● 均方误差损失适用于输出是连续值的回归任务;二元交叉熵损失更适合输出是1或0(true或false)的分类任务。
● 传统的S型激活函数在处理较大值时,具有梯度消失的缺点。这在网络训练时会造成反馈信号减弱。ReLU激活函数部分解决了这一问题,保持正值部分良好的梯度值。LeakyReLU进一步改良,在负值部分增加一个很小却不会消失的梯度值。
● Adam优化器使用动量来避免进入局部最小值,并保持每个可学习参数独立的学习率。在许多任务上,使用它的效果优于SGD优化器。
● 标准化可以稳定神经网络的训练。一个网络的初始权重通常需要标准化。在信号通过一个神经网络时,使用LayerNorm标准化信号值可以提升网络性能。
MNIST图像数据集
pandas DataFrame是一个与numpy数组相似的数据结构,具有许多附加功能,包括可为列和行命名,以及提供便利函数对数据求和和过滤等。
我们可以使用head()函数查看一个较大DataFrame的前几行。
# import pandas to read csv files
import pandas
# import matplotlib to show images
import matplotlib.pyplot as plt
df = pandas.read_csv('./mnist_data/mnist_train.csv', header=None)
df.head() # 查看前几行
df.info()
# draw img
row = 13
data = df.iloc[row]
# label is the first value
label = data[0]
# image data is the remaining 784 values
img = data[1:].values.reshape(28,28)
plt.title("label = " + str(label))
plt.imshow(img, interpolation='none', cmap='Blues')
plt.show()简单的神经网络
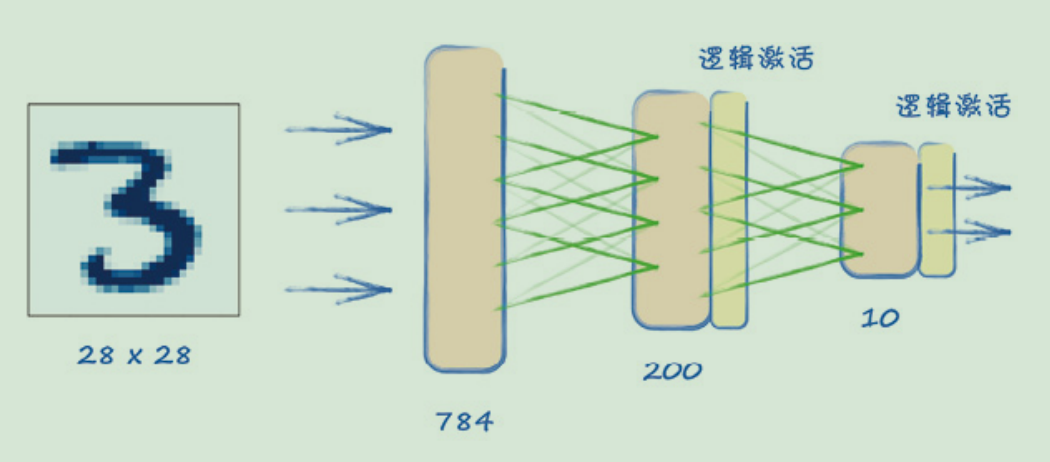
网络中任何一层的所有节点,都会连接到下一层中的所有节点。这种网络层也被称为全连接层(fully connected layer)
当创建神经网络类时,我们需要继承PyTorch的torch.nn模块,nn是“neural networks”的缩写。这样一来,新的神经网络就具备了许多PyTorch的功能,如自动构建计算图、查看权重以及在训练期间更新权重等。
设计网络结构有多种方法。对于简单的网络,我们可以使用 nn.Sequential(),它允许我们提供一个网络模块的列表。模块必须按照我们希望的信息传递顺序添加到容器中。
nn.Linear因何得名?这是因为,当数值从输入端传递到输出端时,该模块对它们应用了Ax + B形式的线性函数。这里,A为链接权重,B为偏差(bias)。
我们发现,“误差函数”(error function)和“损失函数”(loss function)这两个词常被互换使用,通常这是可以接受的。如果希望更精确一些,“误差”单纯指预期输出和实际输出之间的差值,而“损失”是根据误差计算得到的,需要考虑具体需要解决的问题。
可视化训练
跟踪训练的一种方法是监控损失
在train()中,我们在每次计算损失值时,将副本保存在一个列表里。这意味着该表会变得非常大,因为训练神经网络通常会运行成千上万、甚至百万个样本。MNIST数据集有60 000个训练样本,而且我们可能需要运行好几个周期(epoch)。一种更好的方法是,在每完成10个训练样本之后保留一份损失副本。这就需要我们记录train() 的运行频率。
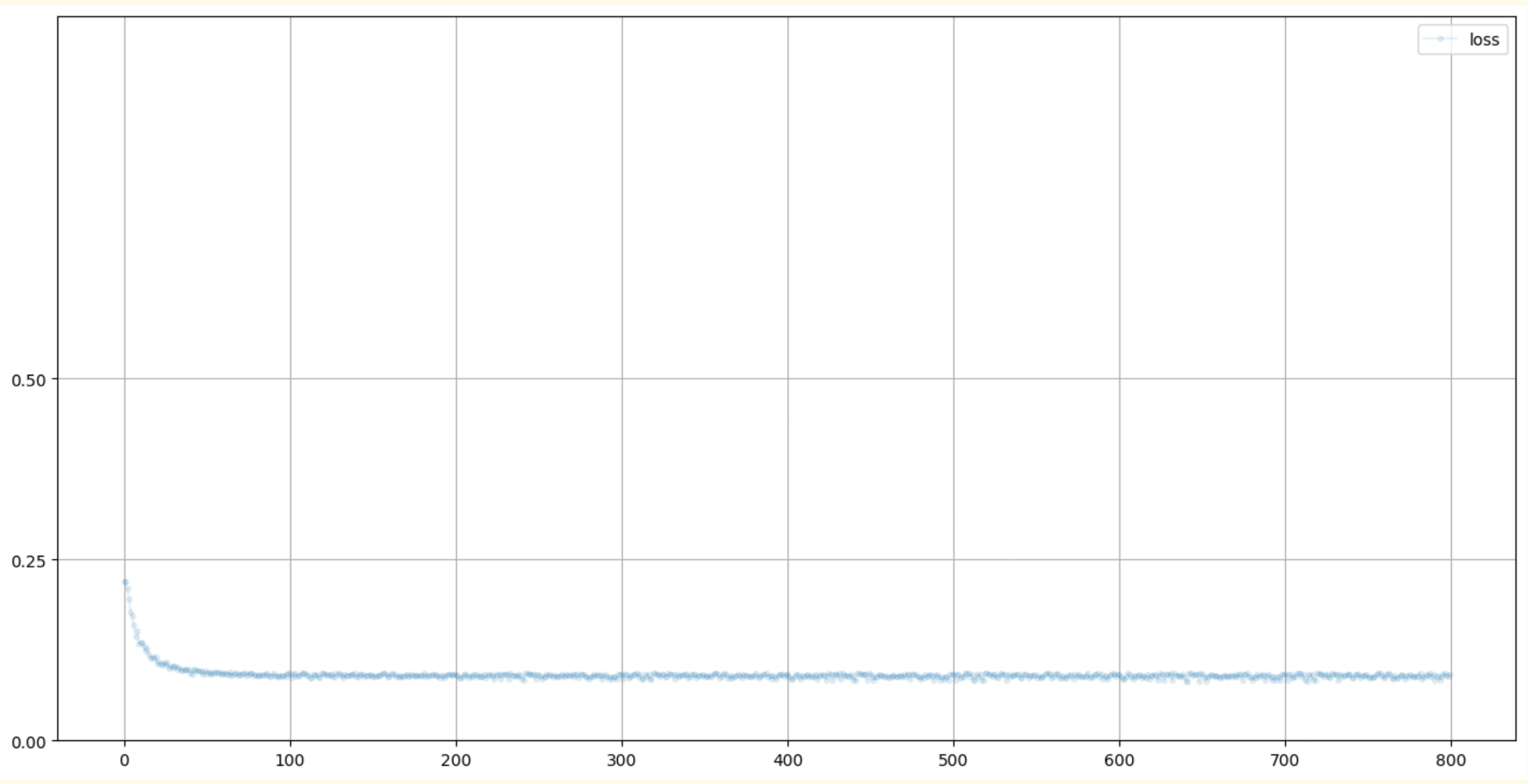
损失图真的很实用,它让我们了解到网络训练是否有效。它也告诉我们训练是平稳的,还是不稳定的、混乱的。
MNIST数据集类
PyTorch使用torch.utils.data.DataLoader实现了一些实用的功能,比如自动打乱数据顺序、多个进程并行加载、分批处理等,需要先将数据载入一个torch.utils.data.Dataset对象。
1.3 改良方法
损失函数
有时候,我们会把一些神经网络的输出值设计为连续范围的值。例如,一个预测温度的网络会输出0~100℃的任何值。
也有时候,我们会把网络设计成输出true/false或1/0。例如,我们要判断一幅图像是不是猫,输出值应该尽量接近0.0或1.0,而不是介于两者之间。
如果我们针对不同情况设计损失函数,会发现均方误差只适用于第一种情况。有的读者可能知道这是一个回归(regression)任务,不过不知道也没关系。
对于第二种情况,也就是一个分类(classification)任务,更适合使用其他损失函数。一种常用的损失函数是二元交叉熵损失 (binary cross entropy loss),它同时惩罚置信度(confidence)高的错误输出和置信值低的正确输出。PyTorch将其定义为nn.BCELoss()
激活函数
改良方法
标准化
神经网络中的权重和信号(向网络输入的数据)的取值范围都很大。之前,我们看到较大的输入值会导致饱和,使学习变得困难。
大量研究表明,减少神经网络中参数和信号的取值范围,以及将均值转换为0,是有好处的。我们称这种方法为标准化 (normalization)
一种常见的做法是,在信号进入一个神经网络层之前将它标准化。
1.4 CUDA基础知识
学习要点:
● GPU包含许多计算内核,能以高度并行的方式运行一些计算。最初,它们被设计用来加速计算机图形计算,现在越来越多地被用于加速机器学习计算。
● CUDA是NVIDIA针对GPU加速计算而开发的编程框架。通过PyTorch可以很方便地使用CUDA,无须过多地改变代码。
● 在简单的基准测试中,如矩阵乘法,GPU的速度超过CPU150倍。
● 在单个计算上,GPU可能比CPU慢。这是因为在CPU之间和在GPU之间的数据传送同样耗时。如果数据量不足以分配给多个内核,GPU的优势便无法得到发挥。
numpy与Python的比较
使用numpy来计算矩阵乘法,可以避免在Python的下层软件中操作矩阵值。numpy可以直接在内存中存储矩阵值。同时,numpy会尝试使用CPU的特殊功能,例如并行计算,而不是一个接一个地逐个计算。
NVIDIA CUDA
与通用的CPU不同,GPU是专门针对一些特定任务而设计的。其中一个就是数值计算,包括以高度并行化的方式实现矩阵乘法。
下图解释了CPU和GPU的主要区别:
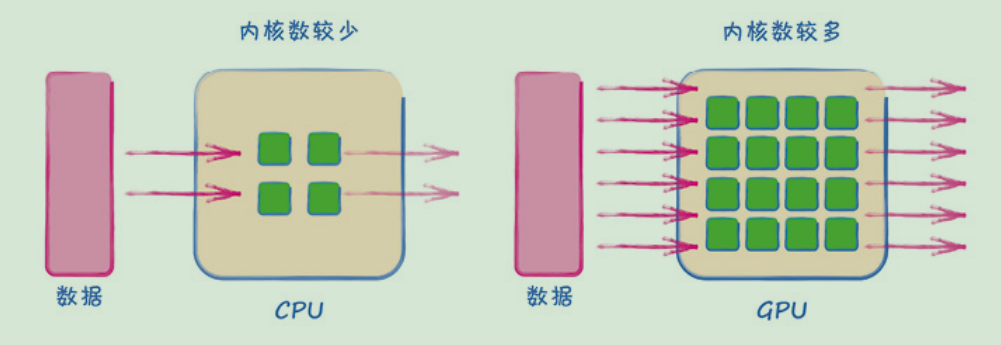
如果要进行很多计算,CPU需要一个接一个地运行。现代CPU可能会用到2或4个甚至8或16个内核来进行计算。最近,最强大的消费级CPU已经配备了64个内核。
GPU配备了更多计算内核,普遍有上千个。这意味着一个负荷较大的任务可以被分割并分配给所有内核,进而大大缩短整个任务的完成时间
在很长一段时间里,英伟达(NVIDIA)的GPU市场份额一直保持领先。同时,它也是机器学习研究标准的制定者之一。因为他们有一套成熟的软件工具,可以充分利用硬件加速。这套软件框架就是CUDA
CUDA的缺点在于,它只适用于NVIDIA的GPU,造成了我们在硬件选择上的局限性。NVIDIA的竞争对手是AMD,而后者才刚刚开始针对自己的GPU研发类似的框架。不久之后,可能会出现一个跨平台的标准并得到普及。但是,现在我们必须同时使用NVIDIA和CUDA。
安装CUDA
桌面右键打开英伟达控制面板,点击帮助->系统信息->组件
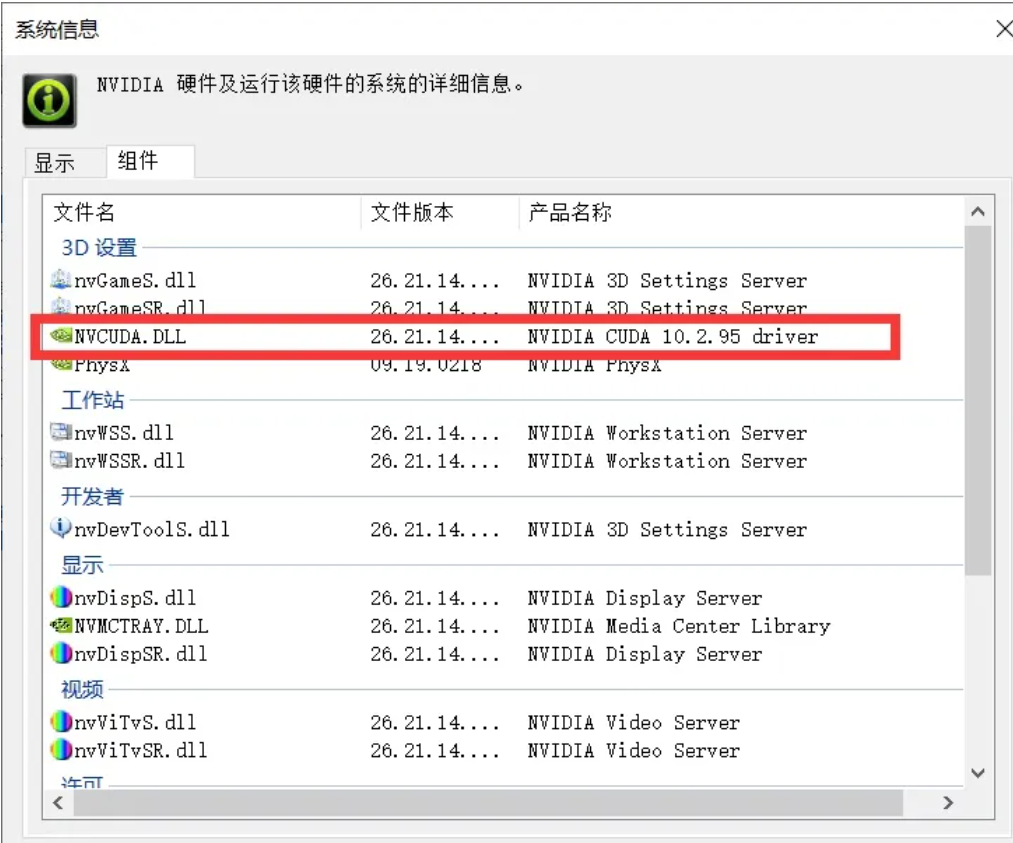
可以看到本机支持的是CUDA 10.2 版本,表示是不支持更高版本的。如果你升级了驱动,可能会支持更高版本,也可能不会提升。
所以就必须安装 10.2 及以下的版本。
安装PyTorch
PyTorch有两种主要版本:一种是支持 CUDA 的版本,另一种是不支持 CUDA(即CPU版本)的版本。这两种版本针对不同的硬件设备和需求。
- CUDA 版本: 这个版本的 PyTorch 是为了在支持 NVIDIA GPU 的系统上利用 CUDA 进行加速而设计的。CUDA 版本的 PyTorch 支持在 GPU 上执行计算,能够大幅提升训练神经网络的速度。要使用 CUDA 版本的 PyTorch,你需要确保你的系统有支持 CUDA 的 NVIDIA GPU,并且安装了相应的 NVIDIA 驱动和 CUDA 工具包。
- CPU 版本: 这个版本的 PyTorch 是为了在不支持 CUDA 或者不想使用 GPU 加速的系统上运行而设计的。CPU 版本的 PyTorch将所有计算都放在 CPU 上进行,因此在不需要 GPU 加速的情况下是一个很好的选择。
安装CPU版本的PyTorch(不支持CUDA)
pip install torch==1.9.1+cpu torchvision==0.10.1+cpu torchaudio===0.9.1 -f https://download.pytorch.org/whl/torch_stable.html安装特定版本的PyTorch(支持CUDA)
假设你需要安装支持 CUDA 10.2 的 PyTorch 版本:
pip install torch==1.9.1+cu102 torchvision==0.10.1+cu102 torchaudio===0.9.1 -f https://download.pytorch.org/whl/torch_stable.html在这个示例中,cu102 表示 CUDA 10.2 版本,你可以根据你的CUDA版本选择相应的版本号。此外,torchvision和torchaudio的版本号应与安装的torch版本匹配。
查看PyTorch版本信息
import torch
print(torch.__version__)
print(torch.version.cuda) # 打印 CUDA 版本
print(torch.cuda.is_available()) # 检查 CUDA 是否可用在Python中使用CUDA
# create tensor on GPU
x = torch.cuda.FloatTensor([3.5])
x.type()
# check tensor is on GPU
x.device
# 用gpu计算矩阵乘法
size = 600
a = numpy.random.rand(size, size)
b = numpy.random.rand(size, size)
# create cuda tensors from numpy arrays
aa = torch.cuda.FloatTensor(a)
bb = torch.cuda.FloatTensor(b)
cc = torch.matmul(aa, bb)
# Standard CUDA Check And Set Up
# check if CUDA is available. if yes, set default tensor type to cuda
if torch.cuda.is_available():
torch.set_default_tensor_type(torch.cuda.FloatTensor)
print("using cuda:", torch.cuda.get_device_name(0))
pass
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
device二、GAN初步
2.1 GAN的概念
学习要点:
● 分类是对数据的简化。分类神经网络把较多的输入值缩减成很少的输出值,每个输出值对应一个类别。
● 生成是对数据的扩展。一个生成神经网络将少量的输入种子值扩展成大量的输出值,例如图像像素值。
● 生成对抗网络(GAN)由两个神经网络组成,一个是生成器,另一个是鉴别器,它们被设计为竞争对手。鉴别器经过训练后,可将训练集中的数据分类为真实数据,将生成器产生的数据分类为伪造数据;生成器在训练后,能创建可以以假乱真的数据来欺骗鉴别器。
● 成功地设计和训练GAN并不容易。因为GAN的概念还很新,描述其工作原理以及为什么会训练失败的基本理论尚未成熟。
● 标准的GAN训练循环有3个步骤。(1)用真实的训练数据集训练鉴别器;(2)用生成的数据训练鉴别器;(3)训练生成器生成数据,并使鉴别器以为它是真实数据。
生成图像
通常情况下,我们使用神经网络来减少、提取、总结信息。MNIST分类器就是一个很好的例子。它有784个输入值,但只有10个输出值,输出值数量远小于输入值数量。
让我们做一个思维实验。如果把一个神经网络的输入与输出反转,应该能够实现与“减少”相反的功能。换句话说,可以把较少的数据扩展成更多的数据。这样一来,我们就得到了图像数据。
这并不是天方夜谭。在《Python神经网络编程》中,我们将一个数字,通过一个训练好的网络向后传播,以生成该数字的某种理想化图像。我们把这个过程称为反向查询(backquery)。
我们发现,由反向查询创建的图像具有以下特征:
● 在数字相同的情况下,生成的图像总是相同的;
● 它们是有标签的训练数据的像素平均值。
能够用网络来生成图像已经很不错了,但理想的情况应该是:
● 网络可以生成不同的图像;
● 生成的图像看起来像训练数据中的一个样本,而不是数据集的平滑平均值。
对抗训练
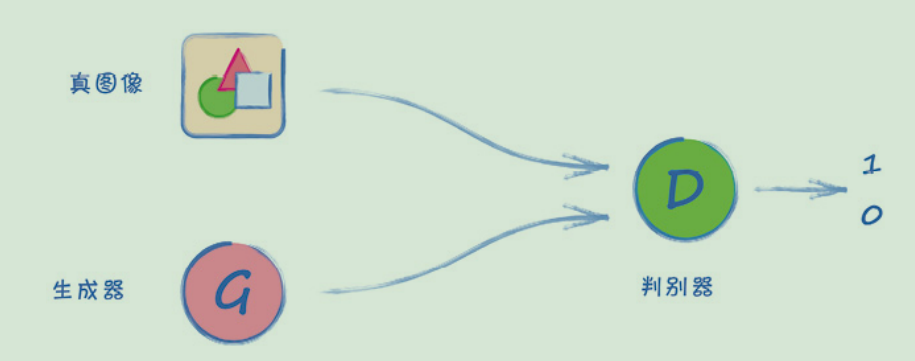
鉴别器和生成器是竞争对手(adversary)关系,双方都试图超越对方,并在这个过程中逐步提高。我们称这种架构为生成对抗网络 (Generative Adversarial Network,GAN)
这是一个非常巧妙的设计,不仅因为它利用竞争来驱动进步,也因为我们不需要定义具体的规则来描述要编码到损失函数中的真实图像。机器学习的历史告诉我们,我们并不擅长定义这样的规则。相反,我们让GAN自己来学习什么是真正的图像。
GAN的训练
在GAN的架构中,生成器和鉴别器都需要训练。我们不希望先用所有的训练数据训练其中任何一方,再训练另一方。我们希望它们能一起学习,任何一方都不应该超过另一方太多。
下面的三步训练循环是实现这一目标的一种方法。
● 第1步——向鉴别器展示一个真实的数据样本,告诉它该样本的分类应该是1.0。
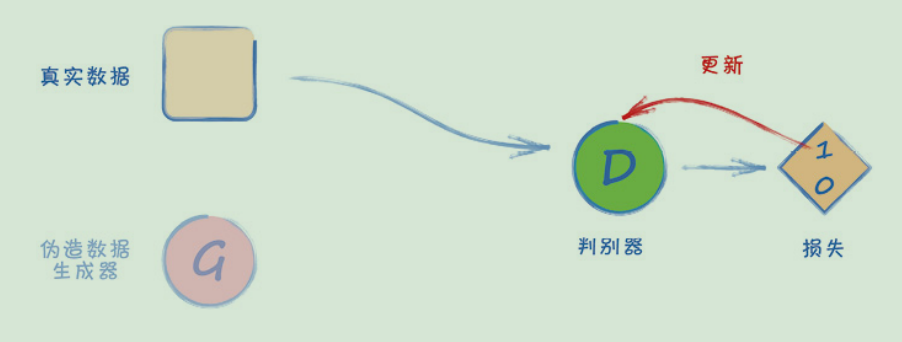
● 第2步——向鉴别器显示一个生成器的输出,告诉它该样本的分类应该是0.0。

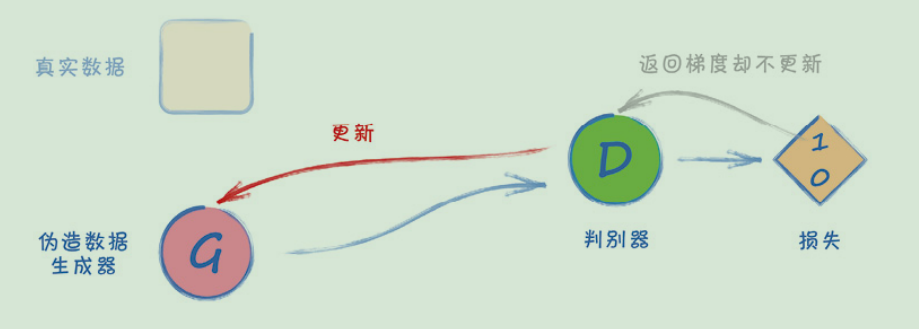
● 第3步——向鉴别器显示一个生成器的输出,告诉生成器结果应该是1.0。
训练GAN的挑战
刚才,我们讲解了GAN的原理。在现实中,训练GAN可能很困难。如果我们把生成器和鉴别器对立起来,不难发现,只有当它们之间达到微妙的平衡时,它们才会互相提高。如果鉴别器进步得太快,生成器可能永远也追不上。另一方面,如果鉴别器的学习速度太慢,生成器则会因为不断生成质量较差的图像而受到奖励。
2.2 生成1010格式规律
构建一个GAN,用生成器学习创建符合1010格式规律的值。这个任务比生成图像要简单。通过这个任务,我们可以了解GAN的基本代码框架,并实践如何观察训练进程。完成这个简单的任务有助于我们为接下来生成图像的任务做好准备。
学习要点:
● 构建和训练GAN的推荐步骤:(1)从真实数据集预览数据;(2)测试鉴别器至少具备从随机噪声中区分真实数据的能力;(3)测试未经训练的生成器能否创建正确格式的数据;(4)可视化观察损失值,了解训练进展。
● 一个成功训练的GAN的鉴别器无法分辨真实的和生成的数据。因此,它的输出应该是介于0.0~1.0,也就是0.5。理想的均方误差损失是0.25。
● 分别可视化并观察鉴别器和生成器的损失是非常有用的。生成器损失是鉴别器在判断生成数据时产生的损失。
真实数据源
# function to generate real data
def generate_real():
real_data = torch.FloatTensor(
[random.uniform(0.8, 1.0),
random.uniform(0.0, 0.2),
random.uniform(0.8, 1.0),
random.uniform(0.0, 0.2)])
return real_data
# function to generate uniform random data
def generate_random(size):
random_data = torch.rand(size)
return random_data构建鉴别器
import torch
import torch.nn as nn
import pandas
import matplotlib.pyplot as plt
import random
import numpy
# discriminator class
class Discriminator(nn.Module):
def __init__(self):
# initialise parent pytorch class
super().__init__()
# define neural network layers
self.model = nn.Sequential(
nn.Linear(4, 3),
nn.Sigmoid(),
nn.Linear(3, 1),
nn.Sigmoid()
)
# create loss function
self.loss_function = nn.MSELoss()
# create optimiser, simple stochastic gradient descent
self.optimiser = torch.optim.SGD(self.parameters(), lr=0.01)
# counter and accumulator for progress
self.counter = 0;
self.progress = []
pass
def forward(self, inputs):
# simply run model
return self.model(inputs)
def train(self, inputs, targets):
# calculate the output of the network
outputs = self.forward(inputs)
# calculate loss
loss = self.loss_function(outputs, targets)
# increase counter and accumulate error every 10
self.counter += 1;
if (self.counter % 10 == 0):
self.progress.append(loss.item())
pass
if (self.counter % 10000 == 0):
print("counter = ", self.counter)
pass
# zero gradients, perform a backward pass, update weights
self.optimiser.zero_grad()
loss.backward()
self.optimiser.step()
pass
def plot_progress(self):
df = pandas.DataFrame(self.progress, columns=['loss'])
df.plot(ylim=(0, 1.0), figsize=(16,8), alpha=0.1, marker='.', grid=True, yticks=(0, 0.25, 0.5))
pass
pass测试鉴别器
# test discriminator can separate real data from random noise
D = Discriminator()
for i in range(50000):
# real data
D.train(generate_real(), torch.FloatTensor([1.0]))
# fake data
D.train(generate_random(4), torch.FloatTensor([0.0]))
pass
D.plot_progress()
# 具体验证两个实例
print( D.forward( generate_real() ).item() )
print( D.forward( generate_random(4) ).item() )构建生成器
生成器的隐藏层应该有多大? 输入层呢? 我们不需要局限于一个特定的大小,不过这个大小应该足以学习。但也不要太大,因为训练很大的网络需要花很长时间。同时,我们需要配合鉴别器的学习速度。因为我们不希望生成器和鉴别器中的任何一个领先另一个太多。基于这些考量,许多人从复制鉴别器的构造入手来设计生成器。
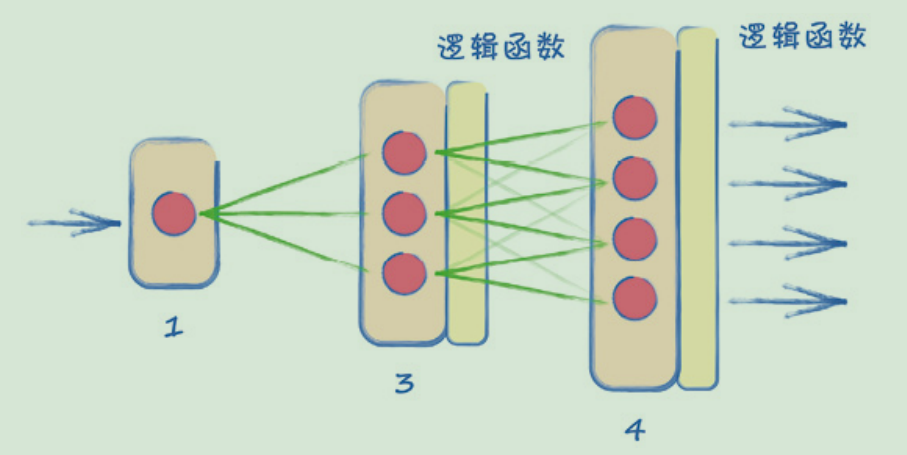
# generator class
class Generator(nn.Module):
def __init__(self):
# initialise parent pytorch class
super().__init__()
# define neural network layers
self.model = nn.Sequential(
nn.Linear(1, 3),
nn.Sigmoid(),
nn.Linear(3, 4),
nn.Sigmoid()
)
# create optimiser, simple stochastic gradient descent
self.optimiser = torch.optim.SGD(self.parameters(), lr=0.01)
# counter and accumulator for progress
self.counter = 0;
self.progress = []
pass
def forward(self, inputs):
# simply run model
return self.model(inputs)
def train(self, D, inputs, targets):
# calculate the output of the network
g_output = self.forward(inputs)
# pass onto Discriminator
d_output = D.forward(g_output)
# calculate error
loss = D.loss_function(d_output, targets)
# increase counter and accumulate error every 10
self.counter += 1;
if (self.counter % 10 == 0):
self.progress.append(loss.item())
pass
# zero gradients, perform a backward pass, update weights
self.optimiser.zero_grad()
loss.backward()
self.optimiser.step()
pass
def plot_progress(self):
df = pandas.DataFrame(self.progress, columns=['loss'])
df.plot(ylim=(0, 1.0), figsize=(16,8), alpha=0.1, marker='.', grid=True, yticks=(0, 0.25, 0.5))
pass
pass这里没有使用self.loss_function,因为我们不需要它了。回顾GAN的训练循环,我们使用的唯一的损失函数是根据鉴别器的输出计算的。最后,我们根据由鉴别器损失值计算的误差梯度来更新生成器。
因此,训练生成器也需要鉴别器的损失值。实现这一关系的编码方法有多种。一种简单的方法是将鉴别器传递给生成器的train()函数。这样可以保持训练循环代码的整洁。
检查生成器输出
# check the generator output is of the right type and shape
G = Generator()
G.forward(torch.FloatTensor([0.5]))训练GAN
# create Discriminator and Generator
D = Discriminator()
G = Generator()
image_list = []
# train Discriminator and Generator
for i in range(10000):
# train discriminator on true
D.train(generate_real(), torch.FloatTensor([1.0]))
# train discriminator on false
# use detach() so gradients in G are not calculated
D.train(G.forward(torch.FloatTensor([0.5])).detach(), torch.FloatTensor([0.0]))
# train generator
G.train(D, torch.FloatTensor([0.5]), torch.FloatTensor([1.0]))
# add image to list every 1000
if (i % 1000 == 0):
image_list.append( G.forward(torch.FloatTensor([0.5])).detach().numpy() )
pass
D.plot_progress()
G.plot_progress()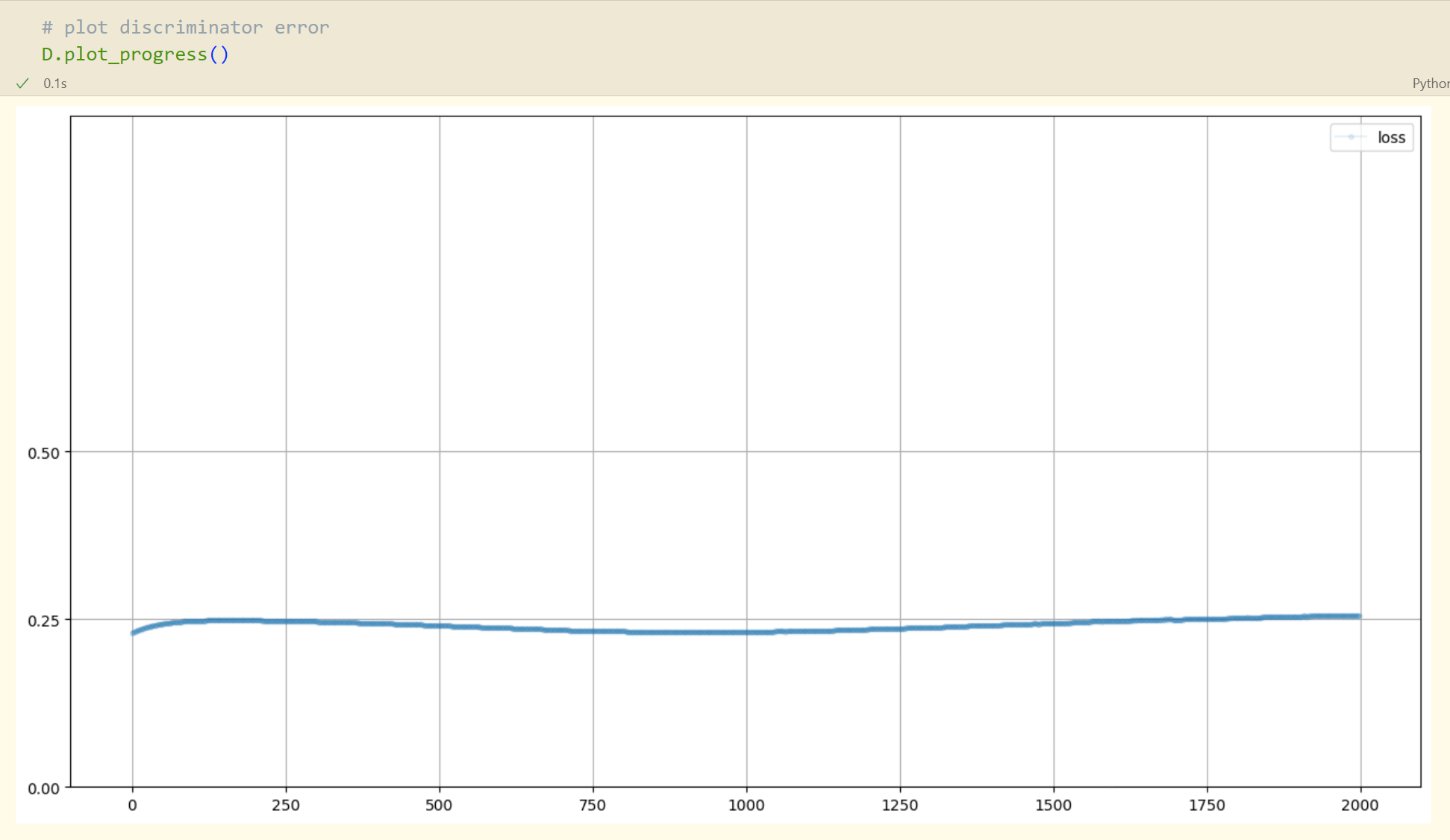
在这里,随着训练的进行,损失值略有下降,但幅度并不大。这说明网络有了一些进步。目前还不清楚,它是在识别真实的1010格式规律方面做得更好,还是在识别生成的伪造数据方面做得更好,或者两方面都很出色。在训练的后期,损失值回升到0.25。这是一个好现象,说明生成器已经学会生成1010格式的数据,从而使鉴别器无法区分。换句话说,鉴别器的输出是0.5,介于0~1。这也正是损失值反弹到0.25的原因。
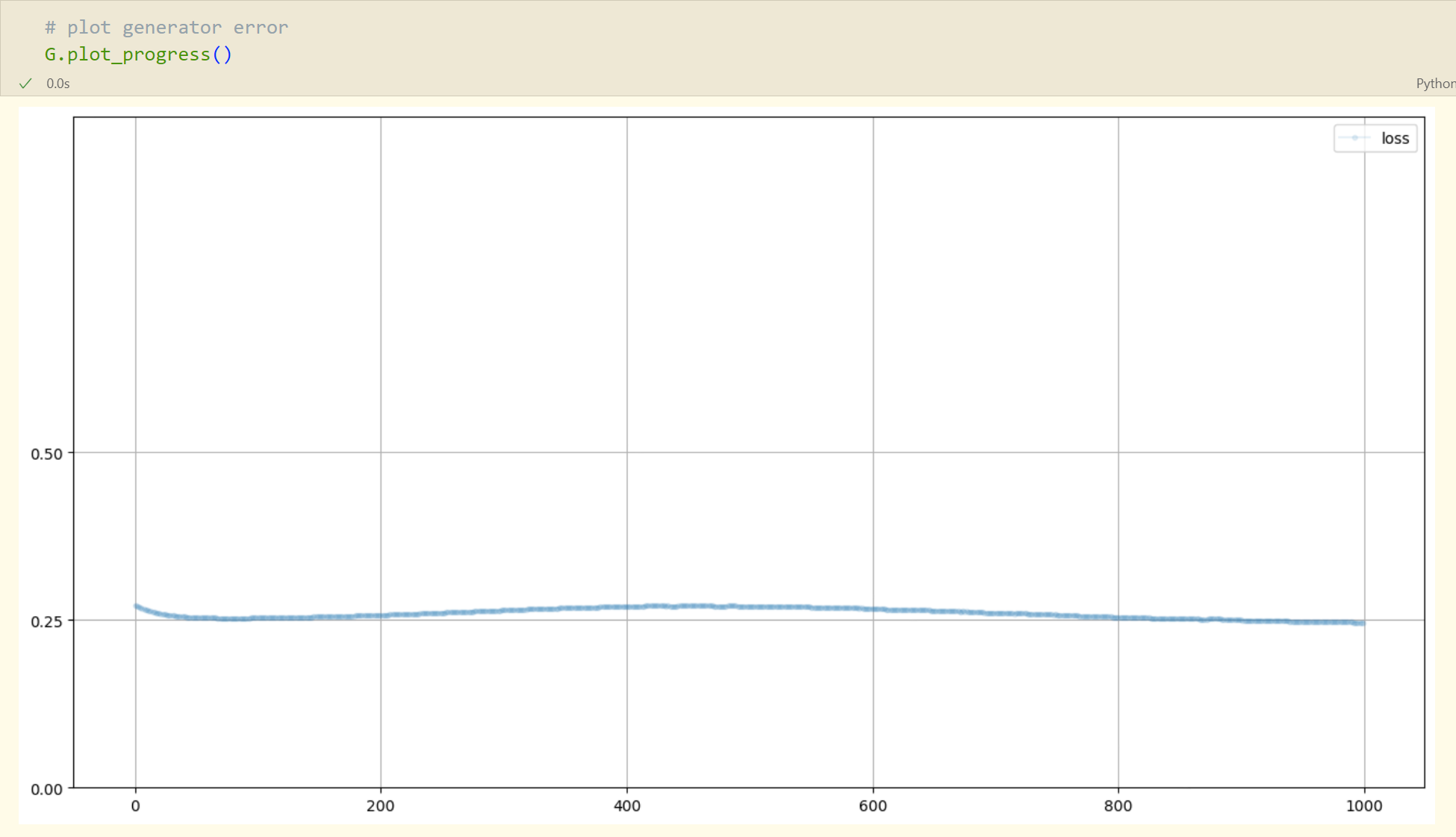
刚开始,鉴别器在区分真假模式时并不是很确定。在训练进行到一半时,损失值略有增加,这表明生成器在进步,开始可以骗过鉴别器了。在训练后期,我们看到生成器和鉴别器达到平衡
通过观察训练过程中的损失值变化来了解训练的进展是一个好习惯。
从上面的两个图中,我们看到训练没有完全失败,也没有看到损失值的剧烈振荡,那是学习不稳定的一种表现。
2.3 生成手写数字
学习要点:
● 处理单色图像不需要改变神经网络的设计。将二维像素数组简单地展开或重构成一维列表,即可输入鉴别器的输入层。如何做到这一点并不重要,不过要注意保持一致性。
● 模式崩溃是指一个生成器在有多个可能输出类别的情况下,一直生成单一类别的输出。模式崩溃是GAN训练中最常见的挑战之一,其原因和解决方法尚未被完全理解,因此是一个相当活跃的研究课题。
● 着手设计GAN的一个很好开端是,镜像反映生成器和鉴别器的网络架构。这样做的目的是,尽量使它们之间达到平衡。在训练中,其中一方不会领先另一方太多。
● 实验证据表明,成功训练GAN的关键是质量,而不仅仅是数量。
● 生成器种子之间的平滑插值会生成平滑的插值图像。将种子相加似乎与图像特征的加法组合相对应。不过,种子相减所生成的图像并不遵循任何直观的规律。
● 理论上,一个经过完美训练的GAN的最优MSE损失(均方误差损失)为0.25,最优BCE损失(二元交叉熵损失)为ln 2或0.693。
数据类
MNIST鉴别器
测试鉴别器
MNIST生成器
检查生成器输出
训练GAN
模式崩溃
之前生成的这些图像都是相同的,在GAN训练中非常常见,我们称它为模式崩溃(mode collapse)
在MNIST的案例中,我们希望生成器能够创建代表所有10个数字的图像。当模式崩溃发生时,生成器只能生成10个数字中的一个或部分数字,无法达到我们的要求。
发生模式崩溃的原因尚未被完全理解。许多相关的研究正在进行中,我们选取其中一些相对比较成熟的理论进行讨论。
其中一种解释是,在鉴别器学会向生成器提供良好的反馈之前,生成器率先发现一个一直被判定为真实图像的输出。为此,有人提出一些解决方案,比如更频繁地训练鉴别器。但在实践中,这样做往往效果不佳。这就表明,解决问题的关键不仅在于训练的数量,也在于训练的质量。
改良GAN的训练
- 第一个改良是,使用二元交叉熵BCELoss()代替损失函数中的均方误差MSELoss()。我们在1.3.1节讨论过,在神经网络执行分类任务时,二元交叉熵更适用。相比于均方误差,它更大程度地奖励正确的分类结果,同时惩罚错误的结果。
- 下一个改良是,在鉴别器和生成器中使用LeakyReLU()激活函数。因为我们所预期的输出值范围为0~1,所以我们只会在中间层后使用LeakyReLU(),最后一层仍保留S型激活函数。我们在1.3.2节已经讨论过LeakyReLU()如何解决梯度消失问题
- 另一种改良是,将神经网络中的信号进行标准化,以确保它们的均值为0。同时,标准化也可以有效地限制信号的方差,避免较大值引起的网络饱和。
经过上面的改良后:模式崩溃仍然存在。图像的清晰度有所提高,结构更清晰了,但仍然不是一个清楚的数字
让我们更深入地思考一下如何进一步改良GAN。
生成过程的起始点是一个种子值。起初,我们用常数值0.5。随后,我们把它改为一个随机值,因为我们知道,对于固定的输入,任何神经网络总会输出相同的结果。也许生成器神经网络觉得,把一个单值转换成784像素来代表一个数字实在太难了
如果我们继续思考,不难想到输入生成器的随机种子和输入鉴别器的种子,不应该是一样的。
● 输入鉴别器的随机图像的像素值,需要在0~1的范围内均匀抽取(uniformly chosen)。这个范围对应真实数据集中图像像素的范围。因为目前的测试是将鉴别器的性能与随机判断进行对比,所以这些值应该是均匀抽取的,而不是从有偏差的正态分布中抽取。
● 输入生成器的随机值不需要符合0~1的范围。我们知道,标准化一个网络中的信号有助于训练。标准化后的信号会集中在0附近,且方差有限。我们在《Python神经网络编程》中初始化网络链接权重时具体讨论过。这时,从一个平均值为0、方差为1的正态分布中抽取种子更加合理。
种子实验
生成器种子之间的平滑插值会生成平滑的插值图像。将种子相加似乎与图像特征的加法组合相对应。不过,种子相减所生成的图像并不遵循任何直观的规律。
2.4 生成人脸图像
与生成单色的手写数字图像相比,我们将面临以下两个全新的挑战。
● 使用彩色图像作为训练数据,并学习生成全彩色图像。
● 训练数据集中的图像更加多样化,也包含更多容易使人分心的细节
学习要点:
● 颜色可以用红、绿、蓝三种色光表示。因此,彩色图像常被表示为3层像素值的数组,每层对应三原色之一,且大小为(长,宽,3)。
● 在处理由多个文件组成的数据集时,逐个读取和关闭每个文件的方法效率很低,特别是在虚拟环境中。一种推荐的做法是,将数据重新包装成一种为方便频繁、随机访问大量数据而设计的格式。成熟的HDF格式是科学计算中常见的格式。
● 一个GAN不会记忆训练数据中的样本,也不会复制和粘贴训练样本中的元素。它学习的是训练数据中特征的概率分布,并生成与训练数据看似来自同一分布的数据
CelebA图像数据集
我们可以使用流行的CelebA数据集,其中包含202 599幅名人脸部的图像。所有图像都经过对齐和裁剪,使眼睛和嘴巴在图像中的大概位置居中
分层数据格式
为了提高读取性能,我们可以将数据打包成另外一种格式,以便更有效地支持这种重复读取。我们将使用一种名为HDF5的压缩格式。
分层数据格式(hierarchical data format)是一种成熟、开源的压缩数据格式,专门用于存储非常大量的数据,并实现对数据的高效读取。它被普遍应用于科学计算和工程领域中。之所以称它为分层数据格式,是因为一个HDF5文件可以包含一个或多个组,每个组内又包含一个或多个数据集,甚至包含更多的组。这种管理数据的方式与我们常见的文件夹和文件之间的关系很相似。
HDF5格式和用于访问该格式数据的库有许多实用的特性,可以确保读取性能。其中之一就是通过数据压缩减少从较慢的存储器的数据传输量。其二是将数据智能地映射到较快的RAM(random access memory,随机存储器)内存中,以减少对存储器的请求量。如果没有这些功能,在Google Drive中处理成千上万幅图像文件的速度会慢得无法想象。
即使我们使用的是自己的存储设备,而不是Google Drive,也不妨尝试一下像HDF5这样的格式是否能提高机器学习的性能。尤其是那些需要重复访问大量的数据,而数据又无法被全部装进RAM的任务。
获取数据
查看数据
数据集类
鉴别器
测试鉴别器
GPU加速
生成器
检查生成器输出
训练GAN
三、卷积GAN和条件式GAN
3.1 卷积GAN
在本节中,我们将从以下两个角度出发,改良之前创建的CelebA GAN。
● 生成的图像看起来仍然比较模糊。有些我们希望色彩相当平滑的区域被高对比度的像素图案覆盖。
● 全连接的神经网络消耗大量内存。即便是中等大小的图像或网络,也会很快使GPU达到极限,以至于训练无法继续。大多数消费级GPU的内存要比谷歌Colab提供的Tesla T4或P100小得多
学习要点:
● 最先进的图像分类神经网络利用有意义的局部化特征。可识别的对象是由具有层次结构的特征构成的。低层次细节特征组成中层次特征,中层次特征本身又组成高层次对象。
● 卷积神经网络通过卷积核从一幅输入图像中生成特征图。指定的卷积核可以识别出图像中的特定图案。
● 神经网络中的卷积层可以针对具体任务学习合适的卷积核,也就是说,网络不需要我们直接设计特征,即可学到图像中最有用的特征。使用卷积层的神经网络在图像分类任务上的表现,优于同等大小的全连接网络。
● 卷积模块缩减数据,同样配置的转置卷积模块可以抵消这种缩减。因此,转置卷积是生成网络的理想选择。
● 基于卷积网络的GAN,通过将低层次特征组成中层次特征,再由中层次特征组成高层次特征来构建图像。实验表明,由卷积GAN生成的图像质量高于同等大小的全连接GAN。
● 与全连接GAN相比,卷积GAN占用的内存更少。在GPU内存受到限制时,这是处理较大大小的图像文件时需要考虑的一个因素。我们看到卷积GAN的内存使用只有全连接GAN的20%左右。
● 卷积生成器的一个缺点是,它可能生成由相互不匹配的元素组成的图像。例如,包含不同眼睛的人脸。这是因为卷积网络处理的信息是局部化的,而全局关系并没有被学习到。
内存消耗
局部化的图像特征
机器学习的黄金法则之一是,最大限度地利用任何与当前问题相关的知识。这些领域知识(domain knowledge)可以帮助我们排除不成立的选项,从而简化问题空间。这样一来,可学习参数的组合变少了,机器学习相对更容易了。
如果对图像进行进一步的思考,我们会发现,大多数有意义的特征(feature)是局部化(localised)的。例如,表示眼睛或鼻子的像素靠得很近。利用这些信息,我们可以将图像分类为人脸。我们应该设计一个神经网络,利用相邻像素群的局部特征进行分类。
在之前的MNIST分类器和CelebA分类器中,我们没有这样做,而是把图像的所有像素一起考虑。这么做也没有错。这些网络可以学习正确的链接权重,并挑选正确的特征来帮助图像分类。唯一的区别在于,利用所有像素学习的难度更大些。
卷积过滤器
学习卷积核权重
一种更好的方案是,不用提前设计卷积核,而是通过学习获得卷积核中的最佳赋值或权重。这正是包括PyTorch在内的许多机器学习框架所采取的方法。
基本上,我们只需要决定使用几个卷积核,比如20个。在训练过程中,我们会对每个卷积核内部的权重进行调整。如果训练成功,最终得到的卷积核会从图像中挑出最有代表性的细节。神经网络的其余部分将结合这些信息对图像进行分类。不是所有的卷积核都会有用,较低的链接权重会降低这些卷积核的影响。
特征的层次结构
我们刚才讲了一层卷积核如何识别出低层次特征(如边缘或斑点),并将这些信息汇总在网格中。这些网格的正式名称是特征图(feature map)
如果将另一层卷积核应用到这些特征图上,我们可以得到中层次的特征。这些特征是低层次特征的组合。比如说,斑点和边缘的正确组合可能是一只眼睛或一个鼻子。
我们可以再应用一层卷积核,得到更高层次的特征。这些特征是中层次特征的组合。眼睛和鼻子特征的正确组合,加上方向,很可能代表一张人脸。
MNIST CNN
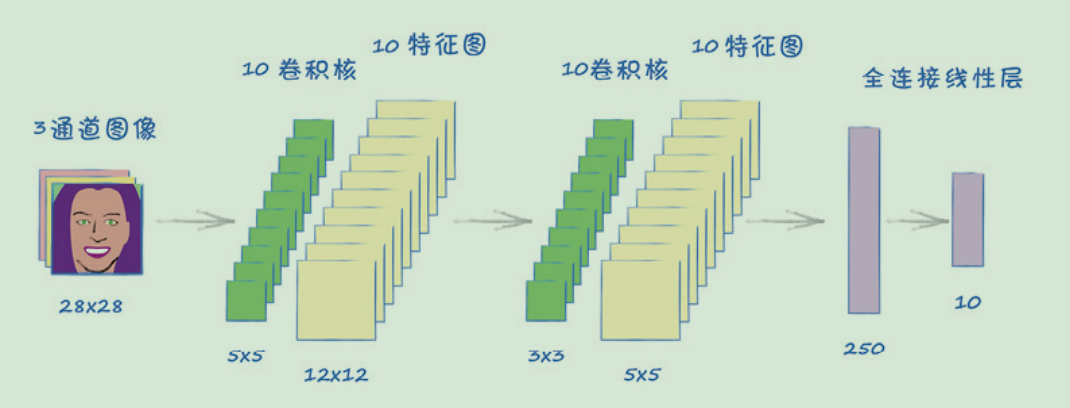
CelebA CNN
鉴别器
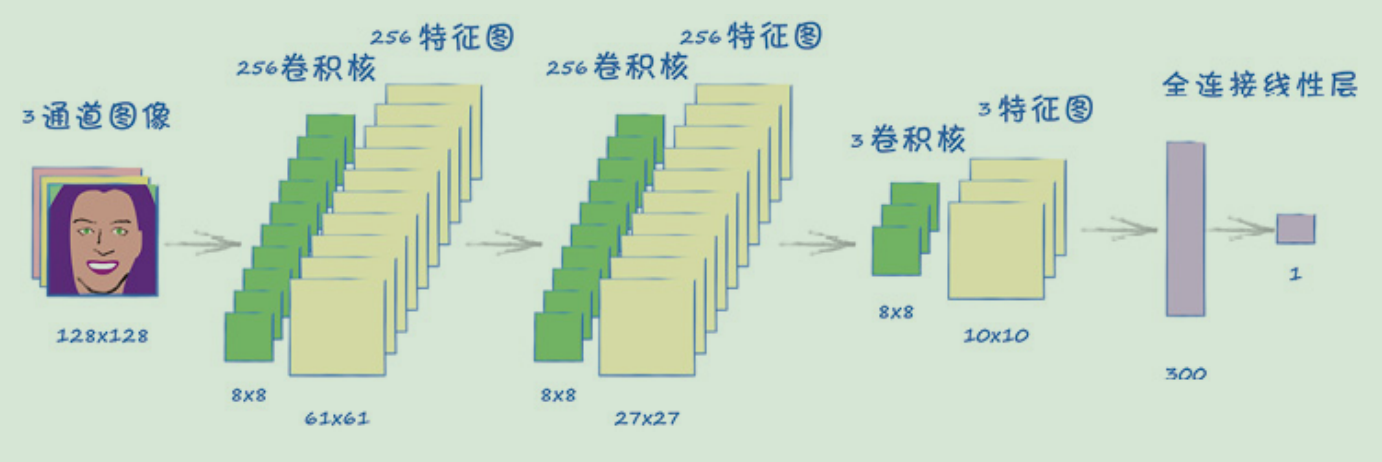
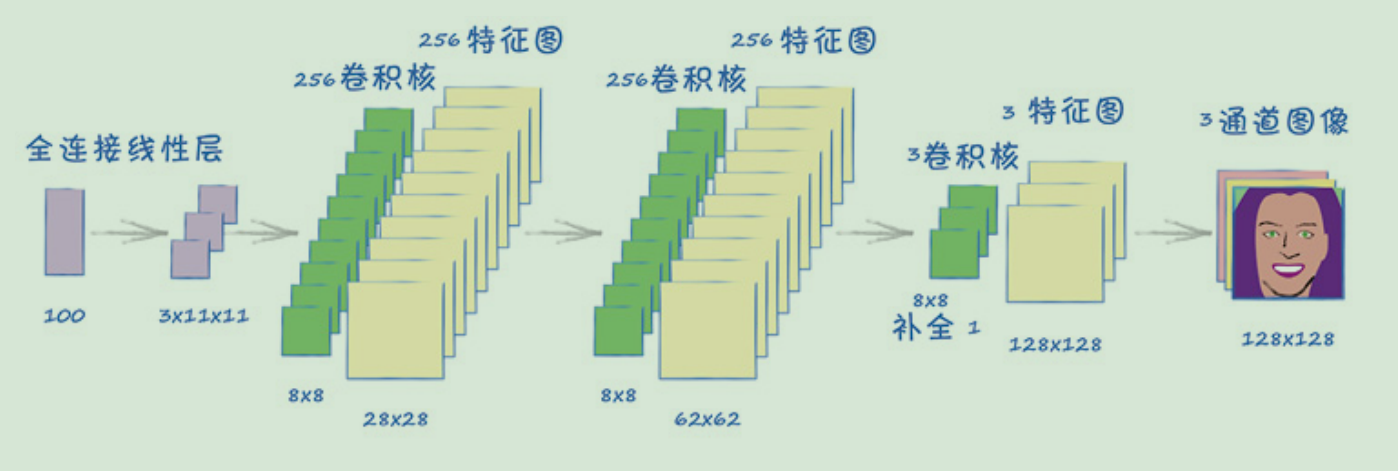
生成器
接着,让我们来思考一下生成器网络,这意味着我们的笔和纸又要派上用场了。我们将遵循一个原则,即生成器应该是鉴别器的镜像。这样一来,它们谁也不比谁强,谁也不比谁弱。
在开始画设计图时,我们可能会问,什么是卷积计算的反义词?卷积将较大的张量缩减成较小的张量,而反卷积则需要将较小的张量扩展成较大的张量。PyTorch将这种反向卷积称为转置卷积(transposed convolution),需要调用的模块是nn.ConvTranspose2d。
3.2 条件式GAN
如果能通过某种方式引导GAN生成多样化的图像,同时又仅限于生成训练数据中的一类图像,那将是非常有价值的。例如,我们可以要求GAN生成不同的、但都代表数字3的图像。又如,我们用人脸图像进行训练,如果情绪是训练数据中的一个类别,那么我们可以要求GAN只生成具有快乐表情的人脸图像
学习要点:
● 不同于GAN,条件式GAN可以直接生成特定类型的输出。
● 训练条件式GAN,需要将类别标签分别与图像和种子一起输入鉴别器和生成器。
● 由条件式GAN生成图像的质量,通常优于由不使用标签信息的同等GAN生成的图像。
条件式GAN架构
下图显示的架构是条件式(conditional)GAN。
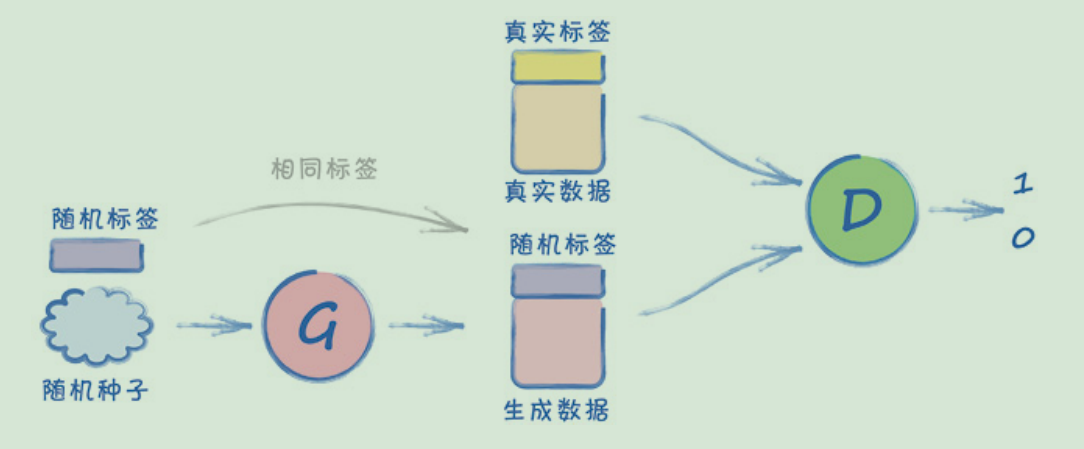
主要的改变在于,现在生成器和鉴别器的输入都在图像数据的基础上加入了类型标签。